
This article was written by Richard Lawler. Richard’s been tech obsessed since first laying hands on an Atari joystick.
.
Millions of images and YouTube videos, linked and tagged to teach computers what a spoon is.
It seems like we hear about a new breakthrough using machine learning nearly every day, but it’s not easy. In order to fine-tune algorithms that recognize and predict patterns in data, you need to feed them massive amounts of already-tagged information to test and learn from. For researchers, that’s where two recently-released archives from Google will come in. Joining other high-quality datasets, Open Images and YouTube8-M provide millions of annotated links for researchers to train their processes on.
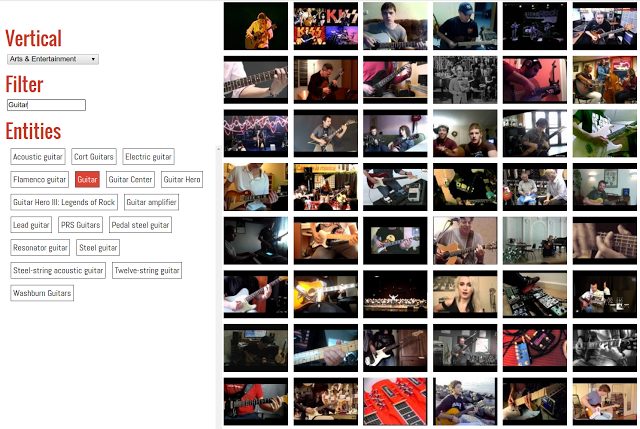
The Open Images set comes from a collaboration between Google, Carnegie Mellon and Cornell, with 9 million entries that were tagged by computers first before having those notes verified and corrected by humans. The Google Research team says it has enough images to train a neural network “from scratch,” so if you’d like to try your hand at a DeepDream-style project, better version of Google Photos or the next Prisma then it’s ready to go.
.
To read the full article, click here.
Top DSC Resources
- Article: Difference between Machine Learning, Data Science, AI, Deep Learnin…
- Article: What is Data Science? 24 Fundamental Articles Answering This Question
- Article: Hitchhiker’s Guide to Data Science, Machine Learning, R, Python
- Tutorial: Data Science Cheat Sheet
- Tutorial: How to Become a Data Scientist – On Your Own
- Categories: Data Science – Machine Learning – AI – IoT – Deep Learning
- Tools: Hadoop – DataViZ – Python – R – SQL – Excel
- Techniques: Clustering – Regression – SVM – Neural Nets – Ensembles – Decision Trees
- Links: Cheat Sheets – Books – Events – Webinars – Tutorials – Training – News – Jobs
- Links: Announcements – Salary Surveys – Data Sets – Certification – RSS Feeds – About Us
- Newsletter: Sign-up – Past Editions – Members-Only Section – Content Search – For Bloggers
- DSC on: Ning – Twitter – LinkedIn – Facebook – GooglePlus
Follow us on Twitter: @DataScienceCtrl | @AnalyticBridge
{kind=link}