
Summary: Automated Machine Learning has only been around for a little over two years and already there are over 20 providers in this space. However, a new European AML platform called Tazi, new in the US, is showing what the next generation of AML will look like.
 I’ve been a follower and a fan of Automated Machine Learning (AML) since it first appeared in the market about two years ago. I wrote an article on all five of the market entrants I could find at the time under the somewhat scary title ‘Data Scientists Automated and Unemployed by 2025!’.
I’ve been a follower and a fan of Automated Machine Learning (AML) since it first appeared in the market about two years ago. I wrote an article on all five of the market entrants I could find at the time under the somewhat scary title ‘Data Scientists Automated and Unemployed by 2025!’.
As time passed I tried to keep up with the new entrants. A year later I wrote a series of update articles (links at the end of this article) that identified 7 competitors and 3 open source code packages. It was growing.
I’ve continued to try to keep track and I’m sure the count is now over 20 including at least three new entrants I just discovered at the March Strata Data conference in San Jose. I’m hoping that Gartner will organize all of this into a separate category soon.
Now that there are so many claimants, I do want to point out that the ones I think really earn this title are the ones that come closest to the original description of one-click-data-in-model-out. There are a whole host of providers providing semi-AML in which there are a number of simplified steps but are not truly one-click in simplicity and completeness.
What’s the Value?
Originally the claim was that these might completely replace data scientists. The marketing pitch was that the new Citizen Data Scientists (CDS) comprised mostly of motivated but untrained LOB managers and business analysts could simply step in and produce production quality models. Those of us on this side of the wizard’s curtain understood that was never going to be the case.
There is real value here though and it’s in efficiency and effectiveness. Allowing fewer rare and expensive data scientist do the work that used to require many in a fraction of the time. Early adopters with real data science departments like Farmers Insurance are using it in exactly this way.
The Minimum for Entry
To be part of this club the minimum functionality is the ability to automatically run many different algorithms in parallel, auto tune hyperparameters, and select and present a champion model for implementation.
This also means requiring as close to one click model building as you can get. While there might be expert modes, the fully automated mode should benchmark well against the fully manual efforts of a data science team.
For most entrants, this has meant presenting the AML platform with a fully scrubbed flat analytic file with all the data prep and feature engineering already completed. DataRobot (perhaps the best known or at least most successfully promoted), MLJAR, and PurePredictive are in this group. Some have added front ends with the ability to extract, blend, clean, and even feature engineer. Xpanse Analytics, and TIMi are some of the few with this feature.
New Next Generation Automated Machine Learning
At Strata San Jose in March I encountered a new entrant, Tazi.ai that after a long demonstration and a conversation with their data scientist founders really appears to have broken through into the next generation of AML.
 Ordinarily DataScienceCentral does not publish articles featuring just a single product or company, so please understand that this is not an endorsement. However, I was so struck by the combination and integration of features that I think Tazi is the first in what will become the new paradigm for AML platforms.
Ordinarily DataScienceCentral does not publish articles featuring just a single product or company, so please understand that this is not an endorsement. However, I was so struck by the combination and integration of features that I think Tazi is the first in what will become the new paradigm for AML platforms.
Tazi has been in the European market for about two years; recently received a nice round of funding, and opened offices in San Francisco.
What’s different about Tazi’s approach is not any particularly unique new feature but rather the way they have fully integrated the best concepts from all around our profession into the Swiss Army knife of AML. The value of the Swiss Army knife after all is not just that it has a blade, can opener, corkscrew, screwdriver, etc. The break through is in the fact all these features fit together so well in just one place so we don’t have to carry around all the pieces.
Here’s a high level explanation of the pieces and the way Tazi has integrated them so nicely.
Core Automated Algorithms and Tuning
Tazi of course has the one-click central core that runs multiple algorithms in parallel and presents the champion model in a nice UI. Hyperparameter tuning is fully automated.
The platform will take structured and unstructured data including text, numbers, time-series, networked-data, and features extracted from video.
As you might expect this means that some of the candidate algorithms range from simple GLMs and decision trees to much more advanced boosting and ensemble types and DNNs. This also means that some of these are going to run efficiency on CPUs but some are only going to realistically be possible on GPUs.
As data volume and features scale up Tazi can take advantage of IBM and NVIDIA’s Power8, GPU and NVLink based architecture that allows super-fast communication of CPU and GPUs working together in very efficient MPP.
Problem Types
Tazi is designed to cover the spectrum of business problem types divided into three broad categories:
- Typical consumer propensity classification problems like churn, non-performing loan prediction, collection risk, next best offer, cross sell, and other common classification tasks.
- Time series regression value predictions such as profitability, demand, or price optimization.
- Anomaly detection including fraud, predictive maintenance, and other IoT-type problems.
Streaming Data and Continuous Learning
The core design is based on streaming data making the platform easy to use for IoT type problems. Don’t need streaming capability? No problem. It accepts batch as well.
However, one of the most interesting features of Tazi is that its developers have turned the streaming feature into Continuous Learning. If it’s easier, think of this as Continuous Updating. Using atomic level streaming data (as opposed to mini-batch or sliding window), each new data item received is immediately processed as part of a new data set to continuously update the models.
If you are thinking fraud, preventive maintenance, or medical monitoring you have an image of very high data thru put from many different sources or sensors, which Tazi is equipped to handle. But even in relatively slow moving B2B or brick and mortar retail, continuous updating can mean that every time a customer order is received, a new customer registers, or a new return is processed those less frequent events will be fed immediately into the model update process.
If the data drifts sufficiently, this may mean that an entirely new algorithm will become the champion model. More likely, with gradual drift, the parameters and variable weightings will change indicating an update is necessary.
Feature Engineering and Feature Selection
Like any good streaming platform, Tazi directly receives and blends source data. It also performs the cleaning and prep, and performs feature engineering and feature selection.
For the most part, all the platforms that offer automated feature engineering execute by taking virtually all the date differences, ratios between values, time trends, and all the other statistical methods you might imagine to create a huge inventory of potential engineered variables. Almost all of these, which can measure in the thousands, will be worthless.
So the real test is to produce these quickly and also to run selection algos on them quickly to focus in on those that are actually important. Remember this is happening in a real time streaming environment where each new data item means a model update.
Automated feature engineering may never be perfect. It’s likely that the domain knowledge of SMEs may always add some valuable new predictive variable. Tazi says however that many times its automated approach has identified engineered variables that LOB SMEs had not previously considered.
Interpretability and the User Presentation Layer
Many of the early adopters in AML are in the regulated industries where the number of models is very large but the requirement for interpretability always requires a tradeoff between accuracy and explainability.
Here, Tazi has cleverly borrowed a page from the manual procedures many insurance companies and lenders have been using.
Given that the most accurate model may be the product of a non-explainable procedure like DNNs, boosting, or large ensembles, how can most of this accuracy be retained in a vastly simplified explainable decision tree or GLM model?
The manual procedure in use for some time in regulated industries is to take the scoring from the complex more accurate model, along with its enhanced understanding of and engineering of variables, and use this to train an explainable simplified model. Some of the accuracy will be lost but most can be retained.
Tazi takes this a step further. Understanding that the company’s data science team is one thing but users are another, they have created a Citizen Data Scientist / LOB Manager / Analyst presentation layer containing the simplified model which these users can explore and actually manipulate.
Tazi elects to visualize this mostly as sunburst diagrams that non-data scientists can quickly learn to understand and explore.
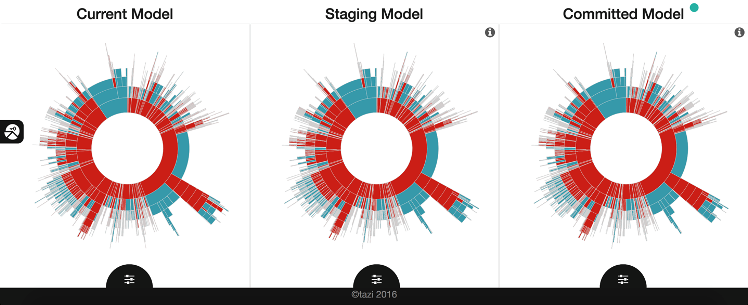
Finally, the sunburst of the existing production model is displayed next to the newly created proposed model. LOB users are allowed to actually manipulate and change the leaves and nodes to make further intentional tradeoffs between accuracy and explainability.
Perhaps most importantly, LOB users can explore the importance of variables and become comfortable with any new logic. They also can be enabled to directly approve and move a revised model into production if that’s appropriate.
This separation of the data science layer from the explainable Citizen Data Scientist layer is one of Tazi’s most innovative contributions.
Implementation by API or Code
Production scoring can occur via API within the Tazi platform or Scala code of the model can be output. This is particularly important in regulated industries that must be able to roll back their systems to see how scoring was actually occurring on some historical date in question.
Active, Human-in-the-Loop Learning
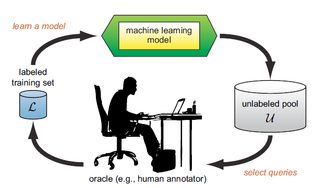 Review and recoding of specific scored instances by human workers, also known as active learning, is a well acknowledged procedure. Crowdflower for example has built an entire service business around this, mostly in image and language understanding.
Review and recoding of specific scored instances by human workers, also known as active learning, is a well acknowledged procedure. Crowdflower for example has built an entire service business around this, mostly in image and language understanding.
However, the other domain where this is extremely valuable is in anomaly detection and the correct classification of very rare events.
Tazi has an active learning module built directly into the platform so that specified questionable instances can be reviewed by a human and the corrected scoring fed back into the training set to improve model performance. This eliminates the requirement of extracting these items to be reviewed and moving them on to a separate platform like Crowdflower.
This semi-supervised learning is a well acknowledged procedure in improving anomaly detection.
Like the Swiss Army Knife – Nicely Integrated
There is much to like here in how all these disparate elements have been brought together and integrated. It doesn’t necessarily take a break through in algorithms or data handling to create a new generation. Sometimes it’s just a well thought out wide range of features and capabilities, even if there’s no corkscrew.
Previous articles on Automated Machine Learning
More on Fully Automated Machine Learning (August 2017)
Automated Machine Learning for Professionals (July 2017)
Data Scientists Automated and Unemployed by 2025 – Update! (July 2017)
Data Scientists Automated and Unemployed by 2025! (April 2016)
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
){kind=link}