

30-50% of businesses experience gaps between their data expectations and reality. They have the data they need, but due to the presence of intolerable defects, they cannot use it as needed. These defects also called data quality issues – must be fetched and fixed so that data can be used for successful business operations and intelligence.
Not every business faces the same set of data quality challenges. Some complain about encountering a gap in data lineage and content, while others have trouble with its completeness and consistency. Hence, not all data quality challenges can be resolved with the same set of methods and practices. This is where a data quality framework is used – one that is designed for a specific business case.
In this blog, we will discuss what a data quality framework is and how you can implement it. Let’s dive in.
What is a data quality framework?
A data quality framework is a systematic process that continuously profiles data for errors and implements various data quality operations to prevent errors from entering into the system.
Data quality framework – also called data quality lifecycle – is usually designed in a loop where data is consistently monitored to catch and resolve data quality issues. This process involves a number of data quality processes, often implemented in a prioritized sequence to minimize errors before transferring data to the destination source.
Stages of a data quality framework
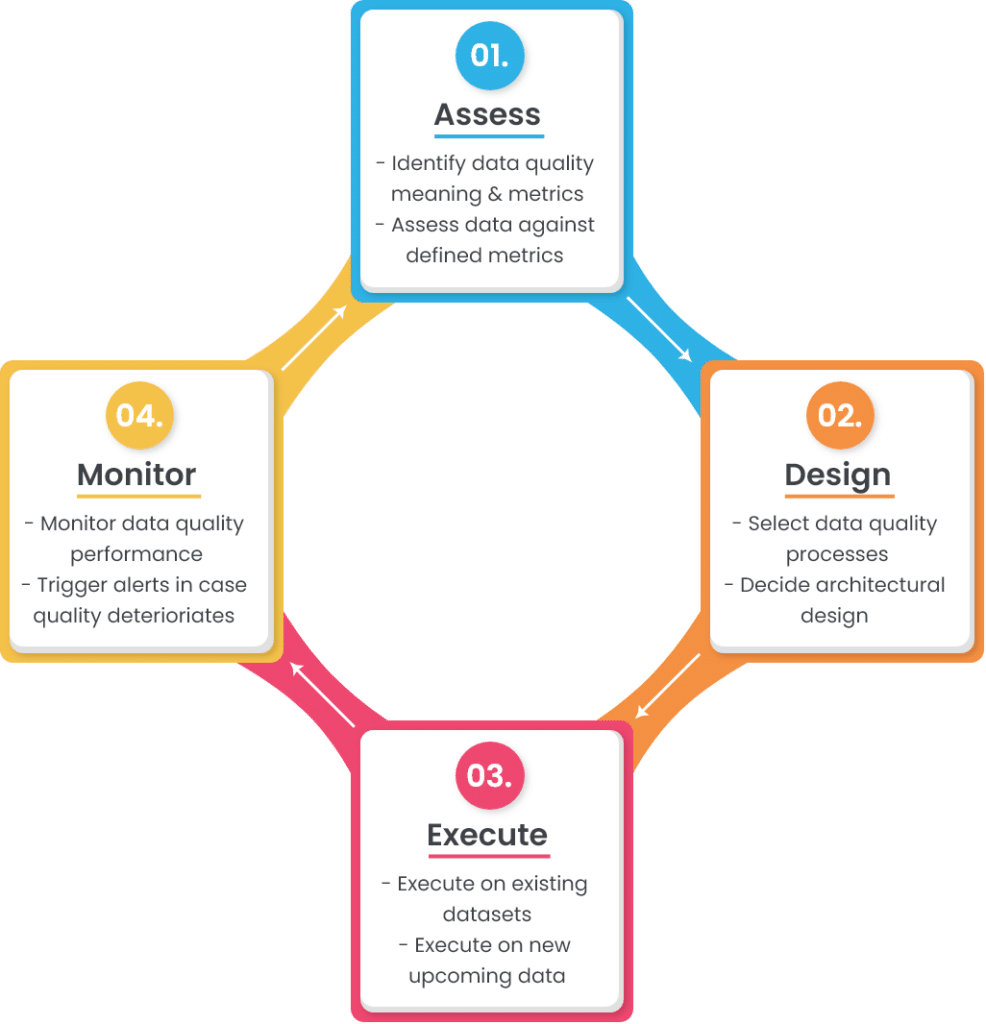
Designed in a cycle, a data quality framework contains four stages:
- Assessment: Assess what data quality means for the organization and how it can be measured.
- Design: Design a suitable data quality pipeline by selecting a set of data quality processes and system architecture.
- Execution: Execute the designed pipeline on existing and incoming data.
- Monitor: Monitor and profile data for data quality issues and measure data quality metrics to ensure they stay above defined thresholds.
How to implement a data quality framework?
Since data quality means something different for every organization, you cannot use the same data quality framework across different cases. Here, we will learn a framework that is comprehensive yet generic enough for various businesses to adopt for themselves. Let’s take a look at what the four stages of data quality framework include:
- Assessment
The first part of the framework involves defining the meaning of data quality (in terms of sources, metadata, and data quality metrics), and assessing how well the existing data performs against it.
Some activities performed at the assessment stage include:
- Selecting incoming data sources, such as CRMs, marketing tools, third-party vendors, etc.
- Selecting which attributes are necessary to complete the information, such as customer name, phone number, address, etc.
- Defining the data type, size, pattern, and format for the selected attributes, such as phone number should contain 11 digits and should follow the pattern: (XXX)-XXX-XXXX.
- Selecting data quality metrics that define acceptability criteria, such as customer preferences can be about 90% accurate and 80% complete, but customer name has to be 100% accurate and complete.
- Running data profile checks to assess how well existing data performs against the defined data quality.
- Design
In the design phase, you need to architect a data pipeline that will ensure all upcoming data is transformed into a state defined during the assessment stage.
Common activities at this stage include:
- Selecting data quality processes needed to clean, match, and protect the quality of data. Here are a few data quality processes usually included at this step:
- Data parsing and merging to divide or join columns however needed to make data more meaningful.
- Data cleansing and standardization to eliminate noise, such as null values and leading/trailing spaces, and transform values into an acceptable format.
- Data matching and deduplication to identify records belonging to the same entity and eliminating duplicate records.
- Data merge and survivorship to overwrite outdated values and merge records to attain a single view.
- Data governance rules to capture update history and implement roles-based access.
- Deciding when to perform the selected data quality processes; at input, in the middle, or before data is committed to the database.
- Execution
You have defined the data quality levels and configured the data quality processes, now it’s time to execute the framework. It’s important to first run the processes on existing data and then enable it for incoming data streams.
- Monitor
The final stage of the framework involves monitoring and profiling the data treated to the data quality pipeline. This will help you to:
- Check that the configured processes are working as expected.
- Ensure data quality issues are eliminated or minimized before data is transferred to the destination source.
- Raise alerts if critical errors creep into the system.
Iterating the data quality lifecycle
Another important aspect of data quality framework is deciding when to trigger the cycle again. For example, some may want to implement a proactive approach where data analysis reports are generated at the end of every week and the results are analyzed to see if any critical errors were encountered. Alternatively, some implement a reactive approach where the reports are only analyzed when data quality deteriorates below acceptable levels.
Once the cycle is triggered again, the subsequent phases are executed to see if:
- The data quality definition needs to be updated,
- New data quality metrics need to be introduced,
- Data quality pipeline needs to be redesigned,
- Data quality processes need to be executed on data again, and so on.
Wrap up
Data quality management is a pressing concern for many businesses. It’s an awkward stage where you and your team believe they have the data needed, but still are unable to produce data-dependent results. Implementing a data quality framework that cleans and transforms data is just as important as collecting data. In the long run, these corrective measures can help improve your organization’s operational efficiency and work productivity.
Originally appeared at Dataversity.net
{kind=link}