
Here I discuss breaking encryption keys that rely on the product of two very large prime numbers. In other words, the interest here is to factor a number (representing a key in some encryption system) that is the product of two very large primes. Once the number is factored, the key is compromised. Factoring such large numbers is believed to be computationally non-feasible, thus the interest in discovering new algorithms to disprove this conjecture, and specifically to factor large numbers (product of two large primes – the most difficult numbers to factor) much faster than with the current algorithms. As an important side note, I will discuss the randomness (or lack of) of the byproduct time series involved, and show why they are unsuitable to generate random deviates, despite satisfying several tests of randomness. This feature (lack of randomness) can further be exploited to develop more potent factoring algorithms.
1. The Basic Algorithm
We are interested in factoring integer numbers z = p * q where p and q are large, unknown primes. In this article, p and q are of the same order of magnitude, with (say) 0.5 < p/q < 2. The methodology below does not work otherwise. Clearly, using p and q that are of different orders of magnitude, will make the encryption key much stronger. However this would mean that one of the factors (p or q) is much smaller than the other one. The smaller min(p, q) is, the easier to break the system. Thus in practice it is not unusual to have p and q being of the same order of magnitude.
The algorithm proceeds as follows (here, INT represents the integer part function):
Compute y = INT(SQRT(z)).
For (k=0, k<N, k++) {
y = y+1;
w = y^2 – z;
if w is the square of an integer, then {
let x = SQRT(w);
p = y-x;
q = y+x;
problem solved! ( z = p * q)
}
}
The maximum number of iterations allowed – the number N – should be small, preferably well below the number of prime numbers less than SQRT(z), that is well below 2*SQRT(z)/log(z), otherwise naive factorization algorithms may be more efficient.
Examples
- z = 253: the prime factors 11 and 23 are found in 2 iterations
- z = 2,627: the prime factors 37 and 71 are found in 3 iterations
- z = 70,287,443: the prime factors 6,121 and 11,483 are found in 419 iterations; note that 6,121 is the 798-th prime number.
- z = 558,131,143: the prime factors 6,121 and 91,183 are found in 25,028 iterations; my algorithm is not efficient here, because the two prime factors are not of the same order of magnitude
Further research should be performed to find in which cases the algorithm is most useful, and whether it still works for very large prime factors. Note that for very large prime factors (the kind of numbers used in military-grade encryption keys), prime number tables may not be available, significantly reducing the effectiveness of other factorization algorithms, and thus potentially making my algorithm more valuable when p and q are of same order of magnitude. This needs to be checked.
Finally, in the main loop, it might be possible to skip many iterations that are almost certain not to produce a solution, thus making the algorithm run faster. A deep analysis of auto-correlations in the time series of residuals e = SQRT(w) – INT(SQRT(w)) may provide a solution. We haven’t investigated these time series in full detail yet, but the next section provides some interesting visual results.
2. Interesting Time Series
The residuals e = SQRT(w) – INT(SQRT(w)) obtained at each iteration in the above algorithm, make for an interesting time series. When e = 0 (which will happen only once if z is a product of two primes) then a solution z = p*q is found. Below is the time series of residuals for the first 420 iterations, when z = 70,287,443. Note that e = 0 at iteration 419, corresponding to the solution. Of course, the residual e is always between 0 and 1 (0 <= e < 1.)
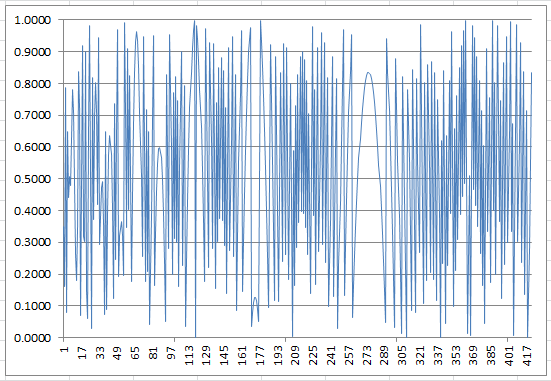
Figure 1: Residuals (420 iterations) when z is a product of two large primes (z =70,287,443)
The distribution of the residuals is uniform on [0,1] but clearly, the time series exhibits strong patterns and large scale auto-correlations. In particular, one notices the large parabolic bridge spanning from iterations #260 to #290 (there is a smaller one on the left-hand side, and a tiny one near the bottom around iteration #170). The successive local minima do not appear randomly, including the global minimum e = o at iteration 419, corresponding to the factorization.
Out of curiosity, I wondered if this pattern was a characteristic of products of two large primes. The answer is no. I tried with two other z’s that have almost the same value but that are either prime or have numerous factors, and here is what we get:
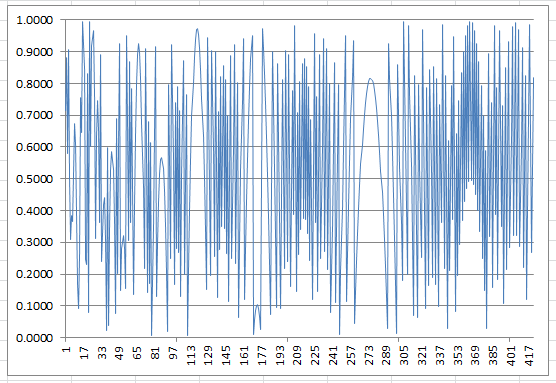
Figure 2: Residuals (420 iterations) when z is prime (z = 70,287,523)
Surprisingly, figures 1 and 2 are very similar. But there are differences too, especially around iteration #370, and of course e never reaches zero.
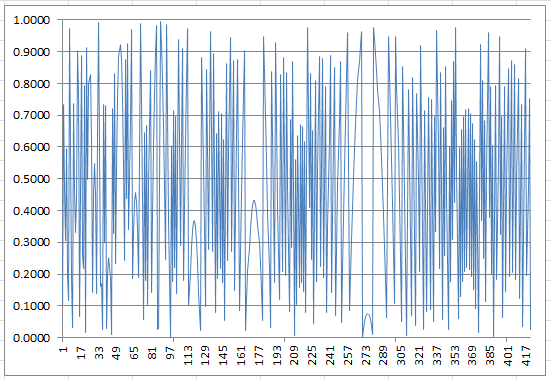
Figure 3: Residuals (420 iterations) when z is highly composite (z = 70,286,400)
Figure 3 is different from figures 1 and 2: it has more parabolic bridges, and the residual e is equal to zero more than once. The spreadsheet with the three charts can be downloaded here.
Technical Note: The number of iterations required in the algorithm is {(p + q)/2} – INT(SQRT(z). if p = a * INT(SQRT(z)) with 0 < a < 1, then the number of iterations is {(1 – a)^2 / a} * INT(SQRT(z)). Thus for large numbers, a detailed study of residuals is required to eliminate most of the iterations, possibly analyzing/predicting residuals for neighboring z’s (z+1, z-1 and so on.)
References
- Spectacular patterns found in rare, big numbers used in encryption …
- Curious formula generating all digits of square root numbers
- Large table of prime numbers (one trillion)
- Useful website about prime numbers
Top DSC Resources
- Article: What is Data Science? 24 Fundamental Articles Answering This Question
- Article: Hitchhiker’s Guide to Data Science, Machine Learning, R, Python
- Tutorial: Data Science Cheat Sheet
- Tutorial: How to Become a Data Scientist – On Your Own
- Categories: Data Science – Machine Learning – AI – IoT – Deep Learning
- Tools: Hadoop – DataViZ – Python – R – SQL – Excel
- Techniques: Clustering – Regression – SVM – Neural Nets – Ensembles – Decision Trees
- Links: Cheat Sheets – Books – Events – Webinars – Tutorials – Training – News – Jobs
- Links: Announcements – Salary Surveys – Data Sets – Certification – RSS Feeds – About Us
- Newsletter: Sign-up – Past Editions – Members-Only Section – Content Search – For Bloggers
- DSC on: Ning – Twitter – LinkedIn – Facebook – GooglePlus
{kind=link}