

Image by Ahmad Ardity from Pixabay
The good news is that the data science community is taking more of an interest in knowledge graphs lately. But unsurprisingly, some data science folks exploring graphs themselves are barely scratching the surface of knowledge graph potential.
Until data scientists view the root problem to be solved through the lens of architectural transformation and grasp the scope of the problem to be solved, they won’t be designing and building knowledge graphs in a way with system-wide benefits. Labeling data scraped off the public web won’t solve fundamental architectural problems.
Data scientists will need to support the creation of shared understanding–knowledge articulated in a findable, accessible, interoperable and reusable (FAIR) fashion in a knowledge graph–by allying with knowledge architects and engineers who understand how to build and connect interoperable knowledge domains at scale. Otherwise, knowledge graph efforts will fail the same way most master data management efforts have failed.
Leadership can play a critical role here in supporting the nurturing and growth of a knowledge building and sharing human resource that has clout when it comes to broadening and deepening company AI efforts. Leadership in this case starts with granting real authority and long-term commitment to knowledge architects and engineers, professionals who are by definition well versed in ontologies, the key to logically consistent, scalable and reusable knowledge graphs.
Unless these professionals have authority and budget to proceed with building out a consistent and scalable graph infrastructure and leadership mandates the use of this infrastructure, knowledge graph efforts won’t succeed in enterprises, and data quality will continue to suffer. Tribalism will undermine those efforts. Machine learning folks, for example, who advocate monolithic, statistical-only AI over hybrid AI and who are seeking more power than they already have will continue to trample on the few ontologists who have the skills and experience to back serious knowledge graph initiatives.
Knowledge graphs in demand for question-answering accuracy
In November 2023, benchmarking reports from data.world and Meta confirmed the need for semantic technologies such as knowledge graphs in order to improve question-answering accuracy.
Data.world reported in its results report that zero-shot GPT-4 prompting of SQL databases had 16 percent accuracy. The same GPT-4 prompting of a KG representation of those SQL DBs, meanwhile, resulted in 54 percent accuracy. (Sequeda, Allemang, Jacob, “A Benchmark to Understand the Role of Knowledge Graphs on Large Language Model’s Accuracy for Question Answering on Enterprise SQL Databases,” Nov. 14, 2023.)
Meta, for its part, reported that humans could answer questions with 92 percent accuracy, versus 15 percent for GPT-4 with plugins. (Mialon, Fourrier, Swift, Wolf, LeCun, and Scialom, “GAIA: A Benchmark for General AI Assistants,” November 23, 2023.)
Data science, data theory…and the issue of poor data quality
On November 16, 2023 statistics professor Mark Handcock moderated the third seminar in the UCLA series on Data Theory in the World, on the subject of Knowledge Graphs in Data Science. It was a helpful seminar but didn’t address what knowledge graphs are capable of beyond single, presumably understaffed, ad-hoc projects. Two PhDs who hold data science roles at Snap and Microsoft told stories about their public/private entity matching and COVID research knowledge graph-building efforts.
The University of California at Los Angeles (UCLA) is unusual in that it offers a major in Data Theory. Data doesn’t often get this level of foundational attention. It clearly deserves to be a research field in its own right, given that machine learning’s accuracy is entirely dependent on the quality and comprehensiveness of data inputs. (See “Data management implications of the AI act” at https://www.datasciencecentral.com/data-management-implications-of-the-ai-act/ for more detail.)
Handcock introduced the session by defining data theory as the mathematical and statistical foundation of data science. He pointed out that UCLA’s Data Theory degree program is a joint effort between the mathematics department and the statistics and data science department.
Handcock defined data science as the science of how to learn from data. His definition focuses on the machine learning side of things and assumes that the data is already worthy of a machine learning effort. The truth is that consistent and pervasive data quality is mostly lacking or absent when it comes to many machine learning efforts.
Just to name one example of how low data quality can be for machine learning purposes, recent research from Amazon and UC Santa Barbara indicates that much of the web-scraped content that ends up in ML training sets is machine-translated into different languages, which implies the incremental degradation of the input data with each translation.
Moreover, the authors discovered selection bias in translated content: “We also find evidence of a selection bias in the type of content which is translated into many languages…. A limited investigation suggests this selection bias is the result of low-quality content generated in English (likely produced to generate ad revenue) and translated en masse into many lower resource languages via machine translation (again, likely to generate ad revenue).” (Thompson, Dhaliwal, Frisch, Domhan and Federico, “A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism,” January 11, 2024.)
The power of verbs and relationship richness in graphs
Knowledge graphs when built well and used properly counter the trend toward lower data quality and improve question-answering accuracy across domains. One of the fundamental characteristics of knowledge graphs is that they are designed to be relationship-rich. The reason for the relationship richness is that the right relationships (the verbs or predicates in RDF triples) contextualize the data properly so that it can be integrated logically and efficiently, domain by domain. Mere labeling efforts overlook the necessity of the consistent use of these predicates.
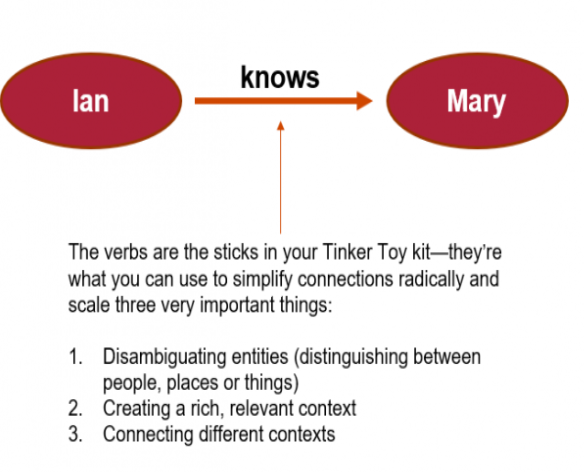
Relationship logic is key to building context. Ian knows Mary because they ride the bus to work together. Google suggests that they work at the same place when Maps sees the routes they take.
In this simple example, the probabilistic logic of machine learning needs the deterministic logic of relationships and connections–determined facts. The two are symbiotic. Otherwise, generative AI tends to hallucinate, and we can’t get to general intelligence or high confidence levels. Thus a need for “neurosymbolic AI”–neural nets and symbolic logic working together–in which case, the logic is conveyed via webs of relationships via RDF triples in knowledge graphs.
Knowledge graphs can have a huge impact on hundreds of different use cases, but only if they are logically consistent (in accordance with FAIR principles) and operational at the enterprise scale. Data theory degree programs seem to be missing the point of knowledge graphs if they’re not advancing this larger vision.
{kind=link}