
Summary: To ensure quality in your data science group, make sure you’re enforcing a standard methodology. This includes not only traditional data analytic projects but also our most advanced recommenders, text, image, and language processing, deep learning, and AI projects.
A Little History
 In the early 1990s as data mining was evolving from toddler to adolescent we spent a lot of time getting the data ready for the fairly limited tools and limited computing power of the day. Seldom were there more than one or two ‘data scientists’ in the same room and we were much more likely to be called ‘predictive modelers’ since that type of modeling was state-of-the-art in its day.
In the early 1990s as data mining was evolving from toddler to adolescent we spent a lot of time getting the data ready for the fairly limited tools and limited computing power of the day. Seldom were there more than one or two ‘data scientists’ in the same room and we were much more likely to be called ‘predictive modelers’ since that type of modeling was state-of-the-art in its day.
As the 90’s progressed there was a natural flow that drew us toward standardizing the lessons we’d learned into a common methodology. Efforts like this always start out by wondering aloud whether there even was a common approach given that the problems looked so dissimilar. As it turns out there was.
Two of leading tools providers of the day, SPSS and Teradata, along with three early adopter user corporations, Daimler, NCR, and OHRA convened a special interest group (SIG) in 1996 (also probably one of the earliest collaborative efforts over the newly available worldwide web) and over the course of less than a year managed to codify what is still today the CRISP-DM, Cross Industry Standard Process for Data Mining. I’m honored to say that I was one of the original contributors to that SIG.
CRISP-DM was not actually the first. SAS Institute that’s been around longer than anyone can remember had its own version called SEMMA (Sample, Explore, Modify, Model, Assess) but within just a year or two many more practitioners were basing their approach on CRISP-DM.
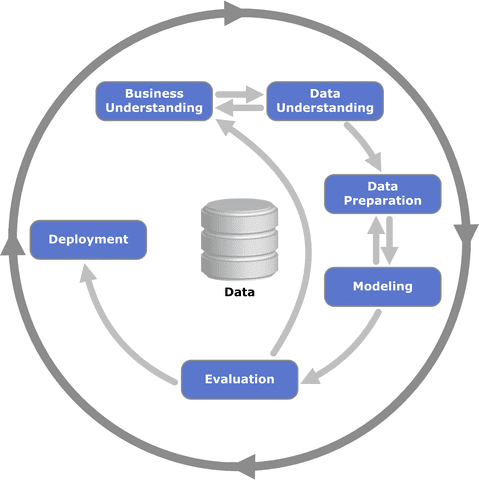
What is CRISP-DM?
The process or methodology of CRISP-DM is described in these six major steps
1. Business Understanding
Focuses on understanding the project objectives and requirements from a business perspective, and then converting this knowledge into a data mining problem definition and a preliminary plan.
2. Data Understanding
Starts with an initial data collection and proceeds with activities in order to get familiar with the data, to identify data quality problems, to discover first insights into the data, or to detect interesting subsets to form hypotheses for hidden information.
3. Data Preparation
The data preparation phase covers all activities to construct the final dataset from the initial raw data.
4. Modeling
Modeling techniques are selected and applied. Since some techniques like neural nets have specific requirements regarding the form of the data, there can be a loop back here to data prep.
5. Evaluation
Once one or more models have been built that appear to have high quality based on whichever loss functions have been selected, these need to be tested to ensure they generalize against unseen data and that all key business issues have been sufficiently considered. The end result is the selection of the champion model(s).
6. Deployment
Generally this will mean deploying a code representation of the model into an operating system to score or categorize new unseen data as it arises and to create a mechanism for the use of that new information in the solution of the original business problem. Importantly, the code representation must also include all the data prep steps leading up to modeling so that the model will treat new raw data in the same manner as during model development.
You may well observe that there is nothing special here and that’s largely true. From today’s data science perspective this seems like common sense. This is exactly the point. The common process is so logical that it has become embedded into all our education, training, and practice.
So What’s the Issue?
In our recent article about getting the most out of your data science team, we argued that if you are responsible for a data science group, one of your main tools for quality and efficiency is to ensure that a common methodology is being used.
There is a risk in any data science project of sub-optimizing the result or even getting directionally the completely wrong answer. Think about quality before one bad project casts doubt on the work of your whole group.
Many of today’s advanced analytic platforms will actually walk users through a series of CRISP-DM steps (even if they don’t call them that). However, if some or all of your group are freelancing in R or Python code, you will be hard pressed to tell who is taking shortcuts and with what implications for quality.
Isn’t More Detail Needed?
Absolutely it is. The brief description of the methodology above is only a summary. Googling ‘CRISP-DM’ will reveal a host of academic and industry guides that add a great deal of granularity to each phase that you can modify to meet your actual environment. For example, much more emphasis is necessary today on:
- Data blending from diverse sources and ensuring this is a fully repeatable process in the deployed code.
- Selecting the appropriate level of accuracy for the business problem to ensure that your data scientists are delivering what’s needed and not spending excessive time on prep or modeling to increase accuracy that can’t be used in a timely way.
- Ensuring that a full spread of analytic algorithms is being tested and not relying on the ‘gut hunch’ or ‘we’ve-always-done-it-this-way’ predilection of the modeler. Today’s analytic platforms can frequently run a full spectrum of algorithm types against the same data simultaneously and automatically display the champion algorithms. Is your team running those full spectrum tests?
- As platforms become more simplified and allow citizen data scientists to produce what appear to be sophisticated models, important decision elements like how to treat missing data, or how to create new synthetic features may be lost. Quality may be compromised.
- Are simple protocols like an absolute requirement for holdout unseen data being uniformly enforced?
- Are additional steps necessary to optimize the results by combing models with optimization math in what is commonly referred to as prescriptive analytics?
There was an effort to create a CRISP-DM 2.0 in the mid-2000s but the sites are no longer active. In short, there wasn’t all that much to be improved upon. However, you should feel free to add detail that’s appropriate for your environment.
Can CRISP-DM be Used for Non-Traditional Modeling Projects Like Deep Learning or Sentiment Analysis?
Data science has moved beyond predictive modeling into recommenders, text, image, and language processing, deep learning, AI, and other project types that may appear to be more non-linear. If fact, all of these projects start with business understanding. All these projects start with data that must be gathered, explored, and prepped in some way. All these projects apply a set of data science algorithms to the problem. And all these projects need to be evaluated for their ability to generalize in the real world. So yes, CRISP-DM provides strong guidance for even the most advanced of today’s data science activities.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}