
The development of machine learning and deep learning solutions typically follows a workflow that starts from the problem definition and goes through the crucial steps of collecting and exploring useful data, training and evaluating candidate models, deploying a solution, and finally documenting and maintaining the system once it is running in the wild (Figure 1). Despite its predictable structure, some steps of this process are iterative by nature and usually require multiple rounds of adjustments, fine-tuning, and optimizations.
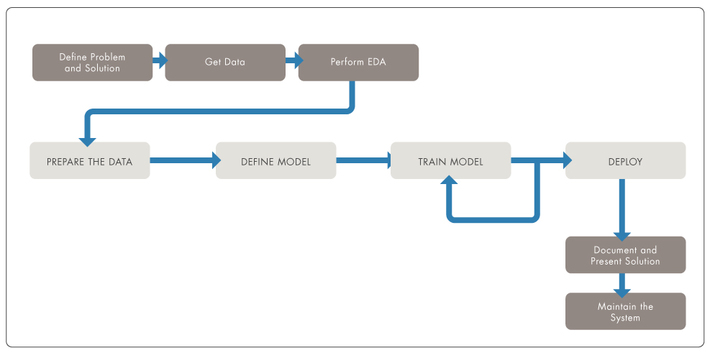
Fig 1 Typical machine learning / deep learning workflow.
In this blog post we look at the process of running multiple machine learning experiments while searching for the best solution for a given problem and discuss the need to document the process in a structured way. Such structured documentation can provide multiple benefits, among them:
- A better understanding of the problem, the models created to solve it, and the associated data set(s) used for training, validating, and testing the model.
- Improved communication among team members working on the same project, so that everyone can easily check what has been attempted and how well it worked.
- Assurance of reproducibility of results, a hallmark of responsible research.
We will discuss the Why, What and How of managing experiments and then well walk through an example of what this looks like in a real-world example.
Why document & track experiments?
Machine learning (ML) and deep learning (DL) involve a fair amount of trial and error regardless of the task (regression, classification, prediction, segmentation), choice of model architecture, and size or complexity of the associated data set. A ML/DL practitioner often must run multiple experiments to test hypotheses, select models, finetune hyperparameters, and compare different metrics.
Effective experiment management strategies should supplement good software documentation techniques such as logs, audit trails, and Git commits, since the latter are often insufficient when your goal is to piece together the experimental conditions that resulted in the deployment of a specific version of a model.
Proper experiment management can effectively address multiple aspects of the workflow, such as data set versioning, model versioning, model optimization, and detailed experiment tracking, which leads to better communication, improved collaboration, and assurance of reproducibility of results. By doing so, researchers and developers are also adhering to some of the key principles of responsible ML.
What needs to be tracked?
In this blog post we focus on experiment tracking. We can think of a machine learning experiment (Figure 2) as a systematic way to answer to the question: Which model performs best for my application?
Experiments manipulate variables, which are factors that can be selected by the experimenter in order to observe their effect on the performance of the solution.
Variables can be organized into variable sets which can be used to document choices, such as baseline model, optimizer, loss function, number of epochs, batch size, learning rate, metrics, and other hyperparameters.
Example variable sets could be:
{model: ‘ResNet50’, optimizer: ‘adam’, loss: ‘mse’, epochs: 200, batch_size: 128,
lr: 0.001, metrics: [‘auc’, ‘precision’, ‘recall’]}
and
{model: ‘alexnet’, optimizer: ‘RMSProp’, loss: ‘CategoricalCrossEntropy’, epochs: 400,
batch_size: 64, lr: 0.01, metrics: [‘accuracy’, ‘sensitivity’, ‘specificity’]}
Each experiment consists of a collection of trials, which are essentially training and validation iterations using a specific variable set.
In addition to (trial-specific) variable sets, an experiment typically contains many components that are common to all trials (e.g., data set, common hyperparameters, preprocessing scripts, data augmentation options, and any other type of metadata, such as job parameters (CPU, GPU, instance type), experiment/trial/job names, checkpoints, file and data set locations, among others), which should be documented once per experiment.
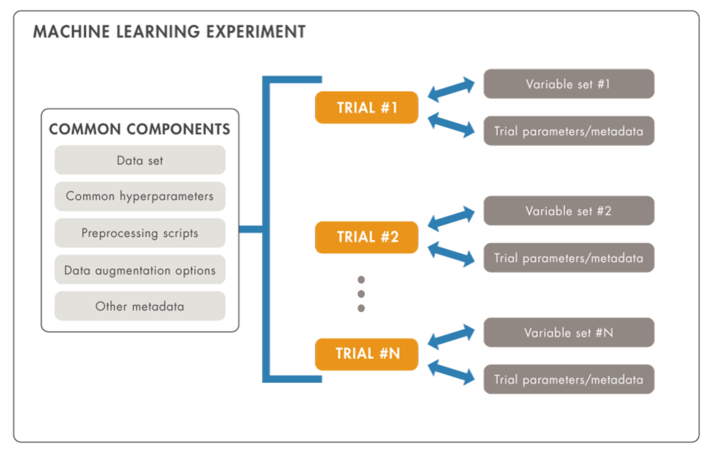
Fig 2 A ML experiment consists of several trials with different variable sets.
Common components are shared among all trials for the same experiment.
How to document & track using existing tools
Traditionally, keeping track of lab experiments can be done using a lab notebook or its electronic equivalent (e.g., a spreadsheet). This is a tedious, cumbersome, and error-prone procedure, which has led many researchers and developers to build their own databases and write customized scripts to automate frequent tasks. For those who want to manage their machine learning experiments without having to write their own scripts, there are several options currently available to streamline the process.
When looking for a tool to assist you with managing ML/DL experiments, you probably expect the selected tool to be visually rich (and yet intuitive and easy to use), highly interactive (e.g., providing options for customizing your views as well as sorting, filtering, and annotating results of your experiments), and capable of handling different computing setups, from single-CPU to multi-GPU, from local to cloud. MATLAB Experiment Manager meets these requirements.
An example
Here is an example of how to use MATLAB Experiment Manager for a medical image classification task.
- Experiment objective: to test the best combination of pretrained deep learning model and optimizer for a binary (malignant or benign) skin lesion classification task using transfer learning.
- Common components:
- Data set: annotated images from the ISIC 2016 challenge, Task 3 (Lesion classification) data set, consisting of 900 dermoscopic lesion images in JPEG format for training and validation, distributed in two classes (727 images were labeled as benign, 173 as malignant) plus 379 test images of the exact same format as the training data, and associated ground truth for all images.
- Common hyperparameters:
- Data set partition (e.g., 70% for training, 30% for validation)
- Loss function
- Mini-batch size
- Initial learning rate
- Learning rate schedule
- Number of epochs
- Validation patience
- Validation frequency
- Performance metrics
- Preprocessing scripts
- Image resizing (to the size expected by the input layer of each model)
- Image augmentation (e.g., translation, scaling and rotation)
- Variable sets: a total of nine (3 x 3) combinations of:
- Model: ResNet-18, GoogLeNet or SqueezeNet
- Optimizer: ‘adam’, ‘sgdm’, or ‘rmsprop’
The Experiment Manager apps UI makes it very easy and intuitive to set up an experiment and provides shortcuts to common options (Figure 3) that take the user to a Live Editor containing a template function for that type of experiment. Experiments are associated with Projects, another elegant (and relatively recent) way by which MATLAB users can organize their code and associated data, check dependencies, implement source control, and share their code on GitHub, among many other options.
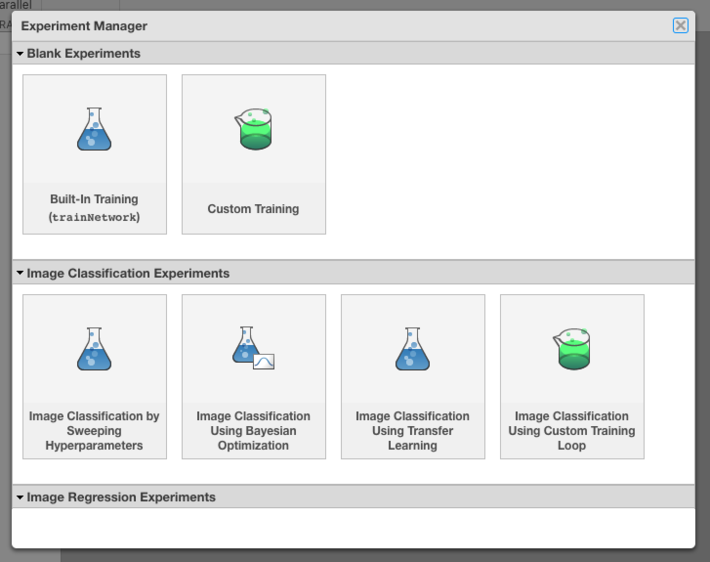
Fig 3 MATLAB Experiment Manager: selecting the type of experiment.
After editing the template for the experiment setup function and configuring the variable sets (which are passed as parameters to the setup function, see Figure 4), we can press a button and let the experiment run. At the end of the experiment, a highly customizable summary screen displays the results of each trial (as well as associated training plots and confusion matrices) and provides options for sorting, annotating, and exporting relevant results (Figure 5).
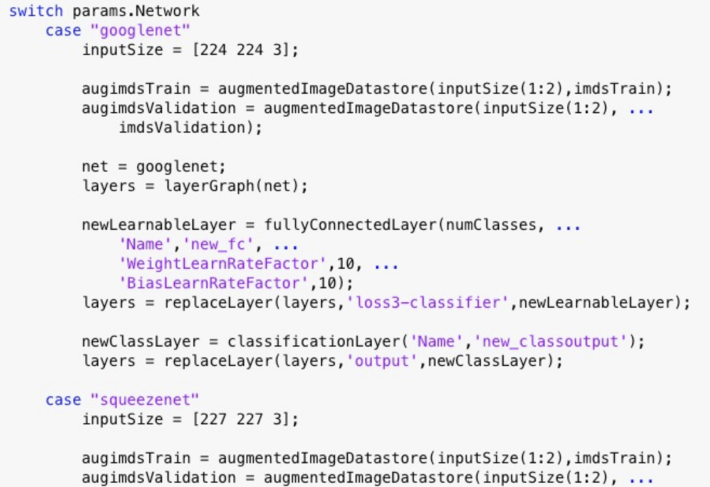
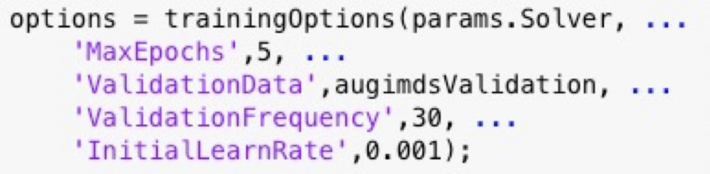
Fig 4 Example of using params (a structure with fields from the Experiment Manager hyperparameter table) in the experiment setup function: in this case the fields are Network and Solver.
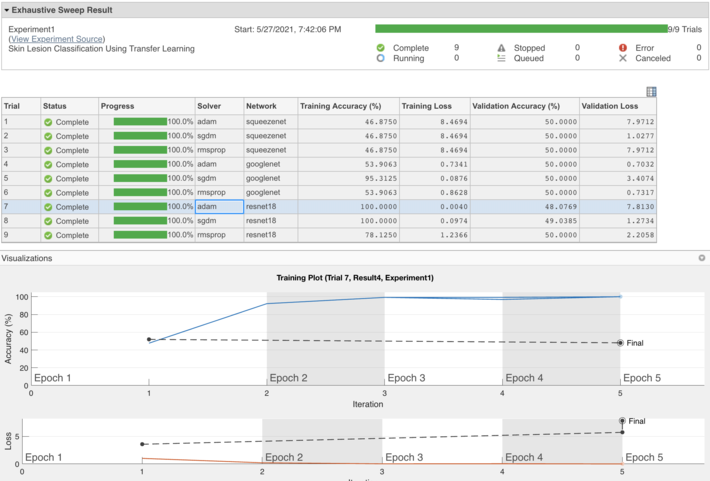
Fig 5 MATLAB Experiment Manager screenshot showing the hierarchy of projects, experiments, and trials (left), hyperparameters associated with the trial (top center), summary of results of 9 trials (top right) and learning curves for one of them (bottom), indicating a classic case of overfitting (perfect performance on the training set, but unable to generalize to the validation set).
Key takeaways
A ML/DL practitioner often must run multiple experiments and trials to select and finetune models, test hypotheses, compare different metrics, refine ideas, and try new approaches. Documenting every experiment is absolutely essential. This is not an easy task, but MATLAB Experiment Manager app can help!
In this blog post we have shown how to use Experiment Manager for a skin lesion image classification task. Thanks to the Experiment Manager app you can ensure that your results can be reproduced by other people, trace back some steps of your experimental process, select best options for hyperparameters, compare and select different solutions for the same problem, and much more, in an elegant, project-oriented, self-contained, and user-friendly way.
The best way to learn more about the Experiment Manager app is to practice! You might want to check out the code for the example and use it as a starting point for your own explorations. Good luck on your journey!
{kind=link}