
Summary: At the core of modern AI, particularly robotics, and sequential tasks is Reinforcement Learning. Although RL has been around for many years it has become the third leg of the Machine Learning stool and increasingly important for Data Scientist to know when and how to implement.
If you poled a group of data scientist just a few years back about how many machine learning problem types there are you would almost certainly have gotten a binary response: problem types were clearly divided into supervised and unsupervised.
- Supervised: You’ve got labeled data (clearly defined examples).
- Unsupervised: You’ve got data but it’s not labeled. See if there’s a structure in there.
Today if you asked that same question you are very likely to find that machine learning problem types are divided into three categories:

While Reinforcement Learning (RL) has been around since at least the 80’s and before that in the behavioral sciences, its introduction as a major player in machine learning reflects it rising importance in AI.
The key to understanding when to use Reinforcement Learning is this:
- Data for learning currently does not exist
- Or you don’t want to wait to accumulate it (because delay might be costly)
- Or the data may change rapidly causing the outcome to change more rapidly than a typical model refresh cycle can accommodate.
What problems fit this description? Well robotic control for one and game play for another, both a central focus of AI over the last few years.
To drastically simplify, RL methods are deployed to address two problem types:
- Prediction: How much reward can be expected for every combination of possible future states. (E.g. how much can we hope to collect from delinquent accounts based on the following set of steps?)
- Control: By moving through all possible combinations of the environment (interacting with the environment or state space) find a combination of actions (a ‘policy’ in RL-speak) that maximizes reward and allows for action planning and optimal control. (E.g. How to steer an autonomous vehicle, or how to win a game of chess.)
We’ll offer some additional examples to clarify this, but you should immediately perceive the confusion created by introducing this third ML type. The distinction between Supervised and Unsupervised problem types was immediately clear by both the problem definition and the data that is available.
RL on the other hand is defined by the absence of pre-existing data, but has goals that could also be addressed by Supervised or Unsupervised techniques as well if you first gathered training data. For example, value prediction is clearly also in the realm of Supervised problems, and some Control problems that focus on optimized outcomes can also be answered with Supervised or even Unsupervised techniques.
 Origins of Reinforcement Learning
Origins of Reinforcement Learning
The concepts underlying RL come from animal behavior studies. One of the most commonly used examples is that of the new-born baby gazelle. Although it is born without any understanding or model of how to use its legs, within minutes it is standing and within 20 minutes it is running. This learning has come from rapidly interacting with its environment, learning which muscle responses are successful, and being rewarded by survival.
RL Basic Concepts
RL is exactly that: a system in which success is learned by interacting with its environment through trial and error. Contrasted to supervised and unsupervised learning which both have data on which to learn, RL is making its own data through experience and determining the ‘champion model’ through trial and error, and pure reinforcement. RL agents learn from their own experience, contrasted to Supervised learners which have examples from which to learn
The basic idea behind RL is simplicity itself.
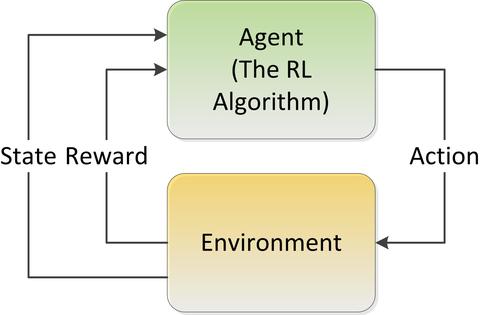
- The ‘Environment’ is understood to be the matrix of all possible alternative values or steps that can be taken. (Think possible moves of all pieces in a game of checkers or all the possible steering corrections an autonomous steering mechanism could take in response to visual sensor input of the road ahead).
- The ‘Agent’ is the RL algorithm. There’s not just one, there are many types.
- The Agent begins to randomly explore alternative actions in the Environment and reinforces the Agent when the moves are successful.
- The ‘State’ is the current set of moves or values which is modified after each try and seeks to optimize the reward via the feedback loop.
- The Agent must learn from its experiences of the Environment as it explores the full range of possible States.
- The resulting solution or algorithm is called a ‘Policy’. The Policy is intended to be the set of steps or procedures that result in optimizing the reward.
Example Problems
Some additional examples of problems where RL is a good choice.
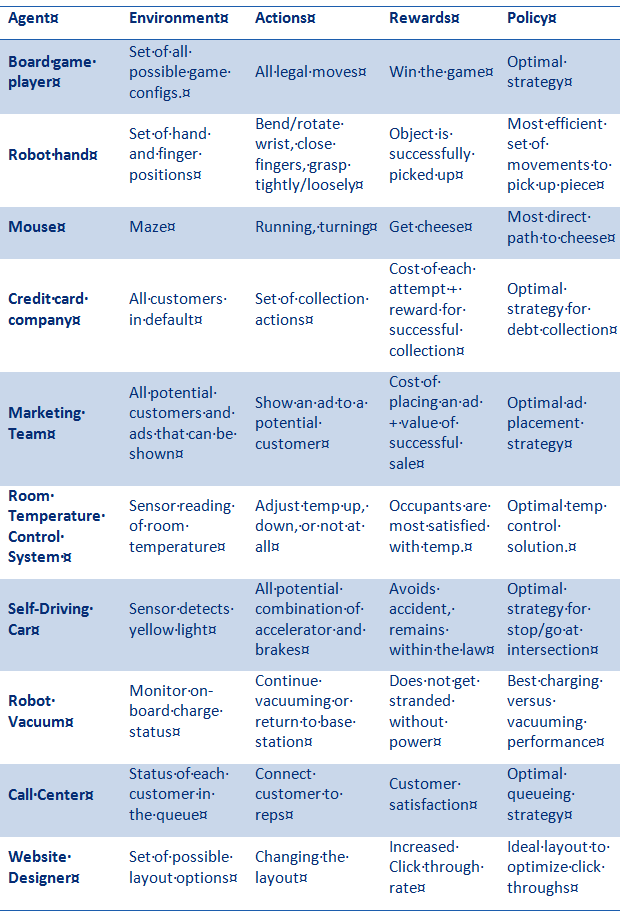
Overlap With Supervised Learning and Some RL Strategies
In the table above look specifically at the ‘Marketing Team’ and ‘Website Designer’ examples and you should recognize problems where classical A/B testing or a supervised classification problem to detect best prospects have been the historical go-to solutions. Both these would require running tests to gather training data, then modeling and applying results. Similarly, many of the other problems would yield to supervised or unsupervised modeling if training data were available.
Consider the A/B test for example. The RL practitioner would say “Why wait for training data? Let’s just start showing options (probably more than just A and B) to customers and continue to show the ones that get the best results.”
This in fact is the core of the RL strategy with this exception. If we allow the agent to settle in too quickly on what appears to be the winning solution it may never explore all the other options (the full extent of the State space). This may result in overfitting or an early hang up on a local optima.
To minimize this likelihood, in designing the RL agent we should use ‘a greedy Theta (Ɵ’). This factor tells the agent at what rate to continue to look randomly in the State space for a better solution. Set it too high and the system may take too long to optimize. Set it too low, the system may never examine some of the State space. (For more on this see Multi-Armed Bandits and Markov Decision Process).
Four Problems that RL Must Deal With
In the design of your RL project there are four problems you must deal with (Kevin Murphy, 1998, Florentin Woergoetter and Bernd Porr, 2008).
- The Exploration-Exploitation Tradeoff: Should we continue to explore the State space or stick with what we see is working. This issue is explored above in the A/B Tradeoff example.
- The Problem of Delayed Reward: When playing a board game the value of each move cannot be taken in a vacuum but can only be considered strong or weak in the context of whether the game was won or lost after many moves. Which move in that long sequence was actually responsible for the win or loss? Solutions to this question are in the realm of Temporal Difference Learning.
- Non-Stationary Environments: We want the Agent to interact with and learn from the Environment. But what happens if the environment changes too fast? How much weight do we give to the distant past versus the recent past? Does the change represent a discontinuity with the past? If the dynamics of the environment change slowly and continuously we’re probably OK but RL algorithms do not converge very fast. This could result in a failure even in a slowly changing environment.
- Generalization: In a large multi-dimensional State space combinatorial explosion and compute speed means that it is unlikely that we can afford to visit all of the possible options in the State space and must therefore settle for a subset. This leads to the obvious question of whether the subset is representative and whether the solution will generalize. Feature extraction and dimensionality reduction become particularly important strategies. The fact is that this curse of dimensionality is difficult to overcome in RL and makes it best suited for low dimensionality States.
All of these are areas of active research and exploration. As compute speeds grow higher and costs lower we can visit increasingly larger subsets of the State space and examine more time delay options. Many of these solutions apply principles from neural nets, back propagation, evolutionary or annealing-like procedures, and factored structures all of which reside primarily in the realms of Supervised and Unsupervised learning. This cross over of domains can be confusing but where and how to apply RL is an increasingly important body of knowledge for data scientists.
Other Articles in this Series
Under the Hood with Reinforcement Learning – Understanding Basic RL Models
Reinforcement Learning Part 3 – Challenges & Considerations
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}