
Summary: Reinforcement Learning (RL) is going to be critical to achieving our AI/ML technology goals but it has several barriers to overcome. While reliability and a reduction in training data may be achievable within a year, the nature of RL as a ‘black box’ solution will bring scrutiny for its lack of transparency.
 Traditional machine learning and even deep learning supervised and unsupervised learning are at the core of the big financial investments and rewards in AI/ML currently being made by business. But the truth is that these are now fairly mature technologies with flattening benefit curves.
Traditional machine learning and even deep learning supervised and unsupervised learning are at the core of the big financial investments and rewards in AI/ML currently being made by business. But the truth is that these are now fairly mature technologies with flattening benefit curves.
If you’re looking for the next break through tech in AI/ML it’s almost surely going to come from reinforcement learning (RL). A lot of effort is going into RL research but it’s fair to say that RL hasn’t yet reached the standardization necessary for it to become a fully commercially ready tool.
There have been plenty of press-worthy wins in game play (Alpha Go) and some in autonomous vehicles. But while RL should be our go-to tech for any problem involving sequential decisions, it’s not there yet.
In our last article we highlighted the two shortcomings holding back RL as described by Romain Laroche, a Principal Researcher in RL at Microsoft:
- “They are largely unreliable. Even worse, two runs with different random seeds can yield very different results because of the stochasticity in the reinforcement learning process.”
- “They require billions of samples to obtain their results and extracting such astronomical numbers of samples in real world applications isn’t feasible.”
We focused on some hopeful research that addressed training with far less data, a critical financial and practical constraint. What remains however is even more complex.
Because RL solutions are initiated with a random seed they are essentially random searches through the state space. Envision two starter algorithms parachuted at random into this giant jungle of potential solutions with the goal of finding the quickest way out. While the two solutions may arrive at the same level of performance, RL is the proverbial black box that prevents us from seeing why and how the system selected the sequential steps it did.
Why this is important is highlighted by two conflicting objectives from Gartner’s recent report “Top 10 Strategic Technology Trends for 2020”.
The two trends that caught our eye are these:
Trend No. 8: Autonomous things
“Autonomous things, which include drones, robots, ships and appliances, exploit AI to perform tasks usually done by humans. This technology operates on a spectrum of intelligence ranging from semiautonomous to fully autonomous and across a variety of environments including air, sea and land…Autonomous things will also move from stand-alone to collaborative swarms, such as the drone swarms used during the Winter Olympic Games in 2018.”
Unsaid in the report is that to achieve this will require robust and reliable RL. While there are some really spectacular robots (thinking Boston Dynamics) that rely principally on the algorithms of physical motion, not AI/ML, to get to the next stage will require RL.
The second trend however will be much more difficult for RL.
Trend No. 5: Transparency and traceability
“The evolution of technology is creating a trust crisis. As consumers become more aware of how their data is being collected and used, organizations are also recognizing the increasing liability of storing and gathering the data.”
“Additionally, AI and ML are increasingly used to make decisions in place of humans, evolving the trust crisis and driving the need for ideas like explainable AI and AI governance.”
Though we are much more likely to think of GDPR and the privacy concerns around ecommerce, the fact is that all AI/ML will eventually be challenged based on our understanding of how they make their decisions.
Especially in light of the random nature of RL policy development and that two successful RL programs may reach the goal in completely different manners this is going to be a tough one to beat.
Dealing With Reliability
Romain Laroche has put forward two techniques that show promise in solving the reliability issues. In his paper, one dealing with an ensemble approach (EBAS) and the other with adjusting the tuning parameter Conditional value at Risk (CvaR) (the average of the worst runs), both of which can improve performance and reduce training time while limiting the natural tendency of RL runs to find and exploit glitches in the system that can cause successful results but include some form of unintended harm if actually released to production. This latter technique goes by the name SPIBB (Safe Policy Improvement with Baseline Bootstrapping).
The ensemble approach which borrows from the same concept in ML and is similar to the search process in genetic algorithm selection during training gives some very good results.
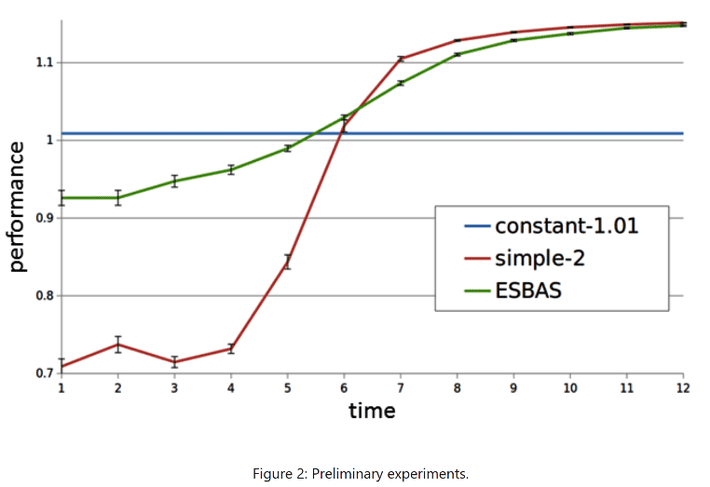
The EBAS algo learns more rapidly without any degradation in final performance.
Transparency?
We seem to be on our way to resolving the reliability problem and the separate problem of massive training data requirement. Where this will lead us is undoubtedly to the transparency issue. Examples are the scrutiny autonomous vehicles have received following human injuries and fatalities. We are much less tolerant of mistakes by our machines than we are of mistakes by their human operators.
Reinforcement Learning will no doubt make significant contributions in 2020 but the barriers of a proven commercially acceptable package and the pushback likely to come from its lack of transparency are unlikely to be fully resolved within a year.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2 million times.
He can be reached at:
{kind=link}