
Summary: If Deep Learning is powered by 2nd generation neural nets. What will the 3rd generation look like? What new capabilities does that imply and when will it get here?
By far the fastest expanding frontier of data science is AI and specifically the rapid advances in Deep Learning. Advances in Deep Learning have been dependent on artificial neural nets and especially Convolutional Neural Nets (CNNs). In fact our use of the word “deep” in Deep Learning refers to the fact that CNNs have large numbers of hidden layers. Microsoft recently won the annual ImageNet competition with a CNN comprised of 152 layers. Compare that with the 2, 3, or 4 hidden layers that are still typical when we use ordinary back-prop NNs for traditional predictive analytic problems.
Two things are happening.
- First, CNNs have come close to achieving 100% efficiency for image, speech, and text recognition. Now that there are industrial strength platforms for CNNs we are in the age of exploitation where these features are rapidly being incorporated in the apps we use every day.
- Second, we are rapidly recognizing the limitations of CNNs which are 2nd generation neural nets, and we’re ready to move on to 3rd generation and eventually 4th gen neural nets. Needless to say, 3rd gen NNs didn’t get started yesterday. It’s research that’s been ongoing for some years and will still take a year or three to become mainstream. We want to share a little of what you can expect.
What’s Wrong with CNNs?
The limitations of CNNs have been understood for some time but we’ve been getting such good returns for the last two years it’s been easy to overlook them.
- Need too Much Data. CNNs are not One-Shot Learners: They require massive amounts of tagged training data which is in short supply and expensive to produce. There are a large number of tuning parameters that need to be adjusted by a data scientist that makes the set up long and labor intensive. Even the fitness functions are complex although they rely on common gradient descent logic.
- They Can’t Extract Meaning and They Can’t Remember: CNNs are basically just very good classifiers. Is that a cat – yes or no? It can’t remember patterns that it may have recently developed elsewhere and apply them to the new data set. If you asked a CNN-enabled robot “please get me something to eat with” or “please get me a knife and fork” it cannot recognize that these are essentially the same question.
- They are Supervised Learners: With the exception of recent advances made in Adversarial Learning CNNs need labeled examples and lots of them.
- Need Faster and More Powerful Machines: All those layers need ever faster chips on ever larger MPP clusters. If you scan the literature on Deep Learning you’ll immediately see that the great majority of it is about advances and investments in new and exotic chips. For Intel and their competitors this is a goldmine. There’s a virtual arms race going on to build chips that are ever-faster-ever-cheaper for CNNs.
Where Are 3rd and 4th Gen NNs Coming From?
The simple answer is academia but the more interesting answer is from brain research. AI that mimics the way the brain functions is labeled ‘strong’ AI, while AI that doesn’t worry too much about the exact model but gets the same results is called ‘weak’. We recently argued that since the ‘weak’ school has been in transcendence with CNNs that we should find a more dignified and instructive name like ‘engineered’ AI.
 What’s most revealing about 3rd and 4th gen NNs is that they are coming from the very research labs that are attempting to reveal exactly how neurons and synapses collaborate within the brain. What was very slow progress for a long time is now experiencing major breakthroughs.
What’s most revealing about 3rd and 4th gen NNs is that they are coming from the very research labs that are attempting to reveal exactly how neurons and synapses collaborate within the brain. What was very slow progress for a long time is now experiencing major breakthroughs.
There are many of these modeled-brains underway and if you’d like to see a very impressive demonstration, actually from 2013, see this YouTube video of ‘Spaun’ created by Chris Eliasmith at the University of Waterloo that remembers, and learns unsupervised from its environment.
So the ‘strong’ school looks like it is not only making a comeback but will in fact dominate in the future. We’ll describe the 3rd gen in a minute. The 4th gen that doesn’t yet exist does already have a name. These will be ‘neurophasic’ nets or more likely just brains on a chip.
3rd Gen Spiking Neural Nets (SNNs)
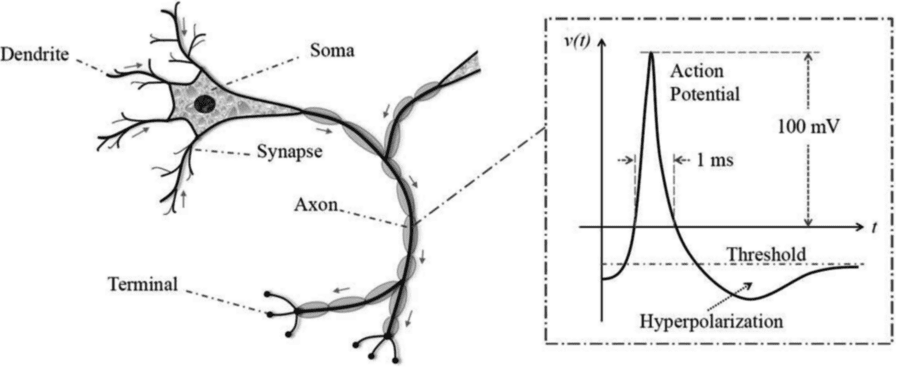
Spiking Neural Nets (SNNs) (also sometimes called Oscillatory NNs) are being developed from an examination of the fact that neurons do not constantly communicate with one another but rather in spikes of signals. We all have heard of alpha waves in the brain and these oscillations are only one manifestation of the irregular cyclic and spiking nature of communication among neurons.
So if individual neurons are activated only under specific circumstances in which the electrical potential exceeds a specific threshold, a spike, what might be the implication for designing neural nets? For one, there is the fundamental question of whether information is being encoded in the rate, amplitude, or even latency of the spikes. It appears this is so.
The SNNs that have been demonstrated thus far show the following characteristics:
- They can be developed with far fewer layers. If nodes only fire in response to a spike (actually a train of spikes) then one spiking neuron could replace many hundreds of hidden units on a sigmoidal NN.
- There are implications for energy efficiency. SNNs should require much lower power than CNNs.
- You could in theory route spikes like data packets further reducing layers. It’s tempting to say this reduces complexity and it’s true that layers go away, but are replaced by the complexity of interpreting and directing basically noisy spike trains.
- Training SNNs does not rely on gradient descent functions as do CNNs. Gradient descent which looks at the performance of the overall network can be led astray by unusual conditions at a layer like a non-differentiable activation function. The current and typical way to train SNNs is some variation on ‘Spike Timing Dependent Plasticity’ and is based on the timing, amplitude, or latency of the spike train.
What we can observe in the early examples is this:
- They can learn from one source and apply it to another. They can generalize about their environment.
- They can remember. Tasks once learned can be recalled and applied to other data.
- They are much more energy efficient which opens a path to miniaturization.
- They learn from their environment unsupervised and with very few examples or observations. That makes them quick learners.
- Particularly interesting in the Spaun demo mentioned above, it makes the same types of mistakes at the same frequency as human learners. For example, when shown a long series of numbers and asked to recall them, the mistakes tended to be in the middle of the series. Experimentally this is exactly what would happen with human learners. This implies that the SNNs in Shaun are in fact closely approximating human brain function.
A final example from a local stealth-mode startup using advanced SNNs. When the SNN was shown a short video of cars moving on a highway it rapidly evolved a counting function. It wasn’t told what its purpose was. It wasn’t told what a car looked like. The images (the data) were moving in an organized but also somewhat chaotic manner. A few minutes later it started to count.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}