
Most of what goes by the name of Artificial Intelligence (AI) today is actually based on training and deploying Deep Learning (DL) models. Despite their impressive achievements in fields as diverse as image classification, language translation, complex games (such as Go and chess), speech recognition, and self-driving vehicles, DL models are inherently opaque and unable to explain their predictions, decisions, and actions.
This is not a critical issue for several applications (such as movie recommendation systems or news/social media feed customization, for example) where the end user will evaluate the quality of the AI based on the results it produces, make occasional adjustments to help it improve future results (e.g., by rating additional movies), or move away from that product/app. There is rarely a need to require an explanation for the AIs decisions when there is very little at stake.
However, for high-stakes situations and mission-critical applications such as self-driving vehicles, criminal justice decisions, financial systems, and healthcare applications explainability might be considered crucial. It is not enough to have an AI provide a solution, decision, or diagnosis; it is often necessary (and in some cases, absolutely essential) to explain the process behind such decisions. The emerging field of XAI (eXplainable Artificial Intelligence) addresses this need and offers several methods to provide some level of explanation to deep learning AI solutions.
In this blog post, we focus primarily on the human factors of XAI: What needs to be explained and how can this be communicated to the (human) user of an AI solution?
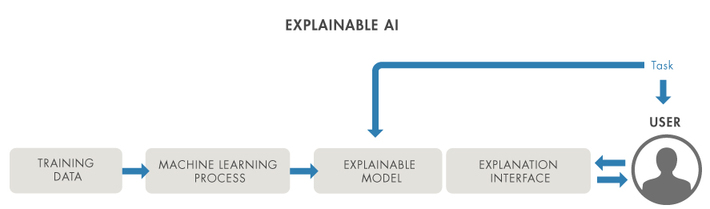
Fig 1 Human factors of XAI: an explainable model requires a suitable interface
Human Factors
Recognizing that explainability is desirable when deploying AI solutions in some areas of human activity is only the beginning. In order to understand the why and how behind an AI models decisions and get a better insight into its successes and failures, an explainable model must explain itself to a human user through some type of explanation interface (Figure 1). Ideally such interface should be rich, interactive, intuitive, and appropriate for the user and task.
In the field of image classification, a common interface for showing the results of XAI techniques consists of overlaying the explanation (usually in the form of a heat map or saliency map) on top of the image. This can be helpful in determining which areas of the image the model deemed to be most relevant for its decision-making process. It can also assist in diagnosing potential blunders that the DL model might be making, producing results that are seemingly correct but reveal that the model was looking at the wrong places. Classical examples include the husky vs. wolf image classification algorithm that was, in fact, a snow detector, and an image classification solution where the tench, a large fish species, is often identified by human fingers.
In radiology, there is a well-known case where models used to detect pneumonia in chest X-rays had learned to detect a metal token that radiology technicians place on the patient in the corner of the image field of view at the time they capture the image, which in turn identiï¬ed the source hospital, causing the models to perform well in images from the hospital they were trained on, and poorly in images from other hospitals with diï¬erent markers.
XAI is often presented as an all-or-nothing addition to regular AI, leading to potentially false dichotomies such as the trade-offs between accuracy and explainability (which suggests that in order to get more of one you must sacrifice the other, which is not universally true) or vague questions based on abstract scenarios, such as Would you pay more for AI that explains itself (and performs at the same level as the baseline solution)?
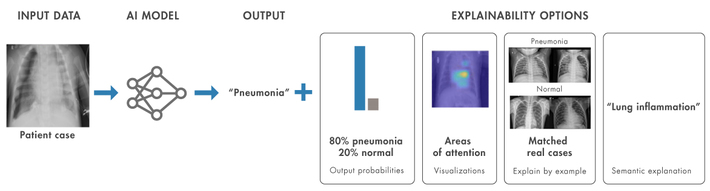
Fig 2 XAI as a gradual approach: in addition to the models prediction, different types of supporting information can be added to explain the decision.
We choose to see explainability as a gradual process instead (Figure 2), where an AI system that predicts a medical condition from a patients chest x-ray might use gradually increasing degrees of explainability: (1) no explainability information, just the outcome/prediction; (2) adding output probabilities for most likely predictions, giving a measure of confidence associated with them; (3) adding visual saliency information describing areas of the image driving the prediction; (4) combining predictions with results from a medical case retrieval (MCR) system and indicating matched real cases that could have influenced the prediction; and (5) adding computer-generated semantic explanation.
Popular XAI Methods
There is no universally accepted taxonomy of XAI techniques. In this blog post we use the categorization of the field adopted by the authors of a recent survey paper on the topic, which breaks down the field into scope, methodology and usage, as follows:
- Scope: Where is the XAI method focusing on?
- The scope could be local (where the focus is on individual data instances) or global (where the emphasis is on trying to understand the model as a whole).
- Methodology: What is the algorithmic approach?
- The algorithm could focus on: (a) gradients back-propagated from the output prediction layer to the input layer; or (b) random or carefully chosen changes to features in the input data instance, also known as perturbations.
- Usage: How is the XAI method developed?
- Explainability might be intrinsic to the neural network architecture itself (which is often referred to as interpretability) or post-hoc, where the algorithm is applied to already trained networks.
Some post-hoc XAI algorithms have become popular in recent years, among them Grad-CAM (Gradient-weighted Class Activation Mapping) and LIME (Local Interpretable Model-agnostic Explanation). Grad-CAM is gradient-based, has local scope, and can be used for computer vision tasks. LIME is perturbation-based, has both local and global scope, and can be used with images, text, or tabular data.
An example
Here is an example of how to use MATLAB to produce post-hoc explanations (using Grad-CAM and image LIME) for a medical image classification task, defined as follows:
Given a chest x-ray (CXR), our solution should classify it into Posteroanterior (PA) or Lateral (L) view.
The dataset (PadChest) can be downloaded from https://bimcv.cipf.es/bimcv-projects/padchest/ .
Both methods (gradCAM and imageLIME) are available as part of the MATLAB Deep Learning toolbox and require a single line of code to be applied to results of predictions made by a deep neural network (plus a few lines of code to display the results as a colormap overlaid on the actual images).
Figures 3 and 4 show representative results. The Grad-CAM results (Fig 3) suggest that the network is using information from the borders and corners of the image to make a classification decision. The LIME results (Fig 4) tell a rather different story. In both cases, we are left wondering: to what extent did either method help explain the models decision?
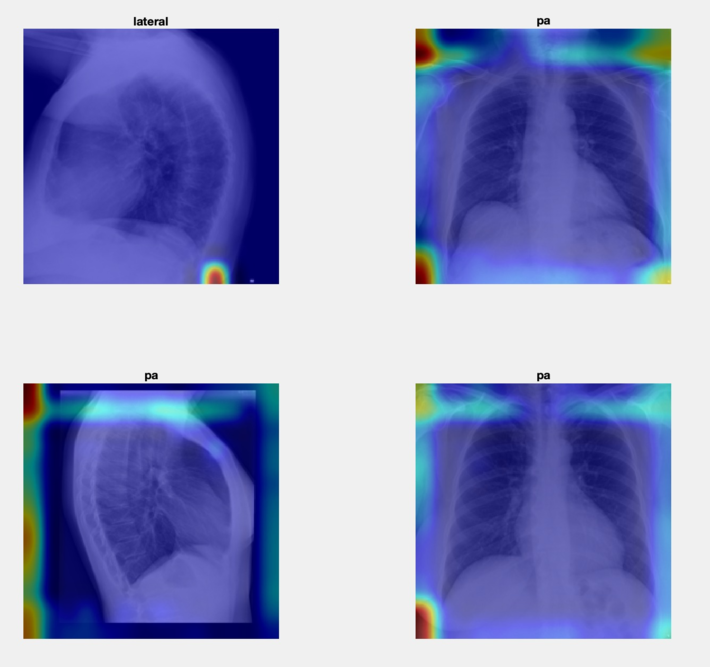
Fig 3 Example of result: Grad-CAM for CXR classification task.
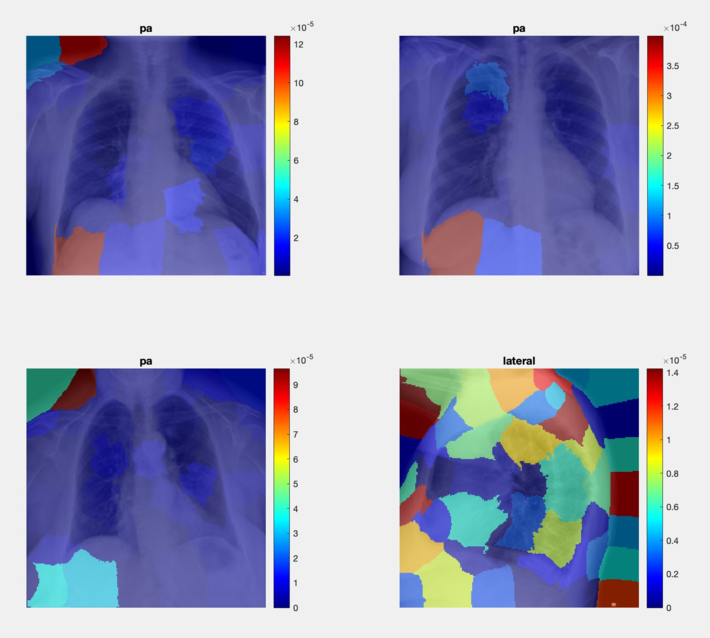
Fig 4 Example of result: image LIME for CXR classification task.
Another example
Here is another example where we applied Grad-CAM and image LIME to results of a binary skin lesion classifier.
Figures 5 and 6 show representative results. They are organized in a confusion matrix-like fashion (with one case each of true positive (TP), true negative (TN), false positive (FP), and false negative (FN)). They reveal fascinating aspects (and limitations) of these post-hoc techniques:
- For easy images (such as the true positive on the bottom-right corner), both techniques perform extremely well and suggest that the model was looking at the right place within the image
- For the false positive on the bottom-left corner, both techniques show that the model learned the ruler on the left-hand-side of the image (in addition to taking into account aspects from the lesion region as well), which might have explained the incorrect prediction
- For the images on the top row, both techniques suggest that the insights are not as clear (at least to a layperson) as the images on the bottom row; one of the problematic aspects of these post-hoc techniques is actually exemplified here, since they are equally comfortable explaining correct as well as incorrect decisions in a similar way.
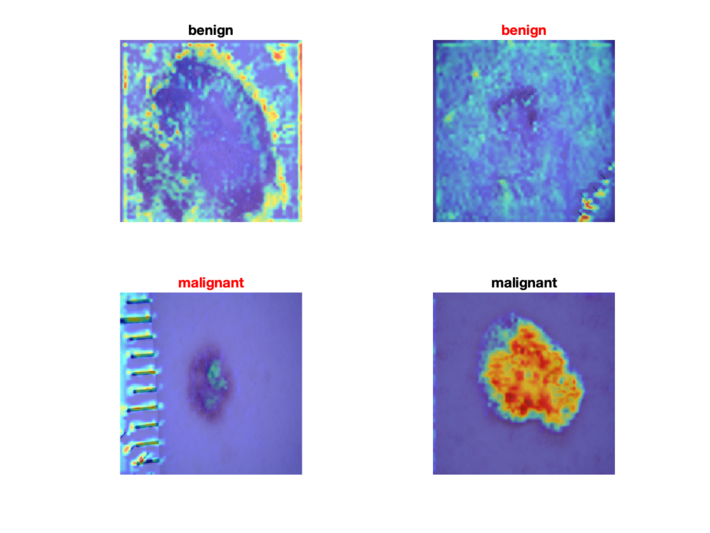 Fig 5 Example of result: Grad-CAM for skin lesion classification task.
Fig 5 Example of result: Grad-CAM for skin lesion classification task.
 Fig 6 Example of result: image LIME for skin lesion classification task.
Fig 6 Example of result: image LIME for skin lesion classification task.
Key takeaways
Deep Learning models are opaque and, consequently, have been deemed inadequate for several applications (since usually they can make predictions without explaining how they arrived at the result, or which factors had greater impact). Explainable AI (XAI) techniques are possible ways to inspire trust in an AI solution.
In this blog post we have used MATLAB to show how post-hoc explanation techniques can be used to show which parts of an image were deemed most important for medical image classification tasks. These techniques might be useful beyond the explanation of correct decisions, since they also help us identify blunders, i.e., cases where the model learned the wrong aspects of the images.
XAI is an active research area, and new techniques and paradigms are likely to emerge in the near future. If youre interested in learning more about XAI and related issues, see the recommended resources below.
Learn more about it
- Interpretable Machine Learning: A Guide for Making Black Box Models…, by Christoph Molnar
- Interpretable AI: Building explainable machine learning systems, by Ajay Thampi
- Explainable AI: A Review of Machine Learning Interpretability Methods, by Pantelis Linardatos, Vasilis Papastefanopoulos and Sotiris Kotsiantis
- Opportunities and Challenges in Explainable Artificial Intelligence…, by Arun Das and Paul Rad
- Understand the mechanics behind black box machine learning model … (MathWorks)
- Introduction to AI Explanations for AI Platform (Google)
- A Visual History of Interpretation for Image Recognition, by Ali Abdalla
- UNPIC (understanding network predictions for image classification) (MathWorks)
{kind=link}