
The history of Database management systems could be interpreted as a Darwinian evolution process.
The dominance of relational databases gives way to the data warehouses one, which better adapt to the earliest business intelligence requirements; then, alongside the rise of the most popular big data platforms such as Hadoop or spark, comes the era of the NoSQL databases, which were designed to privilege scalability among other features (instead of consistency for example).
However, what has happened during the years, is more likely a specialization process.
In fact, we are experiencing the coexistence of many DBMS paradigms, such as columnar, key-value, document, etc; therefore, instead of relying on a general-purpose unique standard, it is possible to choose the one that is better optimized to manage a particular kind of data and that better fits architectural and functional requirements, e.g. a relational paradigm is still one of the best choices in order to deal with ACID transactions, while a columnar storage fits perfectly in a data lake architecture and so on. Among the above-mentioned solutions, time-series databases are getting very popular during the last few years.
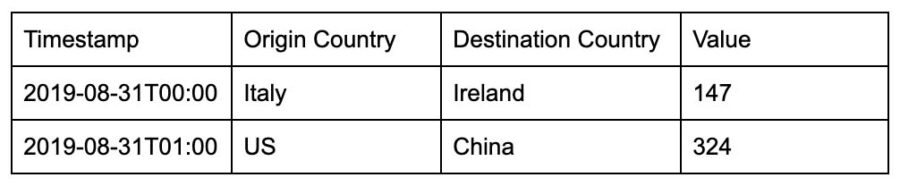
As the name suggests, a time-series database is designed and optimized to store data that evolves through time (time-series data). In other words, a time series is a (potentially unbounded) sequence of points for a particular metric over time. A metric is the measurement of a phenomenon that evolves through time.
For example, the number of people that come to a country for tourist purposes is an effective example of a metric.
This metric can have multiple dimensions (e.g. the origin country, the destination country) but it’s mandatory that every point has a timestamp and a numerical value that represents the measurement itself.
Time-series Databases in real-time analytics
There are many, very similar definitions of Real-time analytics, each of them agrees that it is the capability to collect and analyze real-time data, that is information immediately available after it comes in a system.
From a business perspective, a real-time analytic system must be able to provide insights while events are gathered into it, so that users are able to take actions with the lowest possible delay. As opposed to the traditional Big Data Analytics, which is focused on the possibility to analyze huge amounts of data generated by heterogeneous sources, it would be unacceptable to have an architecture, e.g. a data lake, that allows users to access to historical data updated to the last day, but event to the last hour.
What is strongly needed by real-time analytics is an architecture that processes data as soon as it is collected from the external world (applications, sensors, etc.), an architecture that privileges incremental updates instead of periodic full data recomputation; in other terms, a stream processing architecture.
Moreover, this kind of architecture naturally fits with time-series data; in fact, if data evolves in time, many single events are collected by the system, which must be able to process it individually.
Stream processing, by definition, is able to manage this scenario easily.
The most popular and also the most iconic stream processing architecture is called Kappa Architecture.
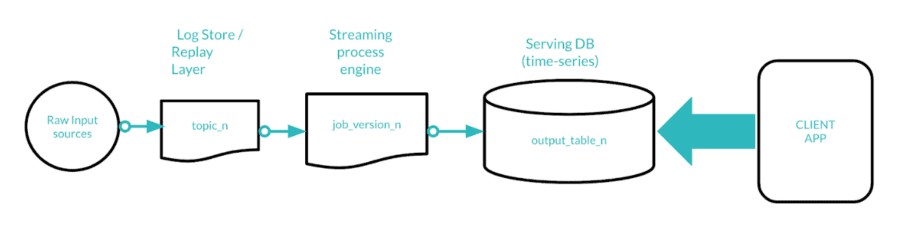
One of the peculiarities of this architecture is that 2 layers of persistence are expected:
- Log store: most of the time, raw events coming from the external are volatile, hence, for fault tolerance purposes, it must be possible to persist them. This storage layer does only require fast write throughput.
- Serving DataBase: client applications (for instance web or mobile dashboards) must query a database where a subset of the information contained in the raw events had been stored by the streaming process engine.
The serving Database must be optimized in order to guarantee the best read performance in querying data that evolves in time. Given all the assumptions made so far, it goes without saying that a time-series database acts perfectly as a serving layer DB.
{kind=link}