
Summary: Here are our 5 predictions for data science, machine learning, and AI for 2019. We also take a look back at last year’s predictions to see how we did.
 It’s that time of year again when we do a look back in order to offer a look forward. What trends will speed up, what things will actually happen, and what things won’t in the coming year for data science, machine learning, and AI.
It’s that time of year again when we do a look back in order to offer a look forward. What trends will speed up, what things will actually happen, and what things won’t in the coming year for data science, machine learning, and AI.
We’ve been watching and reporting on these trends all year and we scoured the web and some of our professional contacts to find out what others are thinking.
Here’s a Quick Look at Last Year’s Predictions and How We Did.
- What we said: Both model production and data prep will become increasingly automated. Larger data science operations will converge on a single platform (of many available). Both of these trends are in response to the groundswell movement for efficiency and effectiveness. In a nutshell allowing fewer data scientists to do the work of many.
Clearly a win. No code data science is on the rise as is end-to-end integration in advanced analytic platforms.
- What we said: Data Science continues to develop specialties that mean the mythical ‘full stack’ data scientist will disappear.
Yep. And there’s more talk about Data Engineers now than Data Scientists. Data Engineers are the folks who are supposed make those data science models work in the real world.
- What we said: Non-Data Scientists will perform a greater volume of fairly sophisticated analytics than data scientists.
It’s true. See the popularity of Data Viz and Visual Analytics as bridge technologies to let non-data scientists extract more value from sophisticated data science tools.
- What we said: Deep learning is complicated and hard. Not many data scientists are skilled in this area and that will hold back the application of AI until the deep learning platforms are significantly simplified and productized.
Both Microsoft and Google rolled out automated deep learning platforms in 2018. These started with transfer learning but are headed toward full AutoDL. There are also a number of startup integrated AutoDL platforms. We reviewed OneClick.AI earlier this year with both a full AutoML and AutoDL platform. Gartner recently nominated DimensionalMechanics as one of its “5 Cool Companies” with an AutoDL platform.
- What we said: Despite the hype, penetration of AI and deep learning into the broader market will be relatively narrow and slower than you think.
With the exception of chatbots which are becoming ever present, applications of real AI in business are narrow. They’re coming but there not there yet. The most comprehensive studies I’ve seen show that among large companies only 1/5th to 1/3rd are implementing AI ‘at scale’, meaning they are putting on a full court press. Among smaller companies the percentage is much much smaller. And we’re not really sure if they mean ‘true’ AI.
- What we said: The public (and the government) will start to take a hard look at social and privacy implications of AI, both intended and unintended.
Just take a look at the news and the stream of top social media executives being called on the carpet by our government and the EU. Begins to look like a perp walk. Government regulation is coming if not at the federal level, then in a more chaotic state-by-state balkanization like the California privacy rules about to go into effect or the Australian mandatory anti-encryption requirements.
So we’re calling that 6 for 6 wins on last year. While many of last year’s predictions could serve as well for next year we’ll try to be a little more specific.
Here’s What We See for 2019.
Prediction 1: Data Becomes More Important Than Algorithms
It’s been more than a year since we had any major new breakthroughs in either deep learning or classical machine learning. There’s been some incremental improvement like using Temporal Convolutional Nets (TCNs) instead of RNNs to reduce latency in NLP but no huge new innovations. The top performing algorithms are pretty well known or can easily be discovered using Automated Machine Learning.
We’re well into the period when having more and better data is the key to success as companies make their journey of digital transformation. As a practical matter this opens up opportunities for competition in providing data-related solutions that’s moving in several directions at once.
One axis is that getting accurately labeled training data for either image or text is still extremely expensive and time consuming. Companies like Figure Eight which specialize in labeling data are promoting smart cost effective strategies like Active Learning that let you determine the optimum tradeoff between labeled data and model accuracy. That involves multiple iterations of adding either human-labeled or machine-labeled data followed by retraining to find the best tradeoff.
Another axis is access to third party data. Service companies like DymstData have entered the field as clearing houses for many hundreds of types of append data. They’re also taking on the onerous role of making sure sensitive PII is protected and that their users can enforce role based accessed to certain sensitive information particularly important in financial and health services.
The third axis is automatically tracking and recording the provenance of data used in models. Particularly when streaming data from many sources is being integrated and changes over time, knowing where it originated and how it has been used is critical to both accuracy and to compliance. Tibco and some other analytic platforms are incorporating this feature.
Look for service offerings around data to expand significantly this year.
Prediction 2: Everything Gets Easier as AI/ML Moves Off Analytic Platforms Onto Industry or Process Specific Applications.
A quick look around the world of AI/ML startups shows that competition is moving to industry or process specific applications. These applications or mini-platforms are focused on solving industry specific problems in businesses as diverse as marketing, B2B sales, healthcare, fintech, and roughly a dozen other defined groupings. For a quick view take a look at CB Insights annual AI 100 winners in the nearby chart and the way they are grouped by industry or process.
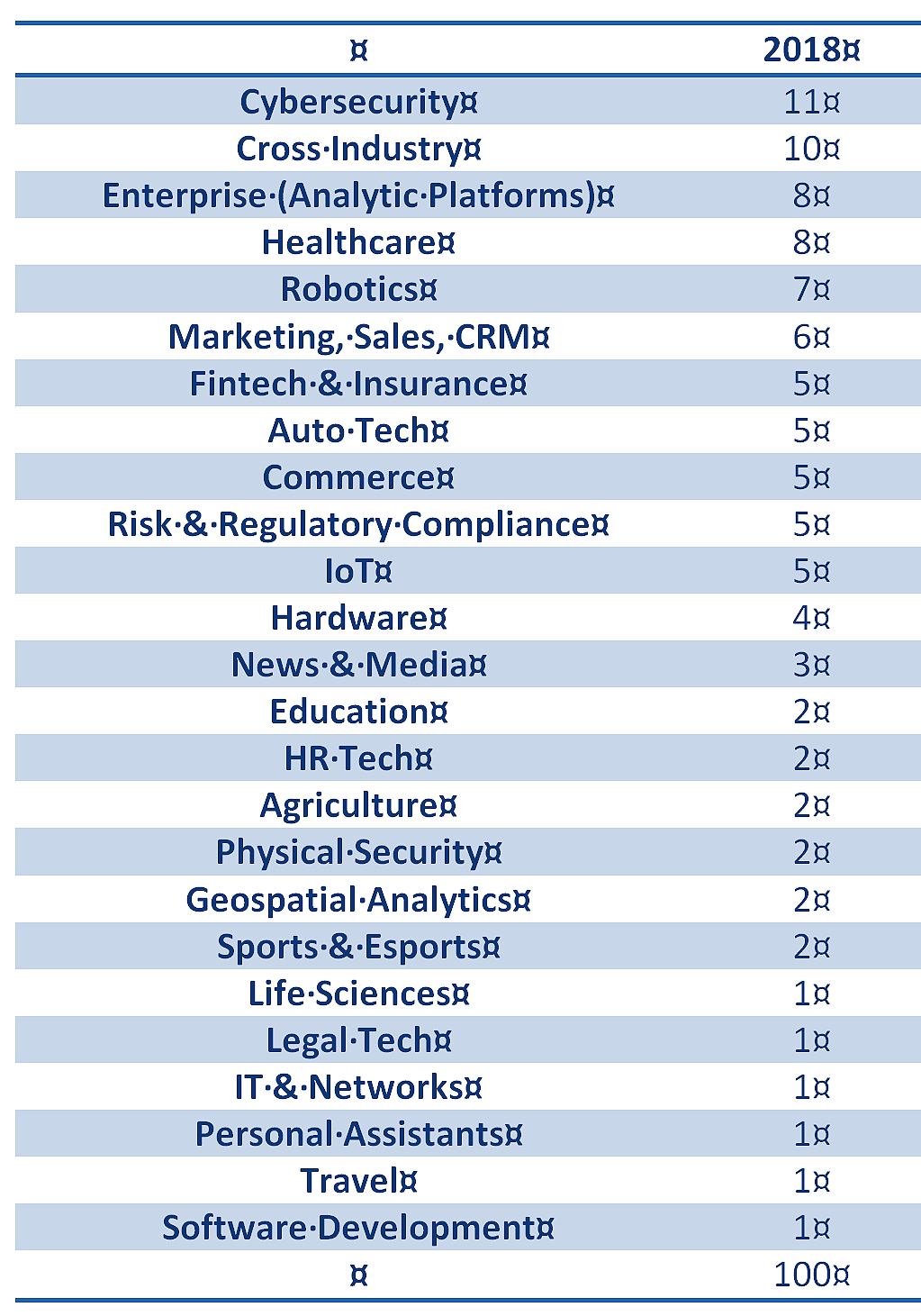 These new applications are focused on embedding the AI/ML so that the user’s organization does not need support from a large in-house group of data scientists and can rely on these developers to continue to provide updates and improvements.
These new applications are focused on embedding the AI/ML so that the user’s organization does not need support from a large in-house group of data scientists and can rely on these developers to continue to provide updates and improvements.
Some call this the commoditization of AI/ML but more accurately you might think of this as the specialization of AI/ML.
If you’ve been around long enough to remember the transition from Reengineering to ERPs in the late 90s this is very much the same thing. Initially Reengineering called on companies to improve processes with complex custom developed IT solutions because standardized solutions didn’t yet exist. That rapidly opened the door to the rise of the major integrated ERPs from Oracle, PeopleSoft, SAP and others, and also for specialized applications like CRMs. Our industry is undergoing this same change right now.
These new vendors all strive to provide broad solutions in their particular niches but inevitably end up with less than grand ERP-scale platforms. Watch for many waves of consolidation among developers in each of these industry groups.
Watch also for accelerating rates of AI/ML adoption in mid-size and smaller companies who no longer have to have large data science teams or to rely exclusively on custom developed models.
Prediction 3: Rise of the Data Engineer and Data Analyst
It’s not that the world has fallen out of love with data scientists. Far from it. But when you have a shortage of a skill then the market moves to ease that pain by filling it in different ways.
One way is through the industry and process specific smart applications we discussed above that don’t require great squads of in house data scientists.
The second is what’s going on in all the major analytic platforms and the dozens of Automated Machine Learning (AML) platforms that are rapidly emerging. That is to be more efficient in data science meaning that fewer data scientists can do the work of many.
Since the volume of models does not decrease, in fact increases, this moves the work load to data engineers who have two primary functions.
First, to be able to create the required infrastructure required for data science like data lakes and Spark instances.
The second is to be the one who takes the models and ensures they are implemented in operational systems and tracked for accuracy and refresh.
Some data engineers are also responsible for DataOps, ensuring a clean and preprocessed data stream.
The other evolution of analytic platforms is the growth of Visual Analytics and Data Visualization tools. These are now mostly fully integrated alongside the data science toolset and allow data analysts and LOB managers to extract more value and even guide efforts in analytics. They don’t replace data scientists. It reinforces the team aspect that advanced analytics is becoming.
Prediction 4: Neuromorphic Chips: AI Comes to the Edge for IoT
Two different technologies are reaching semi-maturity at the same time to solve a long standing problem. That problem is latency.
Consider for example that when you want to use your mobile device to automatically translate those text or image foreign words into English, or vice versa that your device actually sends that signal all the way back to the app in the cloud where the translation occurs, then all the way back to your device.
Google and others providing instant translation services have been moving from RNN to specialized CNN structures called Temporal Convolutional Nets because RNNs don’t adapt well to MPP but CNNs do. That switch reduced latency, but the signal still had to make the full round trip.
The first of two technologies to solve this problem is 5G networks. You may be aware that 5G is faster but its real benefit is the density of traffic it can carry. This really opens the door to letting pretty much everything in your life communicate on the internet. How many of those will prove worthwhile remains to be seen.
 The second solution is the introduction of new and better neuromorphic chips (aka spiking neural networks). We hope that these totally new architectures for neural nets may be the gateway to achieving Artificial General Intelligence (AGI). That’s still quite a way off.
The second solution is the introduction of new and better neuromorphic chips (aka spiking neural networks). We hope that these totally new architectures for neural nets may be the gateway to achieving Artificial General Intelligence (AGI). That’s still quite a way off.
However, both the major chip makers and several startups are now releasing spiking neuromorphic chips specially optimized to do CNN and RNN style models on the chip (without the round trip signal). Some of these are also optimized for very low power consumption.
Together these features are ideal for moving deep learning onto chips that can exist at the true edge of a network. Watch IoT and other streaming data apps explode with these new capabilities starting this year.
Prediction 5: Different AI Frameworks Learn to Speak to Each Other
Now that text, speech, image, and video models are going mainstream we’ve hit an unexpected barrier. Models built on one framework (Caffe2, PyTorch, Apache MXNet, Microsoft Cognitive Toolkit, and TensorFlow) can’t easily be ported to a different framework. We can translate speech, but we did it with a veritable Tower of Babel.
Fortunately pain points like this drive innovation. AWS, Facebook and Microsoft have collaborated to build Open Neural Network Exchange (ONNX), making models interoperable on different frameworks.
ONNX is shaping up to be a key technology this coming year as the number of models being shared among developers, apps, and devices becomes larger and larger.
Well that’s it for this year. Tune in next year and we’ll see how we did.
Other articles by Bill Vorhies.
About the author: Bill is Editorial Director for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}