
Summary: The most important developments in Deep Learning and AI in the last year may not be technical at all, but rather a major change in business model. In the space of about six months all the majors have made their Deep Learning IP open source, hoping to gain on the competition from the power of the broader developer base and wide adoption.
 To say that the last year has been big for Deep Learning is an understatement. There have been some spectacular technical innovations like Microsoft winning the ImageNet competition with a neural net comprised of 152 layers (where 6 or 7 layers is more the norm). But the big action especially in the last six months has been in the business model for Deep Learning.
To say that the last year has been big for Deep Learning is an understatement. There have been some spectacular technical innovations like Microsoft winning the ImageNet competition with a neural net comprised of 152 layers (where 6 or 7 layers is more the norm). But the big action especially in the last six months has been in the business model for Deep Learning.
Suddenly, and I do mean suddenly, all of the majors including Amazon, IBM, Google, Facebook, Twitter, Baidu, Yahoo, and Microsoft have made their code open source and available to anyone. And Google has even offered the use of part of its here-to-fore proprietary deep learning TensorFlow AI for free to it commercial customers.
Between the end of 2015 and this last month all of the following are now open source.
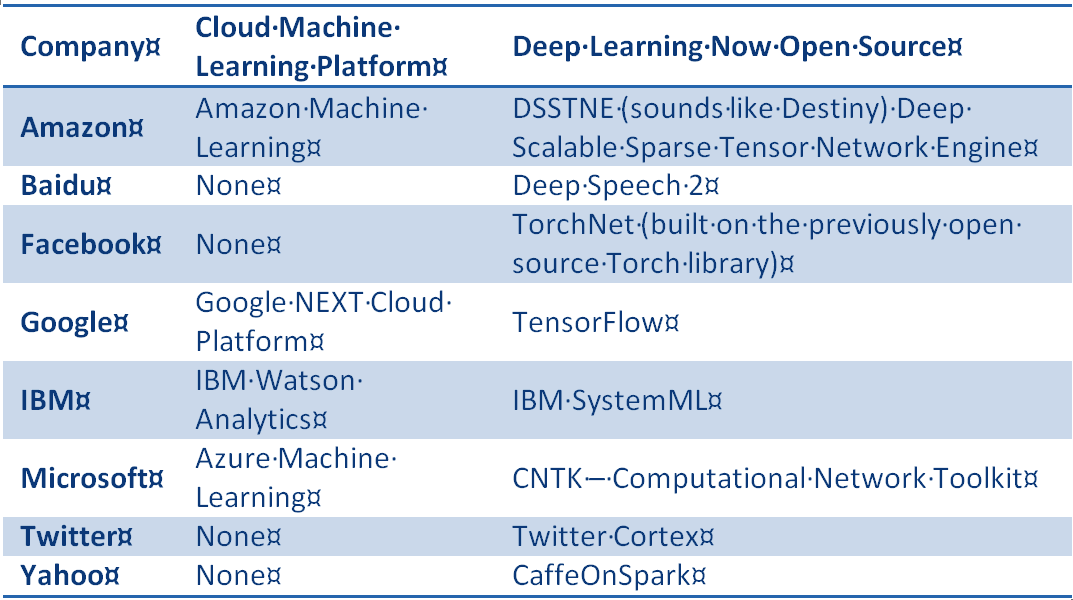
So if you are developer and willing to put in the time on the open source code, or a Google commercial customer, all of this incredible IP is indeed yours for the taking (subject to open source licensing, etc., etc.)
What’s driving this? Why the major change in direction? It’s as though our most advanced and magical techniques are now promotional giveaways. And that’s partially true, but there are several different drivers.
It’s About Dominating the New Industries and Applications that are Being Built from Deep Learning
 Of the eight companies shown above, some are cloud platform providers with a desire to expand their customer base, but some, and including some of the cloud folks, are digital enterprises where deep learning is the next big enabler of growth.
Of the eight companies shown above, some are cloud platform providers with a desire to expand their customer base, but some, and including some of the cloud folks, are digital enterprises where deep learning is the next big enabler of growth.
Deep Learning is at the core of image recognition and auto labeling, text to speech, speech to text, auto translation, and sentiment analysis. It also is beginning to be used in recommenders (Amazon at the forefront) and for anomaly detection such as transaction fraud. So it’s easy to see why each of these companies would regard Deep Learning as a critical, almost existential capability.
These applications for text and image search and classification, as well as Amazon’s application to shopping recommenders are intuitively obvious for these major players. What is less so is that whoever can develop the most widely embraced Deep Learning AI platform also stands to dominate all the new niche applications, including those not yet imagined.
As with traditional advanced analytic algorithms the foundations were laid in academia. There are at least 50 different Deep Learning tool sets available and most are already open source. Over the last five years or so this has attracted a number of startups also aspiring to build the perfect AI platform. However, the dominance of the major players probably signals that this opportunity for independent platform development is over, except perhaps as takeover targets.
Take for example the fate of Ersatz Labs, a startup in Pacifica, Calif., that had invested heavily in a market-ready Deep Learning AI platform. Last year, after failing to find additional funding Dave Sullivan, the company’s CEO, pointed to the difficulties of selling services or products that enable people to do deep learning when many of those people work for large tech companies that prefer building their own tools and hiring internally.
“Everyone’s waiting for that killer app in deep learning right now, and nobody has figured it out yet,” Sullivan says. “It’s not platforms though.”
It’s About Dominating Cloud Services
 For Amazon, Microsoft, and Google it all about the competition for customers of their cloud services. Each of these players is planning to earn a very significant portion of revenues from cloud services but Google has been lagging behind.
For Amazon, Microsoft, and Google it all about the competition for customers of their cloud services. Each of these players is planning to earn a very significant portion of revenues from cloud services but Google has been lagging behind.
Forrester Research recently estimated $10.8 billion in cloud revenues for Amazon this year, $10.1 billion for Microsoft but only $3.9 billion for Google. This brings us to the great Deep Learning giveaway.
As reported in the 7/20/16 WSJ, Google just announced free access to two of its main AI TensorFlow offerings, one for sentiment analysis and the other for speech to text. Speech to text, translation, and interpretation (sentiment analysis) have been difficult problems for large B2C companies to overcome. Google quoted one example in which a large customer was able to analyze more than two billion minutes of customer-service calls to understand when customers end calls satisfied and when they don’t.
Competing on AI services will be a major emphasis in Googles cloud services marketing effort.
Free may be new, but competing on AI in cloud services is not. Amazon, IBM, and Microsoft all offer similar AI suites. Google’s machine-learning offering “is great stuff, and it’s finally packaged in a way that developers really want,” Forrester Research principal analyst John Rymer said. “But they’re not alone…..and Amazon and Microsoft are far ahead.”
Google and their competitors make money from the services by charging a fraction of a cent for every request of the technology. For Google’s image-recognition function released several months ago (not free), one or two customers using it trillions of times represents a substantial revenue stream.
It’s About Scarcity of Talent and the Rate of Innovation
 Data scientists may be rare but those with expertise in Deep Learning are even more rare. For all these major players going open source helps recruit top AI talent.
Data scientists may be rare but those with expertise in Deep Learning are even more rare. For all these major players going open source helps recruit top AI talent.
As much as acquiring IP, the scarcity of talent has been behind the rapid M&A activity in this space where the acquisition of Deep Learning startups results in expanding experienced staff.
It’s interesting to note that Apple, pretty much alone among the majors continues to resist going open source and keeps its code proprietary. It’s unclear how long they will be able to hold out on their reputation alone. Open source is a field attracting both solid researchers and developers from industry and academia, but also the individual performers from whom innovation frequently arises.
Many of the world’s top AI experts come from academia, and academics are active users of open-source software. Brandon Ballinger, a former Google AI engineer who is now working with the University of California, San Francisco, on cardiology research said. “If you’re a holdout, like Apple, you’re simply not going to attract the best people.”
There’s also the practical issue that no matter how big you are, your R&D budget has limits. IBM Vice President of Development Rob Thomas says “It’s about speed and innovation. Right now, my [research and development] is limited to my R&D budget, unless we’re doing work in open source.” Acceptance of your platform by the Apache Institute as a new open source project under its guidance is a major source of credibility, user adoption, and hence innovation.
It’s About Hardware
Not in any way to diminish the genius behind creating new types of neural nets with over a hundred layers that can work on distributed systems, much of the remaining problem to be solved is about hardware. And who is more committed to massive investments in hardware than Amazon, Microsoft, Google, and IBM in their cloud services data centers.
How big is big? IBM’s Watson which is only one example employs a cluster of ninety IBM Power 750 servers, each of which uses a 3.5 GHz POWER7 eight core processor, with four threads per core. In total, the system has 2,880 POWER7 processor threads and 16 terabytes of RAM.
According to John Rennie, Watson can process 500 gigabytes per second, the equivalent of a million books, and that performance only gets you to about half as fast as the slowest computer on the Top 500 Supercomputers list.
To optimize for AI in today’s cloud service data centers requires focusing on types of chips not before common in processing, specifically GPUs (graphical processing units as in gaming consoles) and FPGAs (field programmable gate arrays – chips which can be configured for special purpose operations).
As the majors circle the problem of creating the ultimate Deep Learning platform there is a realization that there is not enough computing power to meet their aspirations.
Given this magical super-sized resource, a massive neural network could cycle through all the possible options for a solution, no matter how complex the problem, and simply settle on the best one. That’s not possible today. Use of Deep Learning still requires researchers to start with certain assumptions and work through a variety of trials.
This practice should be familiar to data scientists as hyper parameter optimization. Note that last year one of Twitter’s acquisitions was Whetlab with expertise in optimizing neural networks.
But right now data centers are not full of GPU chips or FPGAs but they will need to be to make this work. Intel has taken notice. Last summer they acquired FPGA maker Altera for $16.7 Billion clearly signaling a strong new direction in the market.
Adam Gibson, the chief researcher at deep learning startup Skymind says that deep learning has become more of “a hardware problem.” Yes, we still need top researchers to guide the creation of neural networks, but more and more, finding new paths is a matter of brute-forcing new algorithms across ever more powerful collections of hardware. As Gibson point out, although these deep neural nets work extremely well, we don’t quite know why they work. The trick lies in finding the complex combination of algorithms that work the best. More and better hardware can shorten the path.
The end result is that the companies that can build the most powerful networks of hardware are the companies that will come out ahead. Almost assuredly that will be Google, Amazon, Microsoft and very few others.
It’s About Disruptive Competition from Elon Musk
 Here’s a curious angle. It’s possible that none of this movement to open source all this IP would have occurred if not for Tesla founder Elon Musk, big-name venture capitalist Peter Thiel, LinkedIn co-founder Reid Hoffman, and several other notable tech super stars.
Here’s a curious angle. It’s possible that none of this movement to open source all this IP would have occurred if not for Tesla founder Elon Musk, big-name venture capitalist Peter Thiel, LinkedIn co-founder Reid Hoffman, and several other notable tech super stars.
At the end of 2015 this group announced its launch of a new artificial intelligence startup called OpenAI with the unique positioning that it would be a non-profit.
OpenAI rapidly gathered an impressive list of AI developer and research talent drawing from the majors, startups, and academia making it immediately competitive. According to Greg Brockman the former CTO of payments startup Stripe and now one of the top leaders in OpenAI in his recent blog post “Our goal is to advance digital intelligence in the way that is most likely to benefit humanity as a whole, unconstrained by a need to generate financial return”.
In addition to the co-chairs Musk and Thiel, other backers include Alan Kay, one of the founding fathers of the PC, and Yoshua Bengio, another top deep learning researcher. Altogether, OpenAI says, its backers have committed $1 billion to the project.
Personally, I am betting there will be some way for these very smart tech leaders to monetize this investment. An equally interesting question is would the majors have rushed for the open-source door if OpenAI had not been there?
Where to From Here?
Aside from the questions raised above there are a number we’ll need to address later. Probably chief among them is what capabilities will make one Deep Learning platform stand out above the rest? Will it be technical sophistication, ease of use, or the hardware on which it rides? That’s for another time.
What we do know is that 2016 is beginning to feel a lot like 2007 when Hadoop first went open source and commercial development took off like a rocket.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
%20Free){kind=link}