
Summary: As advanced analytics and data science have matured into must-have skills, data science groups within large companies have themselves become much larger. This has led to some unique problems and solutions that you’ll want to consider as your own DS group grows larger.
It seems like only two or three years ago you wouldn’t have had to ask this question. Unless you were Google, Amazon, or an equally big player your data science teams were small, maybe in the range of 3 to 12, and were still trying to find their place in your organization.
Fast forward to today and it’s not unusual to find teams of 20 or 40 or even more and that’s a game changer. It’s no longer like Cheers where everyone knows your name. In larger organizations more order, organization, and process becomes necessary.
The large analytic platform providers clearly understand this. I’m thinking IBM, Microsoft, SAS, Alteryx and similar. Over the last year or so there’s been an increasing focus on elephant hunting, slang I’m sure you’ll recognize for trying to get a foothold where the big teams live.
Here are some topics and questions that seem to arise as common ground from trying to manage larger DS orgs.
You’re Going to Want to Standardize on a Process Which Probably Means Standardizing on a Platform
If you’ve got 40 people in a data science team that implies a large number of projects and as a result a large number of models or product features to keep track of and maintain. You can’t have everyone freelancing in tools and project structure or you’ll never keep up.
As you’ve approached this scale you probably tried to adhere to a common process such as CRISP-DM and may even have written some internal standards about how that’s implemented. Another common situation is for a DS group to have coalesced around a comprehensive platform.
Take Alteryx for example that enables the process from data blending through modeling. You’re all using the platform so it’s easy to communicate where you are in a modeling project and there can be project-by-project discussion of when and if, for example, you’re going to use custom code as opposed to the built-in tools.
That will get you part of the way there and some will be happy with this semi-formal level of formalization. However, the lessons we take from the project management process and application development disciplines like Agile are that more organization can be better and doesn’t necessarily bog things down.
Recently both IBM and Microsoft have created offerings to template this level of organization for you in hopes of getting you to focus on their DS and cloud offerings. IBM has the Data Science Experience and Watson Studio. Microsoft introduced the Team Data Science Process.
Some Examples from the Microsoft Team Data Science Process (TDSP)
Of the ‘systems’ we were able to identify, the Microsoft TDSP seems to be the most comprehensive, literally defining project steps and individual roles and responsibilities. TDSP includes:
- A data science lifecycle definition (high level project plan description).
- A standardized project structured (including even sample templates for things like project charters and reports).
- A list and description of the required infrastructure and resources.
- Tools and utilities for project execution (the Microsoft offerings this platform is intended to promote).
The high level process diagram is not all that different from CRISP-DM but easy to use when describing the steps. 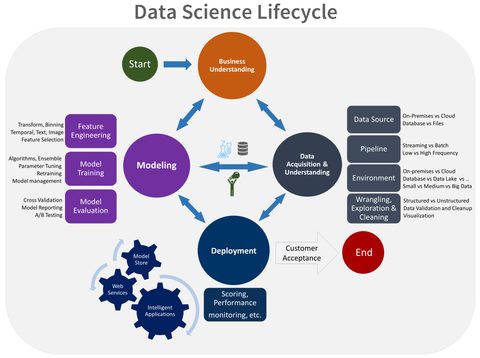
Going down one more level, the TDSP even lays out specific roles and responsibilities for each common DS role including Solution Architect, Project Manager, Project Lead, and Data Scientists. 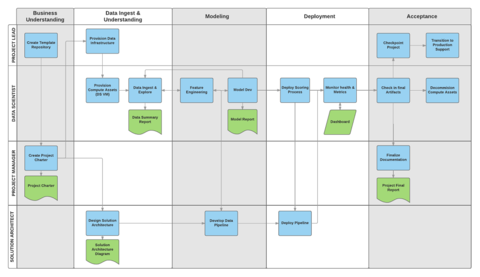
The entire package is quite comprehensive and detailed. If you haven’t addressed this level of detail for your organization this would be a good starting point.
Maintaining Data Pipelines
Another common pain point in larger DS organizations is acquiring and maintaining data pipelines. Probably as your organization grew this was originally assigned to junior data scientists. As you grew you realized this wasn’t a good use of resources.
Over the last two or three years the separate discipline of Data Engineer has emerged as a formal and separate supporting role for the data science process. There are a great many specialized skills in maintaining data pipelines ranging from MDM to more technical skills like creating data lakes or creating instances of Spark.
It’s an open conversation in each organization whether this task falls under the data science group or IT. It will depend on how many of these folks you need and whether they are dedicated to these data science tasks, and of course some internal politics.
However, as data science increasingly becomes a team sport played by specialists this function is your major connection to IT and needs to be clearly defined and agreed.
Managing the Incoming Project Pipeline
Looking from the data science team upward to your internal customers, many data scientists find that more than a third of their time is spent meeting with LOB managers to define and vet new projects and then to report progress.
This is also a process that will benefit from some formalization starting with an agreement at the executive level of how the benefit of various projects is to be calculated.
Some organizations are requiring an initial estimate of dollar benefit before undertaking new projects. This no doubt leads to some pretty optimistic projections from LOB managers but it’s important in establishing a project charter to quantify the goals.
Like any good project, this step leading up to the project charter should also include the measures and threshold values that will be used for determining customer acceptance. Yes these may be subject to some revision once you get underway, but it’s important to put a stake in the ground so you can manage the priority of incoming projects.
Educating Internal Customers
When we think of the training needs of a DS group we often think just of what skills our data scientists need to do their work. However, there is also a requirement to educate your customers in what they can and can’t expect, and what the process of engaging with you will look like.
Some organizations take a minimalist approach to this providing say scheduled quarterly one-hour briefings and perhaps some written material for managers wanting to be educated.
Some take a more comprehensive approach of using each project win as a briefing opportunity to tell their story not only to their specific internal customer but in shortened form to other potential LOB customers. This serves as basic education for those that haven’t yet engaged with you, and continuing education about your expanding capabilities as your group becomes more successful.
Internal education of your data science team is just as important and much more under your direct control. Aside from the obvious opportunities for juniors to learn from seniors by participating directly in projects, some of the comprehensive platforms like the IBM Watson Studio have very specifically designed-in instructional materials and resources across a wide variety of DS topics.
Keeping the Creative Momentum
As organizations grow, there is a temptation to view the DS group as just another service provider. LOB managers define problems to be solved and the DS group delivers. Begins to sound a lot like order taking.
The truth will continue to be that as your data scientists keep abreast of what’s evolving in our profession, your group is best positioned to suggest creative solutions to problems that may not yet have even been identified.
There’s a temptation to divide every organization into just two levels of strategic development. Either you are in that exciting and less well defined period of figuring out how data and analytics will create competitive advantage, or you have passed over into the refinement phase where improvements are more incremental.
As the lead or influencer in a large DS organization it’s important to maintain that creative input to the organization. No organization is permanently in the initial stage or permanently in the incremental improvement phase. It would be good practice to carve out a specific amount of time and effort to gather the best knowledge and ideas from your DS team, and have a method of floating these up to the LOB and executive levels.
No one in the company will ever know more about data science and what it can do than your group. Don’t become order takers.
Other articles by Bill Vorhies.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}