
If you are an engineer working for a company like Boeing, have processed and leveraged data extensively over years of professional experience, used data science tools and programming languages, and have success stories, you are de facto a data scientist even if you think you are not, in this case an industrial data scientist, as opposed for instance, to a marketing data scientist. And you are hireable as a data scientist.
If you have a PhD in history, has little experience processing serious data and getting valuable insights out of it, and all you do is attending a one-week data camp, you are not going to be hired as a data scientist. You can self-teach many things, for instance I learned Perl, R, and SQL by myself, to the point of being able to use it in a corporate environment. But this is because during my years in college and military service, I learned other programming languages (C, C++) and how to design databases from scratch (it was one project for a class that I attended.) So the learning curve was not steep, and paying $20k to learn new programming languages would have been a waste of money. But I believe the main challenge is getting the experience to process large dirty data sets that have a structure changing over time, work with engineers, understand where the value is, develop/test prototypes and better algorithms, design black-box implementations (that work in production mode with some degree of reliability and added value) which you only learn through extensive experience in the corporate world, by interacting with high-level sales, marketing, engineering, IT and/or other executives or teams, and are able to “talk” and “understand” their “language.” Also, one drawback or being self-taught is that you will have “holes” in your knowledge, that you are not aware of, but they will show up one day, usually at the worst time. You may also not know what you should learn on your own, versus stuff that you can skip (though you could argue that you can ask in a data science forum what is important to learn, and some answers can be found online, for instance here.)
As an illustration, and in a different context, I learned number theory all by myself to the point of becoming an expert. Yet I started with a strong math curriculum in my college years, published my first paper in Journal of Number Theory (all my subsequent papers were about data science.) But my interest is peculiar: you could call me an amateur number theorist, or independent, self-funded researcher. My goal is not to publish in scientific journals, not even trying to be recognized by other number theorists, but to make state-of-the-art, new discoveries (my own) accessible to a large audience. There is no way I would ever be hired as a number theorist in Academia, maybe not even for an organisation such as NSA. I love what I do, but I do it with no desire of getting a paid position out of it (I could win some awards paid in dollars, but that is another story.) In short, self-teaching data science, even to an advanced level, may lead you to the same situation that I am in with number theory: a hobby, a passion that occupies much of my time, but nothing more than that. In itself, this is actually worth a lot more than landing a job, as many employees — including data scientists — seem somewhat depressed, misunderstood, or overworked nowadays. It depends what your goal is.
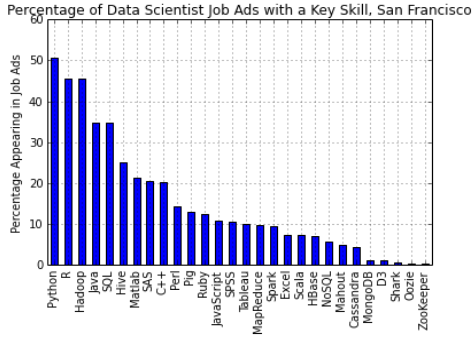
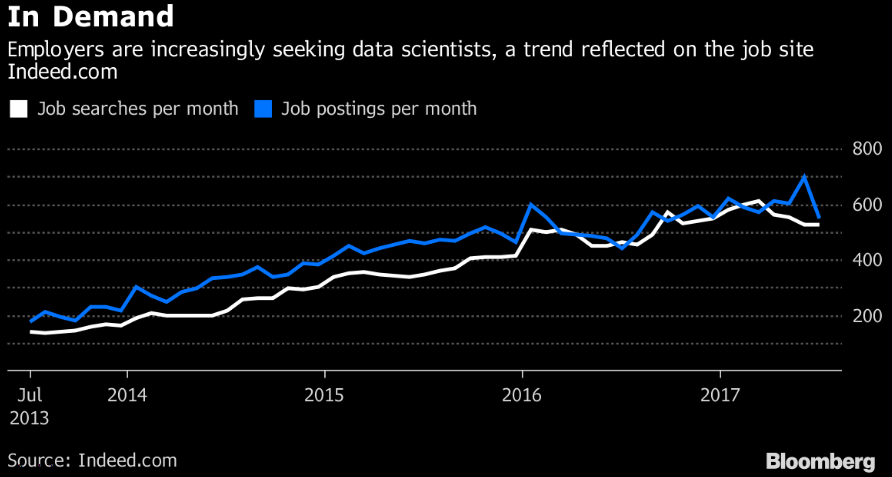
Source for picture: click here
To learn real data science, the best way is on the job though. Many curricula are still outdated today, so you could learn more than a college student, all by yourself, but employers won’t hire you as a data scientist unless you have the right experience and a related degree, not necessarily data science, but operations research, statistics, data analysis, software engineering, BI or MBA with a strong analytics background.
For related articles from the same author, click here or visit www.VincentGranville.com. Follow me on on LinkedIn.
DSC Resources
- Free Book: Applied Stochastic Processes
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Post a Blog | Forum Questions
{kind=link}