
Summary: Deep Learning, based on deep neural nets is launching a thousand ventures but leaving tens of thousands behind. Transfer Learning (TL), a method of reusing previously trained deep neural nets promises to make these applications available to everyone, even those with very little labeled data.
 Deep Learning, based on deep neural nets is launching a thousand ventures but leaving tens of thousands behind. The broad problems with DNNs are well known.
Deep Learning, based on deep neural nets is launching a thousand ventures but leaving tens of thousands behind. The broad problems with DNNs are well known.
- Complexity leading to extended time to success and an abnormally high outright failure rate.
- Extremely large quantities of labeled data needed to train.
- Large amounts of expensive specialized compute resources.
- Scarcity of data scientist qualified to create and maintain the models.
The entire field has really come into its own only in the last two or three years and growth has been exponential among those able to overcome these drawbacks. And it’s fair to say that the deep learning provider community understands and is working to resolve these issues.
It’s likely that over the next two or three years these will be overcome. But in the meantime, large swaths of potential users are being deterred and delayed in gaining benefit.
Two Main Avenues of Progress – Automation and Transfer Learning
The problem for those wanting to create their own robust multi-object classifiers is most severe. If you succeed in hiring the necessary talent, and if your pockets are deep enough for AWS, Azure, or Google cloud resources, you still face the main problems of complexity and large quantities of labeled data.
Already you can begin to find companies who claim to have solved the complexity problem by automating DNN hyperparameter tuning. Right behind these small innovators are Google and Microsoft who are publically laying out their strategies for doing the same thing.
More than any other algorithms we’ve been faced with; the hyperparameters of DNNs are the most varied and complex. Starting with the number of nodes, the number, types, and connectivity of the layers, selection of activation function, learning rate, momentum, number of epochs, and batch size for starters. The requirement for handcrafting through multiple experimental configurations is the root cause of cost, delay, and the failure of some systems to train at all.
But there is a way for companies with only modest amounts of data and modest data science resources to join the game is short order, and that’s through Transfer Learning (TL).
The Basics
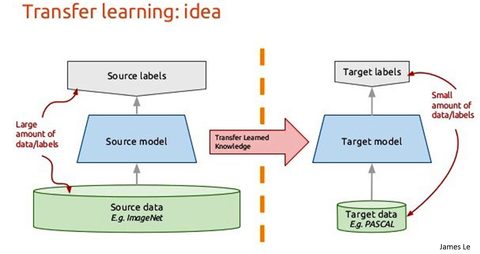 TL is primarily seen today in image classification problems but has been used in video, facial recognition, and text-sequence type problems including sentiment analysis.
TL is primarily seen today in image classification problems but has been used in video, facial recognition, and text-sequence type problems including sentiment analysis.
The central concept is to use a more complex but successful pre-trained DNN model to ‘transfer’ its learning to your more simplified (or equally but not more complex) problem.
The existing successful pre-trained model has two important attributes:
- Its tuning parameters have already been tested and found to be successful, eliminating the experimentation around setting the hyperparameters.
- The earlier or shallower layers of a CNN are essentially learning the features of the image set such as edges, shapes, textures and the like. Only the last one or two layers of a CNN are performing the most complex tasks of summarizing the vectorized image data into the classification data for the 10, 100, or 1,000 different images they are supposed to identify. These earlier shallow layers of the CNN can be thought of as featurizers, discovering the previously undefined features on which the later classification is based.
There are two fundamentally different approaches to TL, each based separately on these two attributes.
Create a Wholly New Model
If you have a fairly large amount of labeled data (estimates range down to 1,000 images per class but are probably larger) then you can utilize the more accurate TL method by creating a wholly new model using the weights and hyperparameters of the pre-trained model.
Essentially you are capitalizing on the experimentation done to make the original model successful. In training the number of layers will remain fixed (as well as the overall architecture of the model). The final layers will be optimized for your specific set of images.
Simplified Transfer Learning
The more common approach is a benefit for those with only a limited quantity of labeled data. There are some reports of being able to train with as few as 100 labeled images per class, but as always, more is better.
If you attempted to use the first technique of training the entire original model with just a few instances, you would almost surely get overfitting.
In simplified TL the pre-trained transfer model is simply chopped off at the last one or two layers. Once again, the early, shallow layers are those that have identified and vectorized the features and typically only the last one or two layers need to be replaced.
The output of the truncated ‘featurizer’ front end is then fed to a standard classifier like an SVM or logistic regression to train against your specific images.
The Promise
There’s no question that simplified TL will appeal to the larger group of disenfranchised users since it needs neither large quantities of data or exceptionally sophisticated data scientists.
It’s no surprise that the earliest offerings rolled out by Microsoft and Google focus exclusively on this technique. Other smaller providers can demonstrate both simplified and fully automated DNN techniques.
Last week we reviewed the offering from OneClick.AI that has examples of simplified TL achieving accuracies of 90% and 95%. Others have reported equally good results with limited data.
It’s also possible to use the AutoDL features from Microsoft, Google, and OneClick to create a deployable model without any code, by simply dragging-and-dropping your images onto their platform.
The Limits
Like any automated or greatly simplified data science procedure, you need to know the limits. First and foremost, the pre-trained model you choose for the starting point must process images that are similar to yours.
For example, a model trained on the extensive ImageNet database that can correctly classify thousands of objects will probably let you correctly transfer features from horses, cows, and other domestic livestock onto exotic endangered species. When doing facial recognition, best to use a different existing model like VGG.
However, trying to apply the featurization ability of an ImageNet trained DNN to more exotic data may not work well at all. Others have noted for example that medical imaging from radiography or CAT scans are originally derived in greyscale and that these image types, clearly not present in ImageNet, are unlikely to featurize accurately. Other types that should be immediately suspect might include scientific signals data or images for which there is no real world correlate, including seismic or multi-spectral images.
The underlying assumption is that the patterns in the images to be featurized existed in the pre-trained model’s training set.
The Pre-trained Model Zoo
There are a very large number of pre-trained models to use as the basis of TL. A short list drawn from the much larger universe would include:
- LeNet
- AlexNet
- OverFeat
- VGG
- GoogLeNet
- PReLUnet
- ResNet
- ImageNet
- MS Coco
All of which have several versions with different original image sets for you to pick from.
One Other Interesting Application of Transfer Learning
This may not have much commercial application but it’s interesting to know that you can use TL to combine two separate pre-trained models to achieve unexpected artistic results.
 Right now these are being applied experimentally for mostly artistic results. The technique takes one model selected for content and another model selected for style, and combines them.
Right now these are being applied experimentally for mostly artistic results. The technique takes one model selected for content and another model selected for style, and combines them.
What takes a bit of experimentation is looking at each convolutional and pooling layer to decide which unique look you want your resulting image to have.
In the End
You can go-it-alone in Tensorflow or the other DL platforms, or you can start by experimenting with one of the fully automated ADL offerings above. Neither data nor experience should hold you back from adding deep learning features to your customer-facing or internal systems.
Previous articles on Automated Machine Learning and Deep Learning
Automated Deep Learning – So Simple Anyone Can Do It (April 2018)
Next Generation Automated Machine Learning (AML) (April 2018)
More on Fully Automated Machine Learning (August 2017)
Automated Machine Learning for Professionals (July 2017)
Data Scientists Automated and Unemployed by 2025 – Update! (July 2017)
Data Scientists Automated and Unemployed by 2025! (April 2016)
Other articles by Bill Vorhies.
About the author: Bill Vorhies Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}