
This article was written on the blog CLOUDERA Fast Forward.
Machine learning models are used for important decisions like determining who has access to bail. The aim is to increase efficiency and spot patterns in data that humans would otherwise miss. But how do we know if a machine learning model is fair? And what does fairness in machine learning mean?
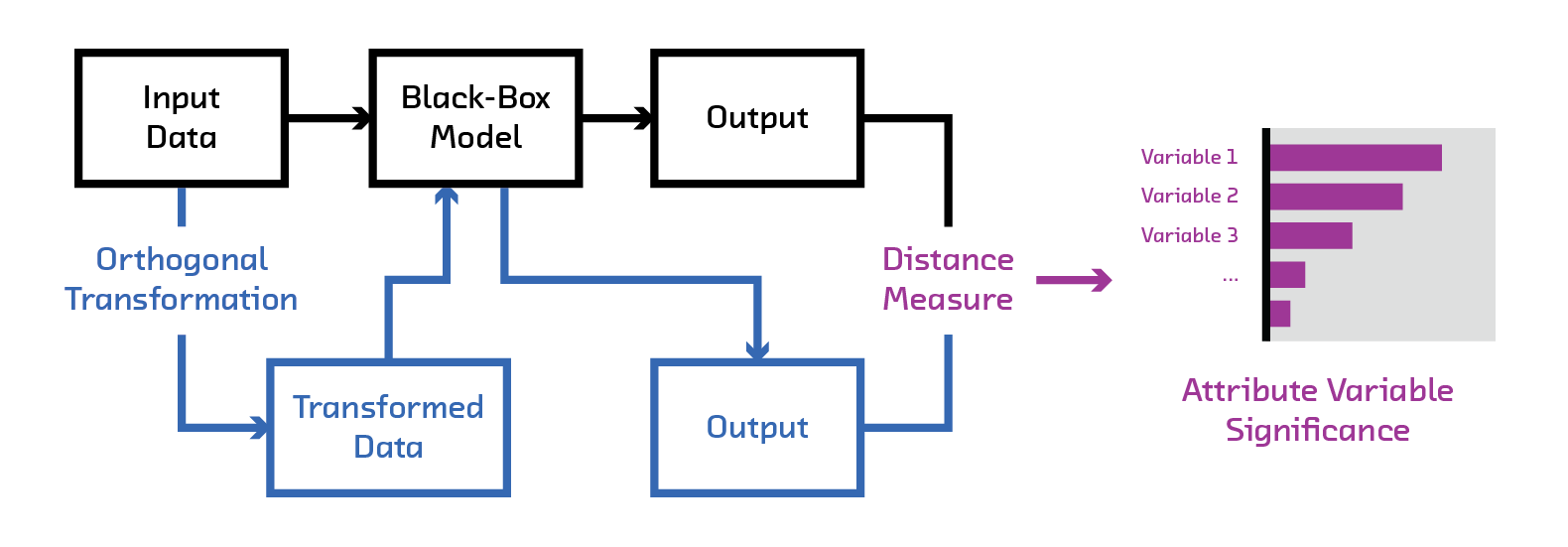
In this post, we’ll explore these questions using FairML, a new Python library that audits black-box predictive models and is based on work I did with my advisor while at MIT. We’ll apply it to a hypothetical risk model based on data collected by ProPublica in their investigation of the COMPAS algorithm. We’ll also go over the methodology behind FairML at a conceptual level and describe other work addressing bias in machine learning.
This post is a prelude to our upcoming research report and prototype on algorithmic interpretability, which we’ll release in the next few months. Understanding how algorithms use inputs to inform outputs is, in certain instances, a condition for organizations to adopt machine learning systems. This is particularly salient when algorithms are used for sensitive use cases, like criminal sentencing.
Table of contents
- Recidivism & ProPublica
- Multicollinearity and Indirect Effects
- Audit of a Proxy Model
- FairML
- FairML – Demo
- Auditing COMPAS
- Other Work
To read the whole article, with each point detailed, click here.
DSC Ressources
- Free Book and Resources for DSC Members
- New Perspectives on Statistical Distributions and Deep Learning
- Deep Analytical Thinking and Data Science Wizardry
- Statistical Concepts Explained in Simple English
- Machine Learning Concepts Explained in One Picture
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Find a Job
- Post a Blog | Forum Questions
{kind=link}