
Guest blog by Seth Dobrin and Daniel Hernandez.
Companies have been sold on the alchemy of data science. They have been promised transformative results. They modeled their expectations after their favorite digital-born companies. They have piled a ton of money into hiring expensive data scientists and ML engineers. They invested heavily in software and hardware. They spend considerable time ideating. Yet despite all this effort and money, many of these companies are enjoying little to no meaningful benefit. This is primarily because they have spent all these resources on too much experimentation, projects with no clear business purpose, and activity that doesn’t align with organizational priorities.
When the music stops and the money dries up, the purse strings will tighten up and the resources that are funding this work will die. It’s then that data science will be accused of being a scam.
To turn data science from a scam to source of value, enterprises need to consider turning their data science programs from research endeavors into integral parts of their business and processes. At the same time, they need to consider laying down a true information architecture foundation. We frame this as the AI ladder: Data foundation, analytics, machine learning, AI/Cognitive:
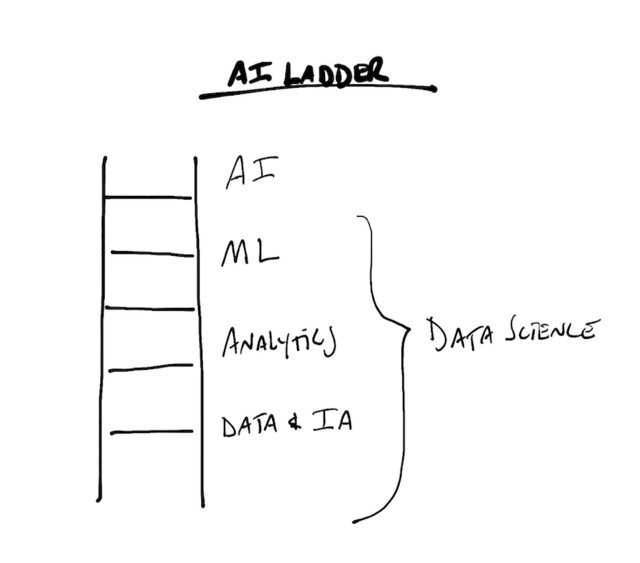
To break the current pattern of investing in data science without realizing the returns, businesses can address key areas:
- Finding, retaining, and building the right talent and teams
- Formulating an enterprise strategy for data and data science
- Operationalizing data science
- Overcoming culture shock
Finding, retaining and building the right talent and teams
Our two previous VentureBeat articles cover the composition of a data science team and the skills we look for in a data scientist. To recap, great data science teams rely on four skillsets: Data Engineer, Machine Learning Engineer, Optimization Engineer, and Data Journalist. If you want to maximize the number of qualified applicants, try posting roles with those four titles and skill sets instead of seeking out generic “Data Scientists”.
Retaining talent requires attention on several fronts. First, the team needs to be connected to the value they’re driving: How is their project impacting the line of business and the enterprise? Second, they need to feel empowered and know you have their backs. Finally, when planning for your team, build in 20–25% of free time work on innovative, blue-sky projects, to jump into Kaggle-like competitions, and to learn new tools and skills. Carving out that much time might seem pricey in terms of productivity, but it provides an avenue for the team to build the skills that accelerate future use cases — and it’s far more efficient than hiring and training new talent.
Formulating an enterprise strategy for data and data science
Identify, Value, and Prioritize Decisions
Map out the decisions being made and align them to tangible value, specifically, cost avoidance, cost savings, or net new revenue. This is the most important step in this process and the first step in shifting data science from research to an integral part of your business. We’ve previously mapped out a process for doing this in Six Steps Ups, but briefly, it requires direct conversations with business owners (VPs or their delegates) about the decisions they’re making. Ask about the data they use to make those decisions, its integrity, whether there’s adequate data governance, and how likely the business is to use any of the models already developed.
You can drive decisions using a dashboard that’s integrated directly into processes and applications. However, beware of situations where data simply supports preconceived notions. Instead, look for chances to influence truly foundational decisions:
“Where should we position product for optimal availability at minimal cost?”
“What are our most likely opportunities for cross-sell/up-sell for specific customers?”
“Which are my top-performing teams? Bottom-performing teams?”
“How can I cut costs from my supply chain by optimizing x given y constraints?”
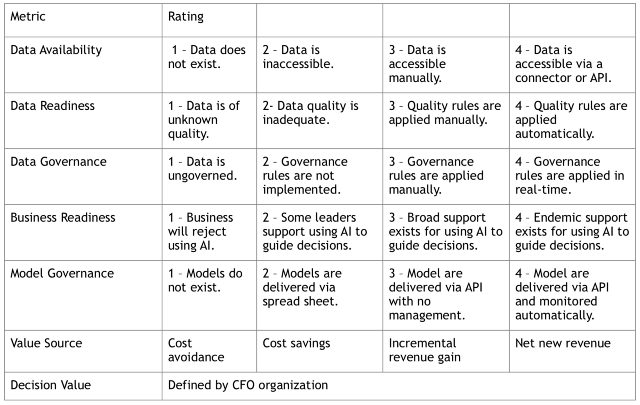
Value each decision. Making decisions more quickly and with greater efficacy avoids costs, saves costs, or creates additional revenue. Express this value using whatever methodologies and terms your CFO advocates.
Prioritize the decision portfolio. This exercise creates a decision portfolio, which can serve as the basis for a data science backlog. Prioritize the backlog by assessing the likelihood of success, the ease of implementation, and the value (based on the scoring metric in the table above). We’ve developed a framework for building and prioritizing the portfolio by going through this exercise ourselves.
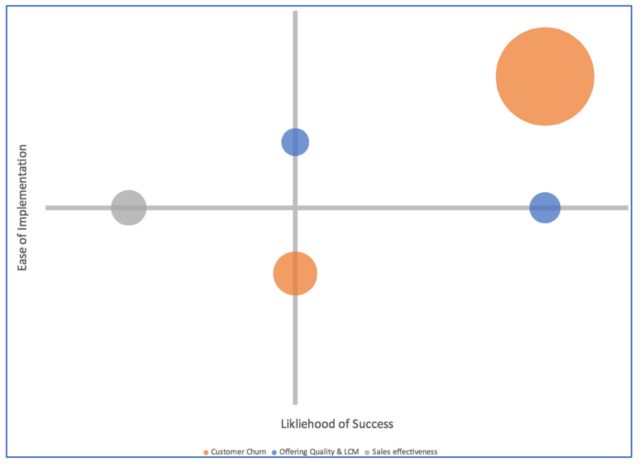
Discrete Deliverables. Next, take your top decisions and break them into manageable chunks that you can deliver in small sprints. This starts by identifying the minimal viable product (MVP) and then working back from there. Consider three-week sprints that can start delivering value (however small) after two sprints.
Operationalizing data science
Moving data from a research project to an integral part of your company requires operationalizing your data science program. In addition to building the team and setting the strategy, it requires integrating the models into processes, applications, and dashboards. Also plan for continual monitoring and retraining of model deployments.
Truly integrating the models means they can’t be deployed as csv files sent by email or code tossed over the wall to a development team. They need to be deployable as reusable and trusted services: versioned RESTful APIs output directly from the data science platform. Delivering models as csv files severs the connection to the process — and the feedback that comes from the implementation. Tossing R or Python code to a development team to convert it into an API is inefficient at best. But be prepared for some work. Setting up a robust process can often take three to six months and needs to be configured as a feedback-loop that easily allows your team to retrain and redeploy the models.
Applying predictive or prescriptive analytics to your business inevitably requires you to retrain the models to stay current with the accelerated rate of change they are driving and based on the feedback to the models from the outcomes themselves. We’ve seen instances where a team develops more than one hundred models to drive a single decision over the course of a year only to develop zero models the following year because the team is now focused entirely on monitoring and retraining of their existing models. It’s important to recognize that this isn’t a defect in their approach. They needed to build that many models to solve the problem. The issue is that in the course of operationalizing the model deployments, they didn’t automate the monitoring and retraining of those models.
Unless you’ve already executed a large number of data science projects for the enterprise, the challenges of operationalizing can come as a surprise — but they are very real.
Derived data products. We can often overlook the fact that our engineered features are valuable data in and of themselves. As part of model building and engineering, consider deploying this new data as APIs and integrating them into the appropriate data assets rather than letting them remain proprietary. For example, if a data science team engineers a feature that combines customer data, product data, and finance data, deploy the new feature as an API and have the corresponding model consume that new API.
Overcoming culture shock
Among the various reasons that data science becomes a scam at so many enterprises, one reason in particular looms large: cultural resistance. To break through resistance from management, focus on any of their peers who are excited to engage. Once they start applying the data and models in their processes and applications, the advocates may start to outperform the resistors. At some point, managers will ask what they are doing differently, and the resistors may feel pressure to shift their positions. Think of this as leading through shame. The value you demonstrate to managers is often about out-performing their peers by avoiding costs, saving money, or creating net new value
Individual contributors might resist the shift for a few different reasons. They might be worried they’ll be replaced by the machine or that the people who built it don’t fully understand the process or environment. Both are valid concerns. Buy credibility by being honest and addressing concerns head-on. However, in most cases you won’t actually be automating anyone out of a job, but rather making each job safer or more efficient. Help the team to see this directly. For the concern that the data science team doesn’t really understand what they do, consider pull one of the hold-outs off the floor and asking them work directly on the project as a product owner or subject matter expert. That provides other resisters an advocate that is “one of us”. When that team member returns to his regular job, you’ll have an advocate for the current data science approach, as well as an advocate for future implementations and deployments.
Finally, you can overcome the culture shock by raw mass. Identify a use case and build a related hack-a-thon that’s sponsored by senior executives. The hack-a-thon should include basic presentations on machine learning, cloud, and APIs, as well as more advanced presentations and conversations on the same topics. Let the teams work hands-on with the use case and allow individuals across the company to participate, independent of their training and background.
To turn the alchemy of data science into gold, enterprises must align their data science efforts to business outcomes with real and tangible value. They must stop focusing on experimentation and shift their efforts to data science as an integral part of their business models and align these with corporate priorities. If you follow the methodology above, the music will keep on playing, the funding will keep flowing, and data science will not be a scam in your enterprise.
Originally posted here.
About the Author

Seth Dobrin, PhD, is VP & CDO, IBM Analytics. Exponential Change Leader and Life-Long Learner with a proven track record of transforming businesses via data science, information technology, automation and molecular techniques. Highly skilled at leading thru influence across complex corporate organizations as demonstrated by having built, developed and executed corporate wide strategies.
Related Articles
- The First Things you Should Learn as a Data Scientist – Not what yo…
- Is it still possible today to become a self-taught data scientist?
- First Doctorship in Data Science
- Why Logistic Regression should be the last thing you learn when bec…
DSC Resources
- Free Book: Applied Stochastic Processes
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Post a Blog | Forum Questions
{kind=link}