
I have used synthetic data sets many times for simulation purposes, most recently in my articles Six degrees of Separations between any two Datasets and How to Lie with p-values. Many applications (including the data sets themselves) can be found in my books Applied Stochastic Processes and New Foundations of Statistical Science. For instance, these data sets can be used to benchmark some statistical tests of hypothesis (the null hypothesis known to be true or false in advance) and to assess the power of such tests or confidence intervals. In other cases, it is used to simulate clusters and test cluster detection / pattern detection algorithms, see here. I also used such data sets to discover two new deep conjectures in number theory (see here), to design new Fintech models such as bounded Brownian motions, and find new families of statistical distributions (see here).
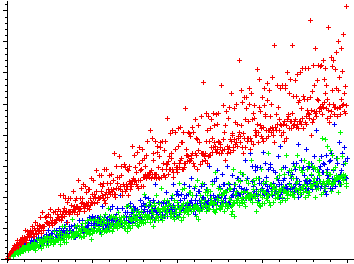
Goldbach’s comet (source: here)
In this article, I focus on peculiar random data sets to prove — heuristically — two of the most famous math conjectures in number theory, related to prime numbers: the Twin Prime conjecture, and the Goldbach conjecture. The methodology is at the intersection of probability theory, experimental math, and probabilistic number theory. It involves working with infinite data sets, dwarfing any data set found in any business context. While similar ideas have been explored in the past based on the concept of density (see here), in this article they are presented in a more general and simpler framework, using the concept of synthetic random data set. These data sets are truly random with some probability distributions assigned to them. The expectation or variance of some of the data set features (the average gap between two successive values for instance) can many times be computed explicitly, or can lead to some interesting asymptotic results.
Synthetic Random Sets and Twin Primes
The sets considered here consist of infinitely many positive integers. They are built as follows, using an arbitrary function f taking values between 0 and 1, and defined over the set of all positive integers.
Let S(f) be the random set in question. The positive integer n belongs to S(f) with probability f(n). In other words, for each integer n, generate a uniform deviate U(n) on [0,1]. If and only if U(n) < f(n) then add n to S(f). The deviates U(n) are independent. Now consider f(n) = 1 / log n if n > 2, and f(1) = f(2) = 0. With this particular choice of f, the set S(f) has the same “density” as the set of prime numbers thanks to the prime number theorem, and behaves in a very similar way. Let us define the following functions (actually, they are random variables):
- M(n) is the number of elements in S(f) that are smaller than n.
- T(n) is the number of twin pairs (k, k+1) with both k, k+1 belonging to S(f) and k ≤ n.
The twins in S(f) play the same role as twin primes. It is is easy to prove that M(n) (its expectation) is asymptotically equal to the logarithm integral Li(n). The same is true for the prime counting function. Furthermore, the prime numbers themselves is a particular case of S(f), a particular realization of the random set S(f) with the same function f. (you need to ignore even integers in the construction process, but other than that, it’s straightforward.)
Then we also have:
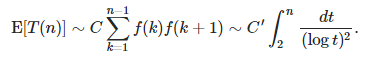
Here E denotes the expectation; C and C‘ are two positive constants.. The same result is conjectured to be true for twin primes. It is easy to show that there are infinitely many twin numbers in S(f), and to assess whether the series consisting of the reciprocals of these twins, converge (it does). The same arguments could be applied to twin primes, but of course, it would no constitute a proof, just some heuristic argumentation.
The Goldbach Conjecture
The Goldbach conjecture states that every even integer is the sum of two primes. Using our random sets, with the same function f, we can easily obtain a stronger result about the asymptotic value for the expected number of ways an even number n can be represented as a sum of two primes. The answer is
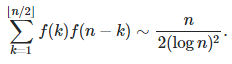
In short, we proved that the result is true for the random set that we built, and thus it must (likely) be true for prime numbers as well, which is the topic of the conjecture. The above asymptotic equivalence is based on the following fact. For many functions f including the one we are interested in (f(k) = 1 / log k if k >2), we have:
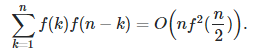
Here the implicit constant under the Landau symbol O is equal to 1. See here for details. I could not find a proof of this simple result, but the above sum is the discrete self-convolution of the function f. Another conjecture, more general than Goldbach (indeed also a generalization of Waring’s problem), can be found in one of my previous articles, here. Finally, the concept of random sets can be extended to sets of real numbers, or sets of matrices, polynomials, functions, set of sets, or even nested random sets.
Exercise
Using the same function f, prove that the probability, for any positive integer n to be the sum of two elements of S(f), tends to 1 as n tends to infinity.
Solution (hints):
Let us denote as H(n) the event “n can not be written as k + (n – k) with both k and n – k belonging to S(f)”. Show that P(H(n)) = 1 – f(k) – f(n–k) + f(k)f(n–k). As a result, the probability that n can not be written as the sum of two elements of S(f), is
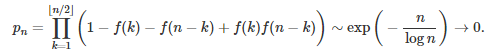
Thus 1 – p(n), the probability that needs to be computed, tends to 1. In short, very large integers can almost always be expressed as the sum of two elements of S(f). In other words, almost all very large even integers can be expressed as the sum of two primes. Note that the brackets in the product represent the integer part function.
{kind=link}