

This is the second part of a 2-part series on the growing importance of teaching Data and AI literacy to our students. This will be included in a module I am teaching at Menlo College but wanted to share the blog to help validate the content before presenting to my students.
In part 1 of this 2-part series “The Growing Importance of Data and AI Literacy”, I talked about data literacy, third-party data aggregators, data privacy, and how organizations monetize your personal data. I started the blog with a discussion of Apple’s plans to introduce new iPhone software that uses artificial intelligence (AI) to detect and report child sexual abuse. That action by Apple raises several personal privacy questions including:
- How much personal privacy is one willing to give up trying to halt this abhorrent behavior?
- How much do we trust the organization (Apple in this case) in their use of the data to stop child pornography?
- How much do we trust that the results of the analysis won’t get into unethical players’ hands and used for nefarious purposes?
In particular, let’s be sure that we have thoroughly vented the costs associated with the AI model’s False Positives (accusing an innocent person of child pornography) and False Negatives (missing people who are guilty of child pornography). That is the focus of Part 2!
What at is AI Literacy?
AI literacy starts by understanding how an AI model works (See Figure 1).
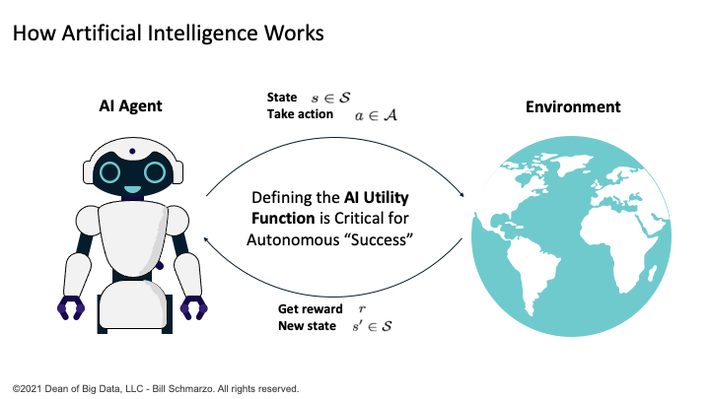
Figure 1: “Why Utility Determination Is Critical to Defining AI Success“
AI models learn through the following process:
- The AI Engineer (in very close collaboration with the business stakeholders) defines the AI Utility Function, which are the KPIs against which the AI model’s progress and success will be measured.
- The AI model operates and interacts within its environment using the AI Utility Function to gain feedback in order to continuously learn and adapt its performance (using backpropagation and stochastic gradient descent to constantly tweak the models weights and biases).
- The AI model seeks to make the “right” or optimal decisions, as framed by the AI Utility Function, as the AI model interacts with its environment.
Bottom-line: the AI model seeks to maximize “rewards” based upon the definitions of “value” as articulated in the AI Utility Function (Figure 3).
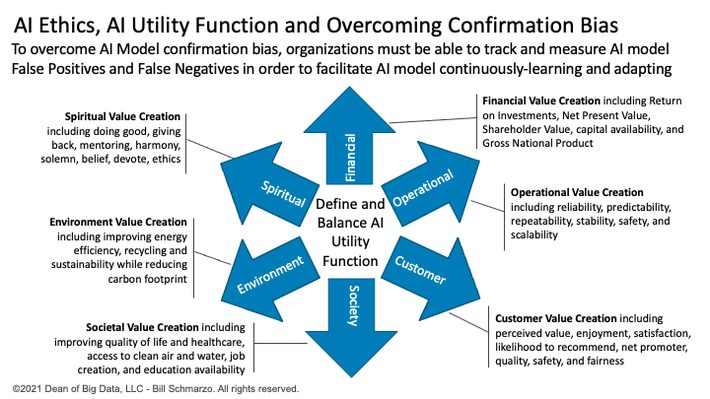
Figure 2: “Will AI Force Humans to Become More Human?”
To create a rational AI model that understands how to make the appropriate decisions, the AI programmer must collaborate with a diverse cohort of stakeholders to define a wide range of sometimes-conflicting value dimensions that comprise the AI Utility Function. For example, increase financial value, while reducing operational costs and risks, while improving customer satisfaction and likelihood to recommend, while improving societal value and quality of life, while reducing environmental impact and carbon footprint.
Defining the AI Utility Function is critical because as much credit as we want to give AI systems, they are basically dumb systems that will seek to optimize around the variables and metrics (the AI Utility Function) that are given to them.
To summarize, the AI model’s competence to take “intelligent” actions is based upon “value” as defined by the AI Utility Function.
AI Confirmation Bias Challenge
One of the biggest challenges in AI Ethics has nothing to do with the AI technology and has everything to do with Confirmation Bias. AI model Confirmation Bias is the tendency for an AI model to identify, interpret, and present recommendations in a way that confirms or supports the AI model’s preexisting assumptions. AI model confirmation bias feeds upon itself, creating an echo chamber effect with respect to the biased data that continuously feeds the AI models. As a result, the AI model continues to target the same customers and the same activities thereby continuously reinforcing preexisting AI model biases.
As discussed in Cathy O’Neil’s book “Weapons of Math Destruction”, the confirmation biases built into many of the AI models that are used to approve loans, hire job applicants, and accept university admissions are yielding unintended consequences that severely impact individuals and society. Creating AI models that overcome confirmation biases takes upfront work and some creativity. That work starts by 1) understanding the costs associated with the AI model’s False Positives and False Negatives and 2) building a feedback loop (instrumenting) where the AI model is continuously-learning and adapting from tis False Positives and False Negatives.
Instrumenting and measuring False Positives – the job applicant you should not have hired, the student you should not have admitted, the consumer you should not have given the loan – are fairly easy because there are operational systems to identify and understand the ramifications of those decisions. The challenge is identifying the ramifications of the False Negatives.
In order to create AI models that can overcome model bias, organizations must address the False Negatives measurement challenge. Organizations must be able to 1) track and measure False Negatives to 2) facilitate the continuously-learning and adapting AI models that mitigates AI model biases.
The instrumenting and measuring of False Negatives – the job applicants you did not hire, the student applicant you did not admit, the customer to whom you did not grant a loan – is hard, but possible. Think about how an AI model learns – you label the decision outcomes (success or failure), and the AI model continuously adjusts the variables that are predictors of those outcomes. If you don’t feedback to the AI model its False Positives and False Negatives, then the model never learns, never adapts, and in the long run misses market opportunities. See my blog “Ethical AI, Monetizing False Negatives and Growing Total Address” for more details.
Building AI Trust with Transparency
Organizations need a guide for creating AI models that are transparent, unbiased, continuously-learn and adapt, and exist in support of societal laws and norms. That’s the role of the Ethical AI Application Pyramid (Figure 3).
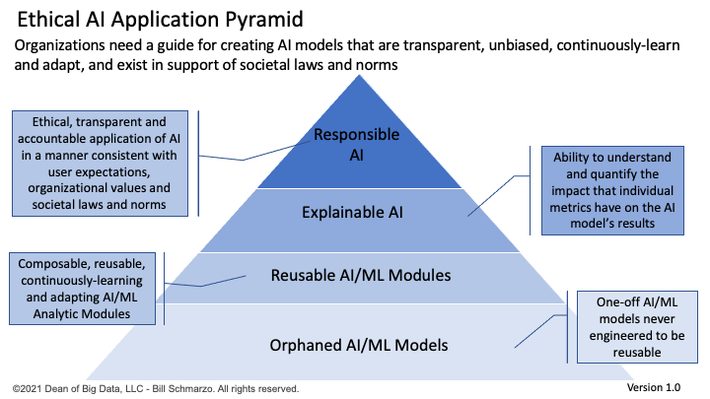
Figure 3: The Ethical AI Application Pyramid
The Ethical AI Application Pyramid embraces the aspirations of Responsible AI by ensuring the ethical, transparent, and accountable application of AI models in a manner consistent with user expectations, organizational values and societal laws and norms. See my blog “The Ethical AI Application Pyramid” for more details about the Ethical AI Application Pyramid.
AI Literacy and Ethics Summary
AI run amuck is a favorite movie topic. Let’s review a few of them (each of these is on my rewatchable list):
- Eagle Eye: An AI super brain (ARIIA) uses Big Data and IOT to nefariously influence humans’ decisions and actions.
- I, Robot: Way cool looking autonomous robots continuously learn and evolve empowered by a cloud-based AI overlord (VIKI).
- The Terminator: An autonomous human killing machine stays true to its AI Utility Function in seeking out and killing a specific human target, no matter the unintended consequences.
- Colossus: The Forbin Project: An American AI supercomputer learns to collaborate with a Russian AI supercomputer to protect humans from killing themselves, much to the chagrin of humans who are intent on killing themselves.
- War Games: The WOPR (War Operation Plan Response) AI system learns through game playing that the only smart nuclear war strategy is “not to play”.
- 2001: The AI-powered HAL supercomputer optimizes its AI Utility Function to accomplish its prime directive, again no matter the unintended consequences.
There are some common patterns in these movies – that AI models will seek to optimize their AI Utility Function (their prime directive) no matter the unintended consequences.
But here’s the real-world AI challenge: the AI models will not be perfect out of the box. The AI models, and their human counterparts, will need time to learn and adapt. Will people be patient enough to allow the AI models to learn? And do normal folks understand that AI models are never 100% accurate and while they will improve over time with more data, models can also drift over time as the environment in which they are working changes? And are we building “transparent” models so folks can understand the rationale behind the recommendations that AI models make?
These questions are the reason why Data and AI literacy education must be a top priority if AI is going to reach its potential…without the unintended consequences…

{kind=link}