
Neuromancer Blues” is a series of posts where I would like the reader to find guidance about overall data science topics such as data wrangling, database connectivity, applied mathematics and programming tips to boost code efficiency, readability and speed. My examples and coding snippets will be as short and sweet as possible in order to convey the key idea instead of providing a lengthy code with poor readability that damages the purpose of the post.
Threading (AKA multithreading) and multiprocessing is a topic I wanted to write for a long time. This first post will be focused on introducing both concepts with emphasis on threading, and why is so important for developers in finance. Future Neuromancer series posts will spend more time on multiprocessing and programming efficiency issues such as race conditions or deadlocks.
The Basics
Let’s clarify key concepts that will be recurrent in this post:
- Concurrency: when two tasks can start, run, and complete in overlapping time periods.
- Parallelism: when tasks literally run at the same time e.g. multi-core processor
- I/O-bound task: tasks that spends most of the time in i/o (input/output) state i.e. network read/write, database queries, etc.
- CPU-bond task: tasks that spends most of the time in CPU i.e. browsing multiple websites, machine algo training, etc.
- GIL (Global Interpreter Lock): GIL is a lock that avoids a single python process to run threads in parallel (using multiple cores) at any point in time, yet they can be run concurrently. Although not visible for single-threaded tasks, GIL becomes an issue when performing multi-threaded code or CPU-bound tasks.
- Deadlock: event that occurs when two or more threads/tasks are waiting on each other, not executing and blocking the whole program.
- Race conditions: event that occurs when two or more threads/tasks run in parallel but end up delivering a flawed result as a consequence of an incorrect sequence of the operations.
In Coding we need to avoid both race conditions and deadlocks. The best recipe to avoid race conditions is to apply Thread Safety policies using either approaches that avoid a shared state or methods related to synchronization. In addition, we wish also to avoid deadlocks by having processes crossing over building mutual dependencies i.e. reduce the need to lock anything as much as you can. These topic is more advanced and deserve another series of posts in the future.
Threading vs Multiprocessing: Brief Intro
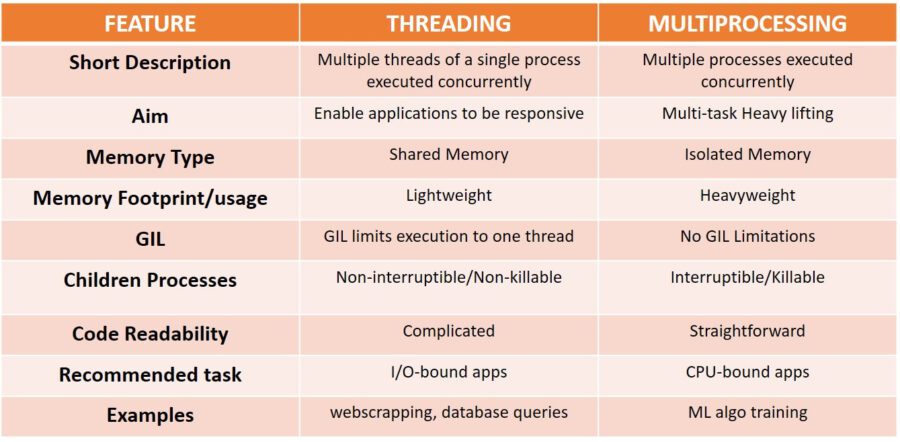
Now we are in the same page thus let’s answer what is the difference between threading and multiprocessing and why it matters so much. The table below provides a comprehensive comparison between methods.
In a nutshell, threading is used to run multiple threads/tasks at the same time inside the same process , yet it will not enhance speed if we are already using 100 % CPU time. On the other hand, multiprocessing allows the programmer to open multiple processors on a given CPU, each one of them with their own memory and with no GIL limitations.
Python threads are used in I/O-bound tasks mainly where the execution involves some waiting time. In Finance a straightforward example is when querying an external database, for which reason we will simulate a similar i/O-bound task using yahoo finance data.
As I mentioned in the introduction, I would like to concentrate on threading for this post so let’s get down to business.
Classic Approach: Using Threading Module
The threading module provided with Python includes a simple-to-implement locking mechanism that allows you to synchronize threads. In other words, this module allows you to have different parts of your program run concurrently and improve the code readability.
Let’s first understand what’s the point of doing threading. The code snippet underneath shows a looping process where we execute a I/O-bound tasks reading financial data from yahoo finance using pandas datareader module. Although pandas datareader allows bulking – downloading data from a list of tickers at once – we are going to naively run each I/O-task on a stand-alone basis per ticker and following a sequential execution approach i.e. a new call only starts when the former call is finished.
Please notice about the one second delay introduced within our io_task() function with time module. For the sake of simplicity, we are only downloading price data for less than five years, for which reason this is a pretty fast query by nature. The introduction of this one second delay simulates that our query is taking more time e.g. downloading data such as +100 fundamental indicators, which is a more realistic simulation.
{kind=link}