
 Image Source: istockphoto
Image Source: istockphoto
Wouldn’t it be nice to have a sneak-peek into the future of your business to make informed decisions and eliminate guesswork? With the help of predictive modeling, this is possible. Predictive modeling enables businesses to reliably forecast trends and behaviors using past and current data. But to ensure the effectiveness of a predictive model, the data must meet exceptionally high standards. It is for this reason; the data scientists spend 80% of their time preparing and organizing data. Data cleansing ensures accurate prediction in predictive modeling by reducing noisy data. But how exactly is it done, and why is it so crucial for making an accurate prediction of future trends and forecasts possible? Let’s find out.
What is predictive modeling?
Predictive modeling is a form of data-mining technology that analyzes historical and current data to generate a model to predict future outcomes.
Let’s understand predictive modeling with the help of a simple example. If a customer purchases a laptop from an eCommerce website, he/she might be interested in its accessories immediately and a new battery a few years down the line. Currently, the chances of that person buying accessories from a competitor’s website are quite bleak.
Predictive modeling enables businesses to make predictions based on data and analytics techniques.
Where is the data obtained from for predictive modeling?
Predictive modeling draws all its power from data. The first step for predictive modeling is to use various sources for data collection. It could be customer data obtained from a website, such as the pages visited in the past, or the data the buyers themselves have provided by filling the sign-up form. Organizations collect data from various sources, but much of that data is ‘dirty’ and unstructured, which needs to be cleaned and processed with the help of data cleansing processes.
Why the data need to be clean for a predictive model?
To get a model that generates reliable future insights, modeling noise must be avoided in the data. Modeling noise causes model accuracy to decline. Besides that, unstructured and poorly formatted data can’t be easily sorted by computers.
For example, when reviewing entries under location, a human might understand that “America,” “U.S.,” and “U.S.A.” all mean the same thing, but a computer will consider them different unless told otherwise.
Besides making predictive modeling more accurate, clean data improves the overall productivity of businesses in the following ways:
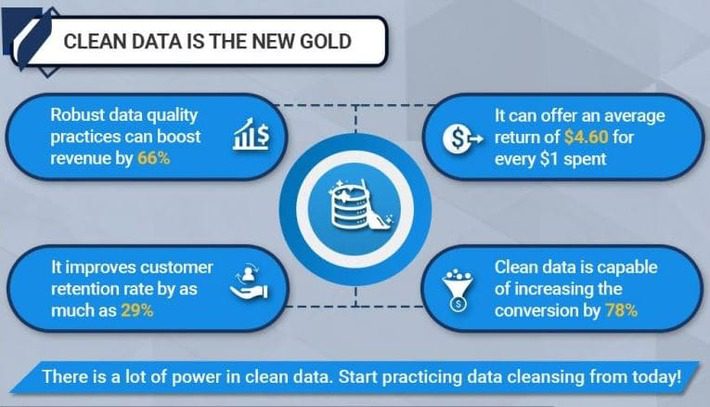
Image Source: Blue Mail Media
How is the clean data obtained?
Data cleaning involves the following three steps:
Step 1. Removing duplicate or irrelevant observations from the dataset.
Duplicate observations or the repeated datapoints arise during data collection, such as when combining datasets from multiple places, receiving data from clients and other departments.
Irrelevant data is the data that doesn’t fit into the specific problem we are trying to solve. For example, if we obtain data about the United States of America, data about other countries would be considered irrelevant.
Step 2. Fixing structural errors.
Structural errors are the errors that arise during measurement and data transfer. Fixing structural errors could involve several things, such as fixing typos or inconsistent capitalization.
Here are some examples of structural errors:
- “Country” is the same thing as “country.”
- “N/A” is the same thing as “Not Applicable.”
- “Shake-Shingles” is the same thing as “Shake Shingles.”
Step 3. Filter unwanted outliers
Outliers refer to the data that lies outside. For example, in the below dataset, 1 and 201 are outliers as “1” is extremely low value, and “201” is extremely high.
1, 99, 100, 103, 105, 109, 110, 201
Outliers can cause problems with certain types of models, but just because a value lies outside, it shouldn’t be discarded; there has to be a valid reason for discarding an outlier.
Step 4. Handling the missing data
Missing data cannot be ignored in a dataset. There are two commonly recommended ways of dealing with missing data:
- Dropping the observations with missing values.
- Imputing the missing values (assigning some value to the missing values) based on other observations.
However, the best way of handling missing data is by simply labeling them as “missing.”
By completing the above steps, you’ll have a robust dataset for a highly effective and reliable predictive model.
What does clean data look like?
After cleansing data properly, you’ll have a dataset with the following qualities:
- It is Valid. Clean data will conform to your defined business rules or constraints.
- It is accurate. Data that has been properly cleaned will be close to the true values.
- It is consistent. Properly cleaned data is consistent within the same dataset and across multiple data sets.
- It is uniform. A cleansed data will be specified using the same unit of measure.
- It is compliant: Clean and high-quality data is compliant with privacy regulations, such as – GDPR and CCPA.
Conclusion
Data cleansing or cleaning is an important step toward making efficient and effective business decisions using predictive analysis. Therefore, data cleaning must be met with a well-executed quality cleaning program. Ensuring this one step will help businesses save lots of money and efforts and several common pitfalls down the road.
{kind=link}