

Instant Grocery Delivery is the startup hype of the year in Europe. You select a few groceries via the shopping app, pay via Paypal, and 10 minutes later, a bike courier is at your door with your purchases. Its a business model that spreads magic among the users. A few months after launch, I know friends who do almost half of their shopping this way. Its a multi-billion dollar idea like Uber. A business model that is so easy to explain and still magical? But there are also apparent problems with highly disruptive business models like this:
- Overworked bike couriers going on strike.
- Issues with the districts because of noise pollution from warehouses located in the middle of residential areas.
- A low margin on products and little price tolerance from customers.
- Business growth is occurring geographically from district to district and city to city for companies like Gorillas.
- The colossal competition (I count 12 providers in Germany alone by now).
The US company GoPuff, founded in 2013, is considered a pioneer for the startups Gorillas, Flink, Zap, or Getir. GoPuff makes data-driven decisions to minimize the risks mentioned above. To boost these ambitions, GoPuff recently acquired the data science startup RideOS for $115 million. In markets with aggressive pricing, for many direct competitors and existing substitutes building a competitive advantage quickly via technology has proven to make the business model more efficient. A bold but also expensive move by GoPuff. In this article, I will show how to integrate within a day geospatial analytics for an instant grocery delivery use case without spending multi-millions on a startup acquisition.
But how exactly can we think of data-driven decision-making for instant grocery delivery? Assets that are important to optimize are:
- Where should I set up warehouses?
- What is the optimal size of the drivers fleet?
- What are the preferences of target customers in the region?
- How big is the market potential overall?
In this article, we ask ourselves the fictitious question, should an instant grocery delivery company go to the outlying Berlin district of Pankow? We do this using external data sources that can scale globally and use the data integration framework of Kuwala (its open-source). With Kuwala, we can easily extract scalable and granular behavioral data in entire cities and countries. Below you see activity patterns at grocery shops in Hamburg. We will make use of some of the functionalities to derive insights from the described areas.
We start our analysis by comparing the data on a neighborhood of Pankow with the neighboring part of PBerg (Prenzlauer Berg). The two selected areas are similar in size (square kilometers). Using the Kuwala framework, we first integrate high-resolution demographics data. On a top-level view, they are comparable to each other in total and within subgroups of gender and age.
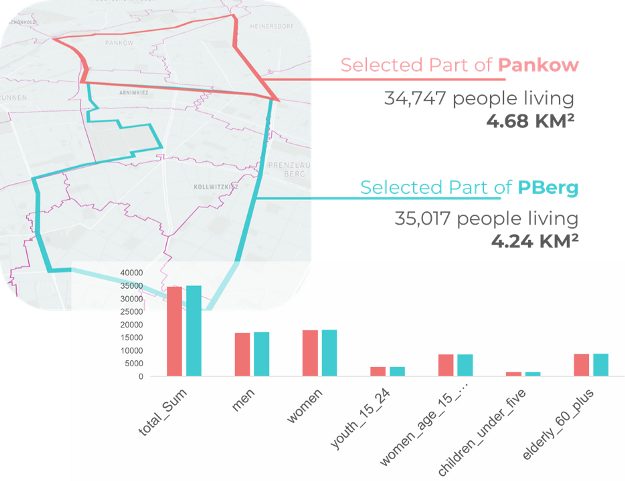
In the next step, we analyze the current status quo of Point-of-Interests regarding groceries (e.g., supermarkets). We build the data pipeline on OpenStreetMap data and extract categorization and name as well as price level. We combine that data with hourly popularity and visitation frequency at those POIs.
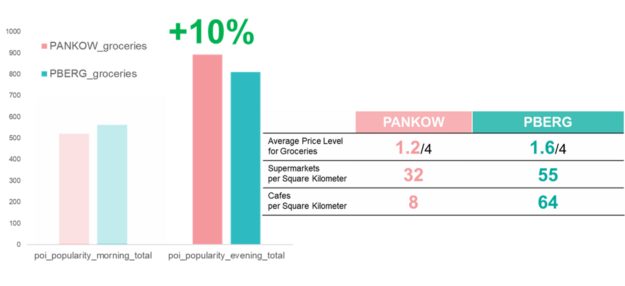
We find that Pankow has significantly fewer supermarkets per square kilometer. In addition, it shows that the price level of grocery stores is much higher in PBerg. Furthermore, we identify that groceries in Pankow are +10% more visited during the evening than PBerg. In summary, we can assume now that people in Pankow¦
- ¦ travel longer to supermarkets on average.
- ¦ often spend more time in the evening hours in supermarkets.
- ¦ have a lower price elasticity towards groceries.
Companies can now use that information in a market entry strategy. An aggressive cashback activation convinces people in Pankow to skip the evening shopping in a supermarket for a comfortable way of receiving the purchases right at their door.
We aggregated the high-resolution demographics data on an H3 resolution of 11 (based on raw data representing 30×30 meter areas). By that, we can analyze in-depth the distribution of people in a comparatively small district.
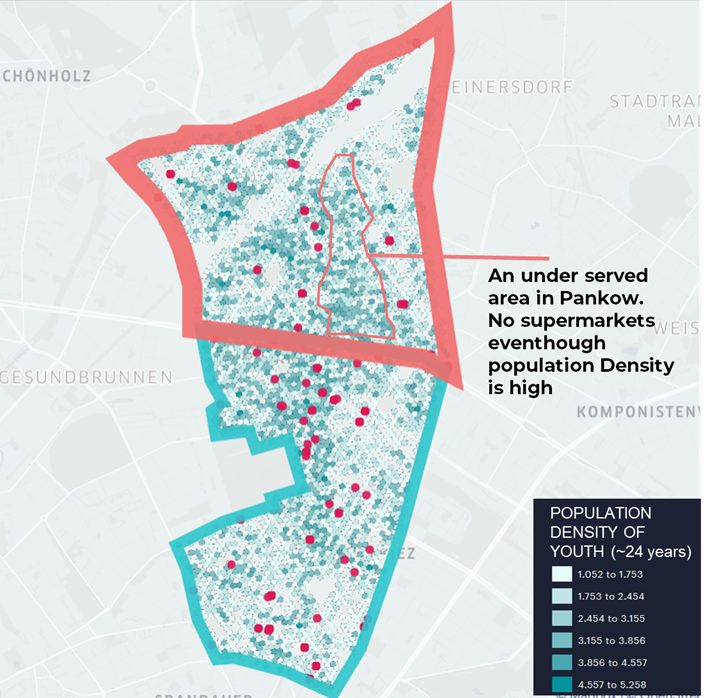
- We can spot areas with a high population of the young target demographic and less reachable options for doing groceries.
- In addition, we can spot micro-neighborhoods with a low population density, which makes those areas a perfect spot to open a warehouse, close enough to service areas and further away from people who could be disturbed by noise.
In the next part of this article, I will share some more advanced algorithms to identify over- and under-served areas and put everything at scale by comparing entire cities and the popularity of those places. If you want to discuss geospatial topics with us in the meanwhile, I recommend joining our slack community.
){kind=link}