

One of the follow up topics from my original blog “Feature 01 – Are Features the new Data?”was defining what makes something an Asset and how does that definition map to how we manage and value Features. But first, a framing perspective on asset valuation models courtesy of Adam Smith and his seminal book “The Wealth of Nations” written in 1776 (sort of a big year in the world).
In “The Wealth of Nations”, Adam Smith discusses how organizations attribute “value.”
The word VALUE has two different meanings, and sometimes expresses the utility of some particular object, and sometimes the power of purchasing other goods which the possession of that object conveys. The one may be called ‘value in use;’ the other ‘value in exchange.’
Or as I explain to my students:
- “Value in exchange” is an accounting-based valuation methodology in that the value of an asset is determined by what you or someone else is willing to pay for that asset.
- “Value in use” is an economics-based asset valuation methodology in that the value of an asset is determined by what additional value one can create from the use of that asset.
I use a simple example in class to help explain the difference between the accounting “value in exchange” versus economic “value in use” asset valuation methods. That example revolves around understanding the accounting versus economic valuations of a $30,000 car from the perspectives of me (a normal car owner) versus an Uber Driver (Figure 1).
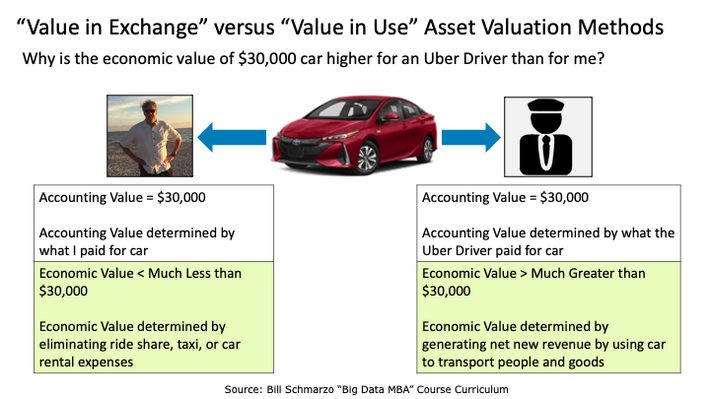
Figure 1: “Value in Exchange” versus “Value in Use” Asset Valuation Methods
For both me and the Uber Driver, the accounting value of a $30,000 car is $30,000 (the “value in exchange” for cash). That is the value of the car as reflected on both of our balance sheets.
However, the economic value of the $30,000 car differs greatly between me and the Uber Driver.
- For me, the economic value of the car is far less than $30,000 because my only “value creation” activities are reflected by eliminating taxis, ride share, or car rental expenses.
- For the Uber driver, however, the economic value is much greater than $30,000 (the value created in using the asset) because the Uber Driver can use the car to generate net new revenue (transporting people and goods, leasing the car to other Uber drivers)[1].
What is an Asset?
Accounting assets are defined as any resource 1) owned and/or controlled by a business entity, 2) can be used to produce positive financial value, and 3) represent value of ownership that can be converted into cash.
Economic assets, as defined by the OECD (Organization for Economic Co-operation and Development), are entities functioning as stores of value and over which ownership rights are enforced by institutional units, individually or collectively, and from which economic benefits may be derived by their owners by holding them, or using them, over a period of time (the economic benefits consist of primary incomes derived from the use of the asset).
So now that we have set the stage, let’s get back to the question at hand: Are Features an Economic Asset?
Are Features an Economic Asset?
As a reminder, Features[2] are a higher-level data construct created by mathematically transformations of curated data elements that ML models use during training and inference to make predictions.
Based upon the OECD definition of Economic Assets as entities from which economic benefits may be derived by their owners, I’d say that Features are certainly an Economic Asset in their ability to derive economic benefits from use of features in areas such as increase revenues/sales, decrease costs/expenses, optimize asset utilization, reduce risks, improve operational effectiveness, increase customer satisfaction, improve employee satisfaction, reduce environmental impact, and/or improve society / diversity impact (Figure 2).

Figure 2: “How Do Economic Assets Create Value?” from the “Big Data MBA” class
And Features, as Economic Assets, can be shared, reused, and continuously refined across an unlimited number of ML models in support of an unlimited number of business and operational use cases at near zero marginal cost, where marginal cost is defined the cost added by producing one additional unit of a product or service.
Once you have developed, validated, and operationalized the management of the feature, it can then be reused at near zero marginal cost. And these features are operationally managed by Feature Stores, which is a data repository that allows data scientists and data engineers to store, share, reuse, and continuously-refine features to accelerate their ML model development and model predictive effectiveness and accuracy.
Healthcare Example of Feature Reuse
Using the Healthcare example in Figure 3 from the blog “Features Part 2: Clarifying the Data-Features-Use Case Value Topic”, we can create and re-use (and continuously-refine) the Body Mass Index (BMI] feature as a variable in our Cardiac Risk ML Model (along with other features) to create a Cardiac Risk predictive score and then re-use that same BMI feature in our Diabetes Risk ML model (along with other features) to create a Diabetes Risk predictive Score. Yes, the BMI feature can be shared and reused across an unlimited number of ML models and healthcare industry use cases such as Cardiac Risk Prediction, COVID Risk Vulnerability Prediction, Unplanned Hospital Readmissions, and Effectiveness of Patient Care (Figure 3).
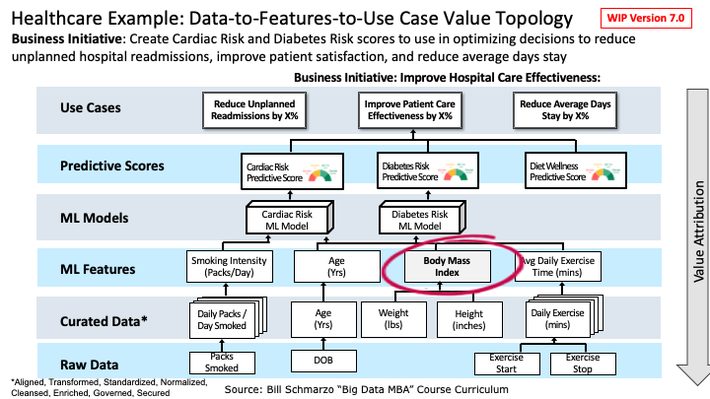
Figure 3: Healthcare Provider Example of Data-to-Features-to-Use Case Value Topology
In fact, if we don’t define and treat features as reusable economic assets, then we run the risk of different people trying to create the same feature but using different techniques and different data and data transformations yielding potentially different outcomes. This is the same problem that we see today with “orphaned analytics”, which are one-off ML models that were created to address a particular business problem, but never engineered and productized in a way to continuously track drift and upgrade performance as data and algorithms improve.
Feature Engineering Development Process
So, riddle me this Batman? How does one drive business model differentiation when every company is using the same tools, same algorithms, and same skillsets? The key is to empower the domain experts and subject matter experts in collaborating with the data science team in the feature engineering process. Teach domain experts and subject matter experts to “Think Like a Data Scientist” a methodology that embraces ideation, exploring, failing, learning, and discovering those features that are better predictors of behaviors and performance (Figure 4).
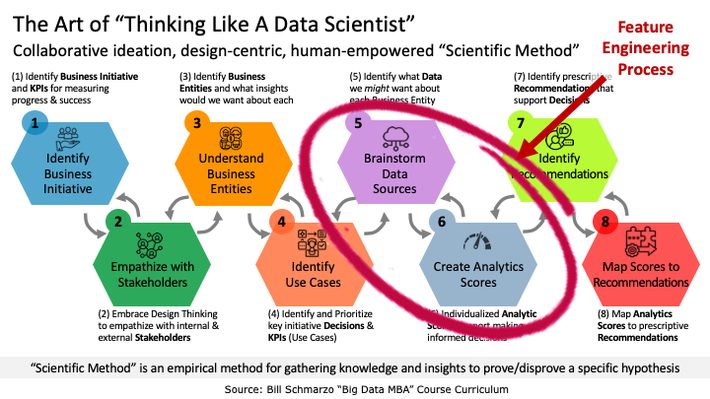
Figure 4: Feature Engineering Stage of the “Thinking Like a Data Scientist” methodology
Steps 5 and 6 (TLADS Design Template 6) of the “Thinking Like a Data Scientist” process facilitates the ideation session between domain experts / subject matter experts and the data science team to brainstorm the features (variables and metrics) against which to optimize the organization’s top priority use cases (Figure 5).
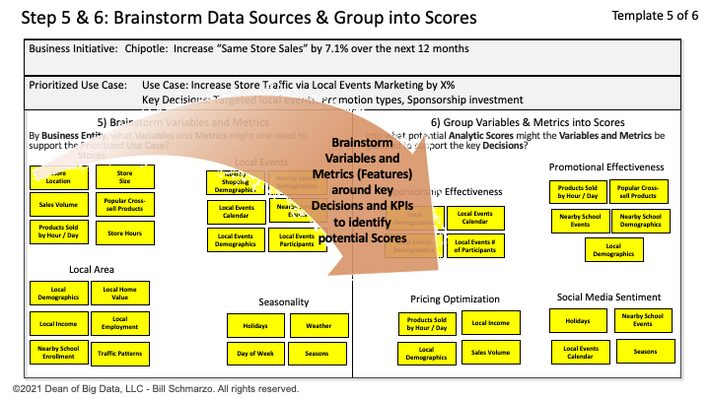
Figure 5: TLADS Template 5: Feature Engineering and Identifying Potential Analytic Scores
Features as Economic Assets Summary
So where does business model differentiation occur if everyone is using basically the same tools, same algorithms, and same skillsets? Differentiation is driven in two key areas:
- In the synergizing between the domain experts / subject matter experts and the data science team in the Feature Engineering development process in identifying and creating features that are better predictors of behaviors and performance.
- In the quality, completeness, and richness of the data that underpin the features that drive ML models predictive effectiveness.
And point #2 brings us back to the discussion why we must expand the domain of Data Management to encompass the Data Science (Feature Engineering) and Business Management (Value Engineering) domains. But more on that subject to come.
[1] The average annual Uber Driver salary in the United States is $36,702 as of September 27, 2021, but the range typically falls between $30,502 and $44,802.
[2] Note: Features are input variables or data elements used by models to make prediction (e.g., (1) women (2) under 25 (3) who smoke tobacco). Feature Selection is the process of selecting a subset of relevant features (or a feature set) for use in ML model construction.
{kind=link}