
Summary: For all the hype around winning game play and self-driving cars, traditional Reinforcement Learning (RL) has yet to deliver as a reliable tool for ML applications. Here we explore the main drawbacks as well as an innovative approach to RL that dramatically reduces the training compute requirement and time to train.
 Ever since Reinforcement Learning (RL) was recognized as a legitimate third style of machine learning alongside supervised and unsupervised learning we’ve been waiting for that killer app to prove its value.
Ever since Reinforcement Learning (RL) was recognized as a legitimate third style of machine learning alongside supervised and unsupervised learning we’ve been waiting for that killer app to prove its value.
Yes RL has had some press-worthy wins in game play (Alpha Go), self-driving cars (not here yet), drone control, and even dialogue systems like personal assistants but the big breakthrough isn’t here yet.
RL ought to be our go-to solution for any problem requiring sequential decisions and these individual successes might make you think that RL is ready for prime time but the reality is that it’s not.
Shortcomings of Reinforcement Learning
Romain Laroche, a Principal Researcher in RL at Microsoft points out several critical shortcomings. And while there are several, the most severe problems to be overcome Laroche points out are these:
- “They are largely unreliable. Even worse, two runs with different random seeds can yield very different results because of the stochasticity in the reinforcement learning process.”
- “They require billions of samples to obtain their results and extracting such astronomical numbers of samples in real world applications isn’t feasible.”
In fact, if you read our last blog closely about the barriers to continuously improving AI, you would have seen that the increasing compute power necessary to improve the most advanced algorithms is rapidly approaching the point of becoming uneconomic. And, that the most compute hungry among the examples tracked by OpenAI is AlphaGoZero, an RL game play algorithm requiring orders of magnitude more compute than the next closest deep learning application.
While Laroche’s research has lately focused on the reliability problem and he’s making some headway, if we don’t solve the compute requirement problem RL can’t take its rightful place as an important ML tool.
Upside Down Reinforcement Learning (UDRL)
Two recent papers out of AI research organizations in Switzerland describe a unique and unexpected approach to this by literally turning the RL learning process upside down (Upside Down Reinforcement Learning UDRL). Jürgen Schmidhuber and his colleagues say:
“Traditional Reinforcement Learning (RL) algorithms either predict rewards with value functions or maximize them using policy search. We study an alternative: Upside-Down Reinforcement Learning (Upside-Down RL or UDRL), that solves RL problems primarily using supervised learning techniques.”
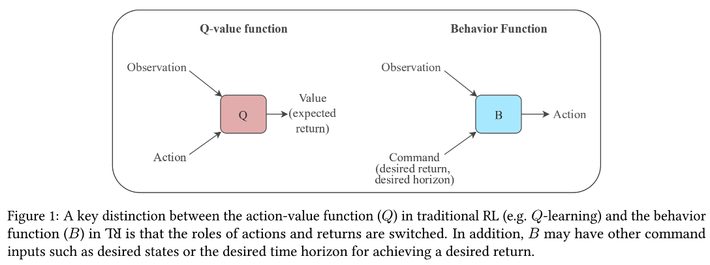
In its traditional configuration using value functions or policy search the RL algorithm essentially conducts a completely random search of the state space to find an optimum solution. The fact that it is in fact a random search accounts for the extremely large compute requirement for training. The more sequential steps in the learning process, the greater the search and compute requirement.
The new upside down approach introduces gradient descent from supervised learning which promises to make training orders of magnitude more efficient.
How It Works
Using rewards as inputs, UDRL observes commands as a combination of desired rewards and time horizons. For example “get so much reward within so much time” and then “get even more reward within even less time”.
As in traditional RL UDRL learns by simply interacting with its state space except that these unique commands now create learning based on gradient descent using these self-generated commands.
In short this means training occurs against trials that were previously considered successful (gradient descent) as opposed to completely random exploration.
On complex problems with many sequential steps UDRL proved both more accurate and most important much quicker to train than traditional RL (see steepness of green line on the left in the chart from the paper below).
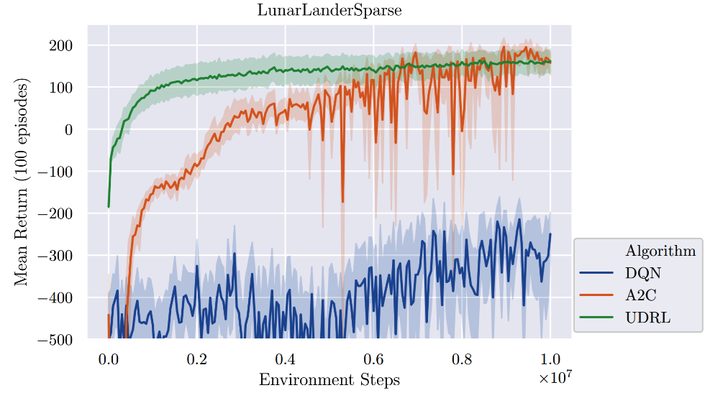
This does leave open the exploration/exploitation question since gradient descent techniques can hang on local optima, underfitting or overfitting.
A Main Application – Learn by Imitation
One of the most interesting applications of UDRL that speaks directly to reduced training time and compute is its ability to be used in train-by-example, or train-by-imitation techniques in robotics.
For example, a robotic arm could be manipulated by a human through the steps of a complex operation such as the assembly of an entire electronic device. The process would be repeated several times but each would be regarded as a successful example.
A video of the process would be divided into separate frames for training and as input to an RNN model resulting in supervised learning which the robot must learn to imitate. The task will be the command in the form of a reward which the robot will map with an action.
While this is new research yet to be proven in commercial application, the reduction in required compute and time to train goes a long way to resolving one of RLs biggest drawbacks.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2 million times.
He can be reached at:
{kind=link}