
Summary: Quantum computing is already being used in deep learning and promises dramatic reductions in processing time and resource utilization to train even the most complex models. Here are a few things you need to know.
 So far in this series of articles on Quantum computing we showed that Quantum is in fact commercially available today and being used operationally. We talked about what’s available in the market now and whether it’s a good idea to get started now or wait a year, but not too long because it’s coming fast. We also talked about some of the pragmatic issues such as how do you actually program these devices and how faster they really are.
So far in this series of articles on Quantum computing we showed that Quantum is in fact commercially available today and being used operationally. We talked about what’s available in the market now and whether it’s a good idea to get started now or wait a year, but not too long because it’s coming fast. We also talked about some of the pragmatic issues such as how do you actually program these devices and how faster they really are.
Now we want to explore exactly where and how these can be used in today’s data science, and frankly to focus on Deep Learning and Artificial Intelligence. These after all are the fastest growing areas with the most technical challenges where we could use the most help.
We demonstrated that although these machines are expensive and difficult to maintain that, with IBM in the lead, these capabilities will be available via subscription and API in the cloud. Cost and complexity should not hold us back.
So What are the Best Opportunities?
At the head of most lists describing the best commercial opportunities for Quantum are these:
Supply Chain: Quantum will be able to resolve the classical traveling salesman problems no matter how massive and complex the system to optimize elements like fleet operations.
Cybersecurity: In our previous articles we described the work by Temporal Defense Systems using Quantum to identify cyber threats not previously possible.
Financial Services: Between enhanced security for the privacy of information and the ability to run complex risk models continuously, this sector is expected to be among the first in line.
Complex Systems Analysis: Lockheed Martin and their spinoff QRA are already using Quantum to discover flaws in massive software programs which to the Quantum computer are nothing more than hugely complex systems.
Deep Learning and Artificial Intelligence: This brings us back to our real focus. How Quantum can be used to dramatically enhance and speed up not just Convolutional Neural Nets for image processing and Recurrent Neural Nets for language and speech recognition, but also the frontier applications of Generative Adversarial Neural Nets and Reinforcement Learning.
While supply chain, cybersecurity, risk modeling, and complex system analysis are all important segments of data science, they don’t hold nearly the promise of what a massive improvement in Deep Learning would mean commercially.
How Do the Capabilities of Quantum Computing Align with Deep Learning?
The standard description of how Quantum computers can be used falls in these three categories:
- Simulation
- Optimization
- Sampling
While IBM Q will be able to solve problems in all three categories, D-Wave can currently only handle Optimization. Although it may not be immediately obvious, optimization is exactly what we want to handle all manner of traditional predictive modeling problems including those currently being addressed by deep learning.
When Google launched its Quantum Artificial Intelligence Lab in 2013, Hartmut Neven, Director of Engineering put it this way.
“Machine learning is highly difficult. It’s what mathematicians call an “NP-hard” problem. That’s because building a good model is really a creative act. As an analogy, consider what it takes to architect a house. You’re balancing lots of constraints — budget, usage requirements, space limitations, etc. — but still trying to create the most beautiful house you can. A creative architect will find a great solution. Mathematically speaking the architect is solving an optimization problem and creativity can be thought of as the ability to come up with a good solution given an objective and constraints.”
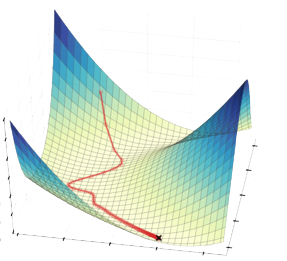 Optimization problems extend beyond the realm of traditional data science to include incredibly complex problems like protein folding or test flying space craft based on mathematical models. These are extremely complex systems with extreme numbers of interacting variables. But solving a classification or regression problem using an ANN with huge numbers of features and terabytes of observations to solve an image processing or speech or text recognition problem is the same.
Optimization problems extend beyond the realm of traditional data science to include incredibly complex problems like protein folding or test flying space craft based on mathematical models. These are extremely complex systems with extreme numbers of interacting variables. But solving a classification or regression problem using an ANN with huge numbers of features and terabytes of observations to solve an image processing or speech or text recognition problem is the same.
As Neven and others have observed, searching for the best solution among a large set of possible solutions is analogous to finding the lowest point on a landscape of hills and valleys, a technique you will immediately recognize as stochastic gradient descent. Any problem that is fundamentally resolved by a stochastic gradient descent loss function is fair game for Quantum computing in optimization mode.
Can We Make Quantum Computers Work Like Deep Neural Nets?
The answer is yes. And the reason we want to is that of the several barriers to deep learning one is simply the time and compute resources necessary to train a CNN or RNN. It can take weeks of continuous compute time on dozens or hundreds of GPUs to train complex deep nets. For example, renting 800 GPUs from Amazon’s cloud computing service for just a week would cost around $120,000 at the listed prices. With Quantum computing we should be able to reduce that to minutes or seconds using only a single device.
The D-Wave approach is based on the mathematical concept of quantum annealing, also described as adiabatic quantum computing (AQC). It’s been shown that this can be modeled by a multi-layer Restricted Boltzmann Machine, which you may recognize as one of the many types of deep learning ANNs. In fact the Center for Hybrid Multicore Productivity Research (CHMPR) has already created the largest known working Quantum deep neural net with multiple hidden layers and used it in image classification, just as we do with Convolutional Neural Nets (CNNs).
There are some important architectural differences between the way Quantum computing works and our current deep nets, particularly in the way back propagation is handled. Back prop of course is how we adjust the model after each iteration to get closer to the desired answer and it literally means applying values from the results end of the ANN back to layers at the front of the ANN before starting over again.
For deeply technical reasons (the no cloning theorem if you’re interested) we can’t apply back prop quite this way in Quantum. However, researchers have already designed an accommodation by adding additional functional hidden layers that provide the same result. To make sure we differentiate this correctly, we need to start referring to these as Quantum Neural Nets (QNNs).
Incidentally, making QNNs behave like traditional deep nets is called ‘Quantum Enhanced Learning’. This is the application of Quantum to speed up or enhance traditional machine learning methods. Yet to come is pure ‘Quantum Learning’ which will use quantum effects to yield predictive results using methods that look nothing like our current techniques.
A Little Secret Advantage for Quantum Computing in Optimization
As all of you know who have struggled with the problem of creating the ‘best’ model, we constantly have to be concerned that we haven’t become hung up on a local optima. Here’s where the ‘spooky’ characteristics of Quantum really shine.
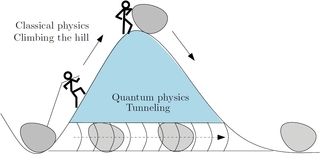 You may have heard that qubits exist as both 0 and 1 simultaneously and resolve this conflict once observed by ‘tunneling’ from one state to the next. I’m certainly not qualified to explain tunneling except that one of its really helpful characteristics is that in a quantum calculation using a neural net architecture, the Quantum computer simply ‘tunnels’ through local optima as if they weren’t there, allowing them to ‘collapse’ on a true optima.
You may have heard that qubits exist as both 0 and 1 simultaneously and resolve this conflict once observed by ‘tunneling’ from one state to the next. I’m certainly not qualified to explain tunneling except that one of its really helpful characteristics is that in a quantum calculation using a neural net architecture, the Quantum computer simply ‘tunnels’ through local optima as if they weren’t there, allowing them to ‘collapse’ on a true optima.
For those of you who are actually working in deep nets with say TensorFlow, you may be saying, slow down we thought deep nets didn’t actually have local minima. That may be true but it requires us to differentiate between shoulder points, local minima, and the ground state and that’s more than we wanted to get into here. To explore this in more depth take a look at this video from Charles Martin.
And yes, there remains the interesting question that since it’s necessary to create an early stopping point in deep nets to prevent overfitting (to actually prevent the model from achieving the ground state) then how do you do that in the context of a process that’s moving so incredibly fast.
The Issue with Accuracy
Scott Pakin of Los Alamos National Laboratory, the originator of the open source Qmasm language for simplified programming of the D-Wave reminds us that QNNs are probabilistic devices and “don’t necessarily provide the most efficient answers to an optimization problem—or even a correct one. They do however provide solutions that are ‘probably good’ if not perfect, and do it very quickly.” Given what we observed above about the need to specify an early stopping point to avoid over fitting, this might not be a bad thing. Like all our solutions, we’re happy so long as it generalizes.
Other articles in this series:
Quantum Computing and Deep Learning. How Soon? How Fast?
Understanding the Quantum Computing Landscape Today – Buy, Rent, or Wait
The Three Way Race to the Future of AI. Quantum vs. Neuromorphic vs. High Performance Computing
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}