
This is my third article related to LLM and GPT-like apps. See the first one, “Why and How I Created my Own LLM from Scratch”, here. The second one listed 7 main ingredients for faster and better results. Among them:
- customized embeddings: one per top category,
- creating a high-quality taxonomy,
- parameter self-tuning based on user favorites, and
- offering two prompts to the user: one for the query, one to select a top category.
For details, see here.
In this article, I discuss some secret sauce to further reduce the size of the token database by several orders of magnitude. This makes scalability a lot easier and much less costly. Finally, a key to success is fast search, for instance ANN vector search. Here, ANN stands for approximate nearest neighbors. I explain how to adapt fast search to my slightly unusual architecture.
Variable Length Embeddings (VLE)
For years, I did not know that I was doing things differently. Only recently did I realize, after looking at some architectures, that most use fixed-length embeddings. In particular, embeddings may have hundreds of tokens. Of course, fixed length has benefits, such as amenable to fast vector search for information retrieval. And big companies have access to large bandwidth, so it is not a problem. Indeed, they can brag about billions of parameters or tokens, when millions are more than enough. For the client, it is costlier.
Using separate embedding tables for each top category means much shorter, specialized embeddings with more relevant tokens. But the big gain is with variable-length embeddings. It does not make sense to keep all the tokens when only 20 are really related to a specific keyword withing a specific category. In the end, my embeddings may content anywhere between 5 tokens (for highly specialized keywords), to 100+ for general words.
Interestingly, I found a paper on the topic, entitled “Variable Length Embeddings”, published in 2023 by computer scientists at Berkeley. It is available here. To conclude this section, there is more to my secret sauce: the probabilities or values attached to each token in each embedding are not probabilities. Rather, they are based on token and keyword cross-correlations, using pointwise mutual information (PMI). It makes comparison easier across multiple top categories, since each one has its own embedding table.
Adapting Fast Search to VLE
There are several algorithms to perform quick, fuzzy search (with no exact match): see the article “Comprehensive Guide to Approximate Nearest Neighbors Algorithms”, here. The goal is to find the nearest neighbors to the user-generated prompt (its segments or n-grams) in your embedding database. It is not really a problem in my current architecture for two reasons. First, each top category has its own table, much smaller than a big generic table. Then, I do not really compare embeddings in the classical sense, at least for now. Thus, retrieval is lightning fast.
However, besides exploring solutions available in the literature if not as Python libraries, I started doing my own research. One possibility is to use my radix search, a version of interpolated binary search. It is based on encodings, long integers, and the radix numeration system. I describe it here, in the context of GenAI model evaluation. It may require some preprocessing, such as features ordered by importance. Another solution is a probabilistic search that I use in my NoGAN technology, similar to an fast approximation of the Hungarian algorithm, see here.
Another Example
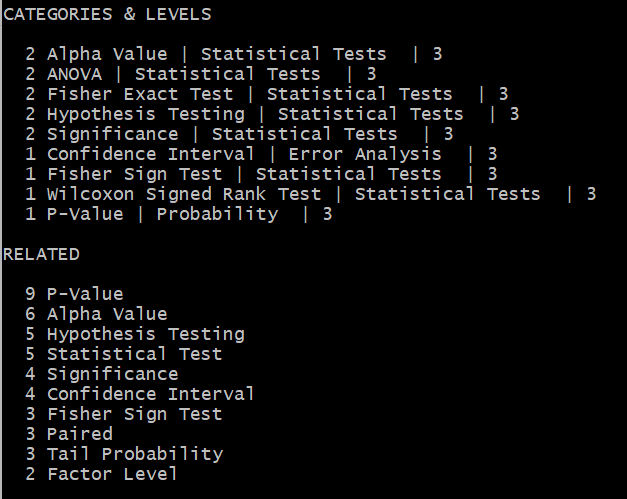
I shared an example in my previous article, here, to illustrate the superiority of my method, over OpenAI GPT, Bard, and other alternatives. Here, I compare the results for the keyword “p-value”: my algorithm versus the Wolfram search box. It is surprising that my results, based on crawling Wolfram, are much superior to Wolfram internal search! Likewise, Google and GPT return basic results of no value when you are an expert looking for serious references.

Author

Vincent Granville is a pioneering GenAI scientist and machine learning expert, co-founder of Data Science Central (acquired by a publicly traded company in 2020), Chief AI Scientist at MLTechniques.com and GenAItechLab.com, former VC-funded executive, author and patent owner — one related to LLM. Vincent’s past corporate experience includes Visa, Wells Fargo, eBay, NBC, Microsoft, and CNET. Follow Vincent on LinkedIn.
{kind=link}