
Many social media, like Twitter, Facebook and etc, are evolving to become a source of information for people to scrape varied kinds of data, since microblogs on which users post real time messages shows millions of opinions about their attitudes or sentiment towards hot topics and current issues. Recently, I decided to learn how Regional sentiment analysis can help people to make specific decisions or policy strategies for different regions. Notably, Tweets scraped from Twitter can provide tremendous real-time data for our analysis. In my approach, I develop a Twitter Sentiment Classifier, which will classify a scraped tweet into three main polarities : Positive, Negative and Neutral. To make our analysis more straightforward and clear, I will only extract certain data fields related with one tweet. A sentiment word dictionary will be referenced by Term Weighting. The classifier uses Linear SVM technique. The multi-class classification strategy uses one-vs.-rest (OVR). To evaluate the performance, a data set with 8692 labeled scraped tweets is used in this experiment for training dataset, and 2336 scraped data for testing data set.
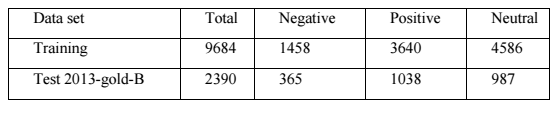
Learning one’s attitudes with respect to certain products or policy can help people to make significant decisions sometimes. What’s more, people’s attitudes can vary due to the regional disparities. Moreover, many Twitter users has marked their geo locations in their tweets. And these features can make tweets become a optimal source for analysis.
Web data Scraping from Twitter
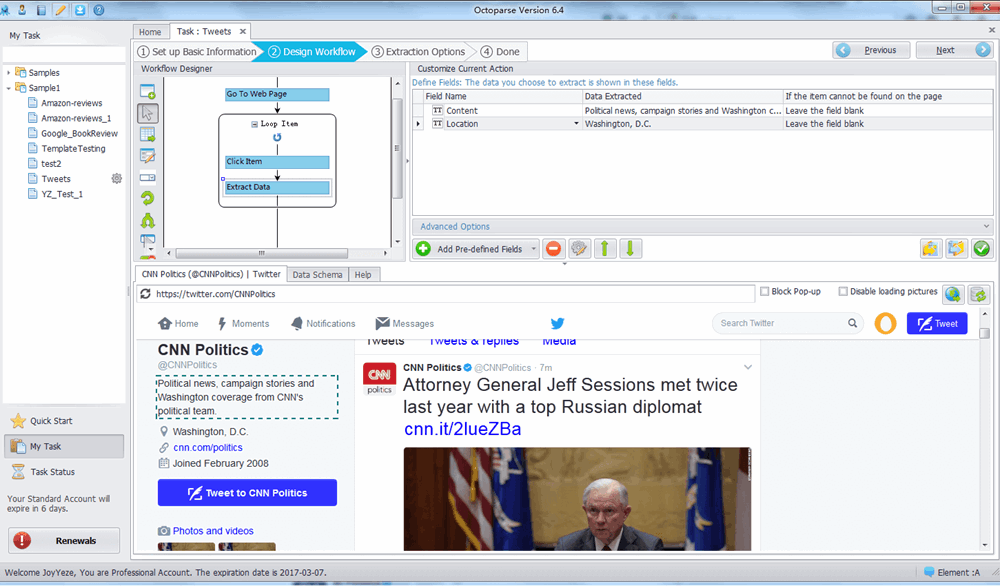
As well known, data itself serves a significant role to start with machine learning. Thus, what we first need to do is to scrape tweets data from Twitter with good quality. In this writing, I would like to mention three possible methods for you to scrape data from Twitter. First, as Twitter offers public APIs to their data set, developers are allowed to read and write twitter data conveniently. The REST API identifies Twitter applications and users using OAuth; Then We can utilize twitter REST APIs to get most recent and popular tweets. Alternatively, we can program to build our scraper or crawler on our own by using Python or Ruby, while it would be tough for people without coding skills. Notably, I’d like to share with you about the scraping service – Octoparse that I once used based on my user experience. It will set us free from complex laborious work or skilled coding.
Octoparse is meant for providing professional web scraping service. Take Twitter for example as below. Users can customize their own scraping tasks by clicking and dragging the blocks in the Workflow Designer pane and customize the crawling pattern. Users can scrape and export data from the target websites. It also provides IP Proxy, Data Re-format, XPath Re-location and many other advanced options.
After we scraped tweets data from Twitter, then classifying tweets into different sentiments is the core task of my approach. As mentioned before, there are total three polarities: Positive, Negative and Neutral. Thus, we should note that the Binary-Class Classifier no more fits our classification any more. Current microblogs classification methods can be classified into two main types: Lexicon-based (Dictionary-based), and machine-learning-based. Specifically, what we use is to use the machine-learning approach which involves building classifiers from labeled instances of texts or sentences. The machine-learning program will be developed using Python and scikit-learn toolkit.
Support Vector Machines (SVMs) are popular supervised learning models which performs well in high-dimension feature spaces. Hence, it is suitable for text analysis. Basically, a SVM is to construct a hyperplane or a set of hyperplanes in high dimensional space, which can be used for classification intuitively. A good separation is achieved by the hyperplane that has the largest distance to the nearest training data point of any class (so-called functional margin), since in general the larger the margin the lower the generation error of the classifier.
There are two kinds of separation model: Linear and Non-Linear. Typically, a non-linear kernel SVM has better predictive performance. However, once the number of features is large, it’s better to consider the linear kernel first, since it will be much faster than a non-linear kernel. In my approach, I will try linear kernel SVM.
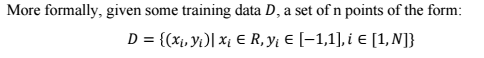
Where the is either 1 or -1, which indicates that the set to which the point xi is belongs. Each xi is a p-dimensional real vector. The objective is to find the maximum margin hyperplane that divides the points having =-1. Any hyperplane can be written as the set of points x satisfying:
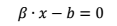
Where the parameter determines the offset of the hyperplane from the origin along the normal vector .
Noteworthy that the term is weighted differently for the three classifiers. The term weight formula:
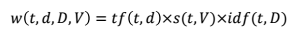
Where s(t, V) is the term t’s sentiment score in dictionary V. For each term in V, it has three polarity scores. For example, the term unlikeable has three scores: 0, 0.85, 0.125, where o is the positive score, 0.85 is the negative score, and 0.125 is the neutral score. For classifier1, the s(t, V) is the positive score; for classifier2, s(t, V) is the negative score; and for classifier 3, s(t, V) is the neutral score.
Regional Sentiment Analysis
Based on a set of tweets with geo location tag in regions. The calculation will not be precise if we only include the total number of the positive or negative tweets, since some sentiments are strong and some are weak. After prediction, a tweet’s prediction p will get a confidence score c(p). Then the regional sentiment RS is derived as below:
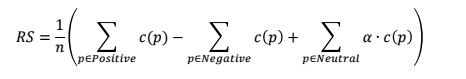
Here , n is the total number of tweets scraped or crawled in this region, and the parameter a is a custom weight to compute the contribution of neutral tweets. The higher the RS, the more positive the region is.
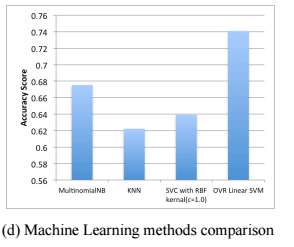
The figure below shows a accuracy comparison among Naive Bayes, kNearestNeighbor(KNN), SVC with RBF kernel and Linear SVM. By observation, the result shows that Linear SVM is more suitable for my approach.
Author: The Octoparse Team
– See more at: Octoparse Blog
{kind=link}