

Working with the audio production and engineering industry, I often wonder how the future of the voice talent market will look like with the assistance of artificial intelligence. The development of cloning technology started a while back but it did not reach today’s level overnight. The debate of misusing this technology is another conversation that is not the agenda of this article. However, I would like to say that there are more opportunities out there than fears. And just like any other technology, we need to know how it works to explore the avenues and detect embezzlement.
Statistical Parametric Speech Synthesis (SPSS), WaveNet, and Tacotron played a huge role in the development of Text To Speech models. In 2019, Google researchers published a paper called “Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)” which was assumed to be the state of the art algorithm for voice cloning. It describes a framework for zero-shot voice cloning that only requires 5 seconds of reference speech. The three stages of SV2TTS are a speaker encoder, a synthesizer, and a vocoder. However, the implementation of this paper was not out there until the work of Corentin Jemine, a student from the University of Liège. Corentin wrote his Master’s Degree thesis on SV2TTS called “Real-time Voice Cloning” with some improvisation and also implemented a user interface. His work later led to his side project called “Resemble” which runs as a voice cloning solution for various platforms.
Mathematical Intuition and algorithm
In a dataset of utterances of a speaker, Corentin denotes uij as jth utterance of the ith speaker. And by xij , he denotes the log-mel spectrogram of the utterance uij . A log-mel spectrogram is a function that extracts speech features from a waveform. The encoder E computes the embedding eij = E(xij ; wE ) corresponding to the utterance uij , where wE are the parameters of the encoder. A speaker embedding is the centroid of the embeddings of the speaker’s utterances. This is the mathematical model of the embedding :
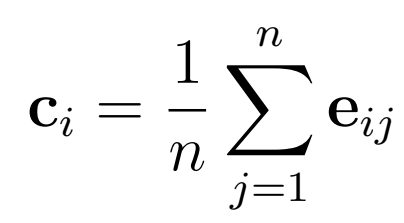
Now, the synthesizer S will try to model xij given ci and tij , the transcript of utterance uij.
We have x^ij = S(ci, tij ; wS).
In Corentin’s implementation, he uses the utterance embedding rather than the speaker embedding, giving instead x^ij = S(uij , tij ; wS).
The Vocoder V will approximate uij given x^ij . We have uˆij = V(x^ij ; wV). wV is the parameter in this case. This objective model will be minimizing the loss, where LV will be denoting the loss function in the waveform domain :
minwE,wS ,wV LV(uij , V(S(E(xij ; wE ), tij ; wS); wV))
However, Corentin proposes another loss function that can take less time to train :
minwSLS(xij , S(eij , tij ; wS))
He suggests training the synthesizer and vocoder separately. Assuming a pre-trained encoder, the synthesizer can be trained to directly predict the mel spectrograms of the target audio. Then the Vocoder is trained directly on spectrograms that can take both the ground truth or the synth generated spectrograms.
minwV LV (uij , V(xij ; wV))
Or
minwV LV (uij , V(xˆij ; wV))
Now the Speaker Encoder. This encoder produces embeddings that can characterize the voice in the utterance. Having no ground truth as a reference, it needs to have the corresponding upsampling model for prediction.
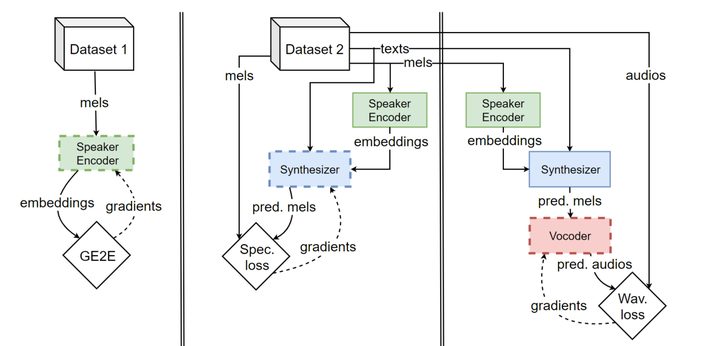
The sequential three-stage training of SV2TTS. Source: Corentin’s thesis paper
With the GE2E loss function, the speaker encoder and synthesizer are trained separately. The synthesizer needs to have the embeddings from a trained encoder and when not trained on the ground truth, spectrograms from a trained synthesizer needs to be fed into the vocoder.
Let’s take a look at the architecture and modification by Corentin on that three-stage pipeline.
Speaker Encoder: Corentin used 256 units LSTM layers to build this encoder to make the training load lighter. However, In the original paper by Google, they trained the model in 50 million steps. There were 40 channel spectrograms as inputs. Corentin improvised with a ReLu layer before the L2 normalization in the last layer which is a vector of 256 elements. After speaker embedding with short utterances, The GE2E loss function optimizes the model. The models compute the embeddings in this way :
eij (1 ≤ i ≤ N, 1 ≤ j ≤ M ) of M utterances of fixed duration from N speakers.
A two-by-two comparison through a similarity matrix of all embeddings eij against every speaker embedding
ck (1 ≤ k ≤ N) in the batch looks like this :
Sij,k = w · cos(eij , ck) + b = w · eij · ||ck ||2 + b
High similarity values are expected in an optimal model. To optimize, the loss will be calculated by row-wise Softmax losses. When embedding, the utterances are included in the centroid of the same speaker. To avoid the bias that is created towards the speaker independently of the model accuracy, an utterance that is compared against its own speaker’s embedding will be removed from the speaker embedding. The similarity matrix will look like this :
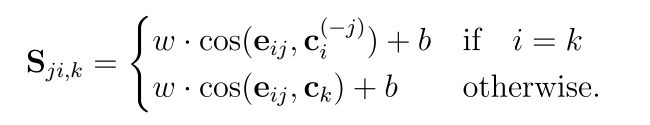
ci(−j) is the exclusive centroid here. 1.6 seconds of sample utterances are taken from long datasets. The model segments the utterances of 1.6 seconds and the encoder passes the utterances individually. The mean output is then normalized to generate utterance embedding. Corentin proposes to keep 1.6 seconds both for inference and training. He also stresses vectorization in all operations when computing the similarity matrix for efficient and fast computation.
For experimenting with the speaker encoder, Corentin preprocessed the samples and removed the silent parts of the utterance samples with the help of a python package. He used the dilation technique (s+1) where S is the maximum silent duration tolerated. Note that the value of S was 0.2s in his experiment. Finally, he normalized the audio waveform. He used all the same datasets used by the Google authors – LibriSpeech, VoxCeleb1, and VoxCeleb2; except another one – an internal set which Corentn did not have the access to use. These datasets included thousands of hours and speakers and celebrities collected from clean and noisy recordings as well as from youtube.
After training the speaker encoder 1 million steps where he sees that the loss decreases slowly, Corentin observed how well the model can cluster the speakers. He uses UMAP to project the embeddings and the model separated gender and speakers linearly in the projected space.
Synthesizer : The synthesizer is Tacotron2 without Wavenet. It’s a recurrent sequence to sequence model that predicts spectrograms from the text. SV2TTS however, did a modification in the process – a speaker embedding is concatenated to every frame that is output by the Tacotron encoder but in the Tacotron methodology, frames are passed through a bidirectional LSTM. Concatenated vector goes through two unidirectional LSTM layers and then projected to a single mel spectrogram frame.
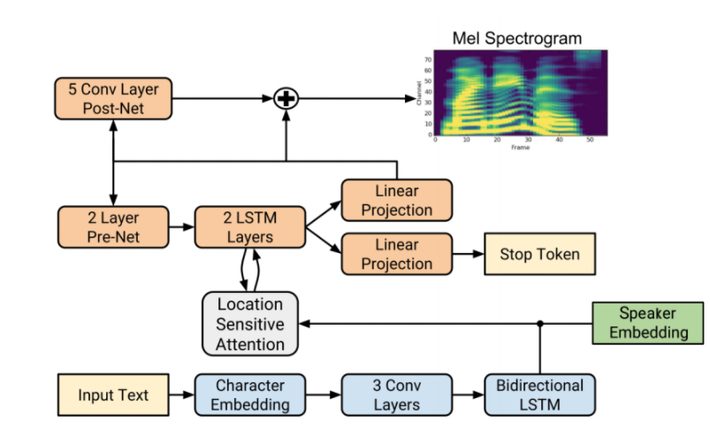
The Modified Tacotron. Source: Corentin’s Thesis Paper
Corentin improvised by replacing abbreviations and numbers by their complete-textual form, making all characters ASCII, normalizing whitespaces, and making all characters lowercase. When implemented, Corentin used the LibriSpeech dataset that he thought would give the best voice cloning similarity on unseen speakers. Mentionable results, however, did not come using the LibriTTS dataset. Also, he used the Montreal Forced Aligner for Automatic Speech Recognition and to reduce background noises from synthesized spectrograms, the LogMMSE algorithm.
In the case of embeddings to train the synthesizer, Corentin preferred to use utterance embeddings of the same target utterance in his experiment instead of what is proposed in the SV2TTS paper.
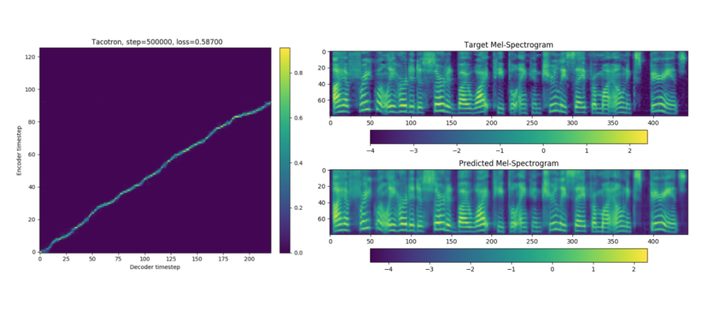 Encoder and Decoder steps aligned (Left). Resulting in a more smooth version of the predicted spectrogram than the ground truth Mel.
Encoder and Decoder steps aligned (Left). Resulting in a more smooth version of the predicted spectrogram than the ground truth Mel.
Source: Corentin’s thesis paper
The results were excellent aside from the pauses in some cases. This happened due to the slow-talking speakers embedding. Also, Corentin’s limits on the duration of utterances in the dataset (1.6s – 11.25s) were likely to cause those issues.
Vocoder: Corentin uses a pytorch implementation of WaveRNN as the vocoder which was improvised by github user fatchord. Although the authors of Sv2TTS improvised on the computation time and overhead of the computation by implementing the sampling operation as a custom GPU operation. Corentin didn’t do that. He used a batched sampling with alternative WaveRNN.
Corentin finds that for the utterances shorter than 12.5 seconds, this alternative WaveRNN will run slowly. The time it takes to infer is highly dependent on the number of folds in batched sampling. In the sparse WaveRNN model, Corentin finds that the matrix multiply operation for a sparse matrix and a dense vector-only reach at an equal state timewise, with the dense – only matrix multiplication for levels of sparsity above 91%. The sparse tensors will slow down the forward pass speed below this threshold. This implementation finds that a sparsity level of 96.4% would lower the real-time threshold to 7.86 seconds, and a level of 97.8% to 4.44 seconds.
Conclusion
Without a doubt, Corentin Jemine did a great job implementing the SV2TTS paper with some of his own thoughts. As his thesis was published more than a year ago, more recent developments must be there already. But I found his thesis paper as a breakthrough in this technology and I am sure it has helped to shape the latest innovation of voice cloning. I will encourage everyone to read his paper in this link : https://matheo.uliege.be/handle/2268.2/6801
Corentin also made a user interface for this project which he demonstrates in this youtube link: https://www.youtube.com/watch?v=-O_hYhToKoA
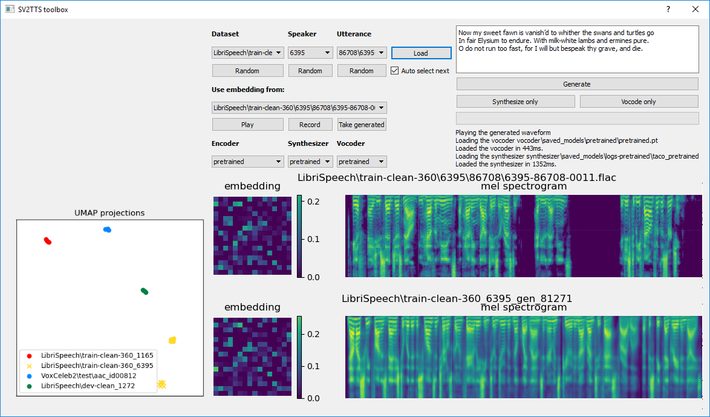
SV2TTS Toolbox: The user interface by Corentin Jemine
Corentin also mentioned in his youtube comment that “Resemble”, another project by him, which came after this thesis, can produce better results than what he could achieve in his experiment and invites everyone to use that instead. However, I particularly loved his ideas on some improvisation that he did on the original SV2TTS paper which opened the door for innovation. For example, his speaker encoder model worked well with Equal Error Rate to be 4.5% which is 5.64% lower than the Google researchers’ who trained their model 50 times more than Corentin’s !
Needless to say that this technology will go beyond our imagination in near future. New marketplaces will grow, media, entertainment, and information industries will be acting as key stakeholders of this technology. Voiceover talents will find new ways to get themselves heard in so many different ways. Also, this is only a matter of time that the reverse engineering of the voice cloning models will show up very soon. By wiping out the ‘deep fakes’, hopefully, those models will flatten all the tensions and make way for voice cloning technology towards the greater good.
{kind=link}