
Introduction
The deployment of Machine Learning and Deep Learning algorithms on Edge devices is a complex undertaking. In this post, I list the strategies for deploying AI to Edge devices end-to-end i.e. for the full pipeline covering machine learning (building modules) and deployment (devops)
I welcome your comments on additional ideas that could be included. In subsequent posts, I will elaborate these ideas in detail and ultimately, this will a free book on Data Science Central. I will take a use-case based approach i.e. each section would start with a use case.
Firstly,
Many IoT applications are simple telemetry applications i.e. data is captured using a single sensor and action is undertaken based on the data. In doing so, the data may be stored or visualised. Telemetry applications are relatively easy to build. But for large-scale, professional applications, there are many complex elements involved. Specifically, in these posts, we consider the cloud as a driver of such applications. Hence, the cloud and edge work together to create deployment models for AI on edge devices at scale.
In this post, we outline ways in which the cloud and the edge can work together to deploy AI on edge devices. The post is based on my teaching at the University of Oxford – Cloud and Edge implementations course
Before we proceed, let us clarify some terminology that we will use in this post:
- IoT (Internet of Things) – refers to smart sensors which have some sensing or actuating
- Edge computing has a wider meaning. The word edge can be best understood in context of cloud where we have computational and storage capabilities closer to the origin of data creation. Edge computing provides a low latency response and capability for offline processing if needed. Specifically, for AI and ML capabilities, Edge means the ability to train the model in the cloud and deploy on an edge device.
Flow of Data for AI on Edge devices
The overall flow of data for AI on edge devices is as follows
- Data leaves the Edge
- Data comes to rest in Cloud
- Not all data may be sent from the edge to the cloud i.e. in many cases, data may be aggregated at edge devices and only a summary maybe sent to the cloud
- Typically, machine learning and deep learning models are trained in the cloud
- The model is deployed to the edge
- Inference could be at the edge (device or embedded), cloud or in the stream
- Typically, models are deployed in containers through a webservice, on specific hardware, using serverless technologies, using CI/CD, using Kubernetes
- Finally, the whole system could be modelled as a Digital Twin
Deployment strategies to implement AI on the Cloud and the Edge
Below are the possible deployment strategies for AI on Edge devices
- Edge processing – computer vision
- Edge processing – web service APIs
- Edge processing – Non-computer vision (ex: sensor-based data)
- Big Data Streaming strategies – Spark/ MLFlow, Kubeflow, Tensorflow extended etc
- Containers (docker and kubernetes)
- Serverless (Edge) – complements containers?
- CI/CD for Edge devices
- AI in hardware – inference, AI Chips, FPGAs, Vision Processing Units – Intel Movidius
- Streaming: Apache Kafka, Splunk
- Digital Twin
Please let me know if I have missed any
Conclusion
As I mentioned above, I will elaborate each of these strategies in subsequent posts. In each case, we will focus on the implementation of AI / ML for that strategy. Rather, I will discuss how ML / AI can be implemented with it
Finally, some may think – this is all an overkill. Indeed, many applications do not need such a comprehensive approach. However, as larger/enterprise IoT applications get deployed, especially using the cloud, we will see these ideas being deployed.
I list below a section from 2019 highlights from a niche analyst firm I follow
Their ‘Most important IoT technology evolution’ for 2019 is Containers/Kubernetes
I very much agree with the below. I have used the same in my teaching. While containers are not on the radar of many IoT developers, in my view, they should be for scalable applications.
IT architectures are fundamentally changing. Modern (cloud-based) applications build on containers, thereby bringing a whole new set of flexibility and performance to deployments. This is also becoming true for any centralized or edge IoT deployment.
It is fair to say that by now, Google’s open-source platform Kubernetes has largely won the race of container orchestration platforms, and Docker is the most popular container runtime environment (desipite the companies financial issues)
2019 saw several heavyweights in the IT and OT industry refine their container strategy:
VMware. In August 2019, at VMworld 2019, leading virtualization software provider VMWare laid out a holistic Kubernetes strategy. The company believes that “Kubernetes will prove to be the cloud normalisation layer of the future”. It launched VMware Tanzu, a cloud platform that manages Kubernetes container distribution and allows to build and deploy applications.
Cisco. The networking giant which had launched its “Cisco Container Platform” in early 2018 and announced joint projects with Google Cloud and AWS, in July 2019 completed its big 3 cloud partnership portfolio by announcing that Microsoft’s Azure Kubernetes Services are now natively integrated into the Cisco platform
Siemens. Industrial giant Siemens in October 2019 bought Pixeom, a software-defined edge platform, with the goal to embrace container technology for edge applications in factories. The Pixeom technology is built on the Docker runtime environment.
Further notable news saw HPE launch its own Kubernetes container platform in November 2019, and high-flying startup Mesosphere changed its name to D2iQ in August 2019 and shifting its strategy partially away from its own “Mesos” standard to focus further on Kubernetes deployments.
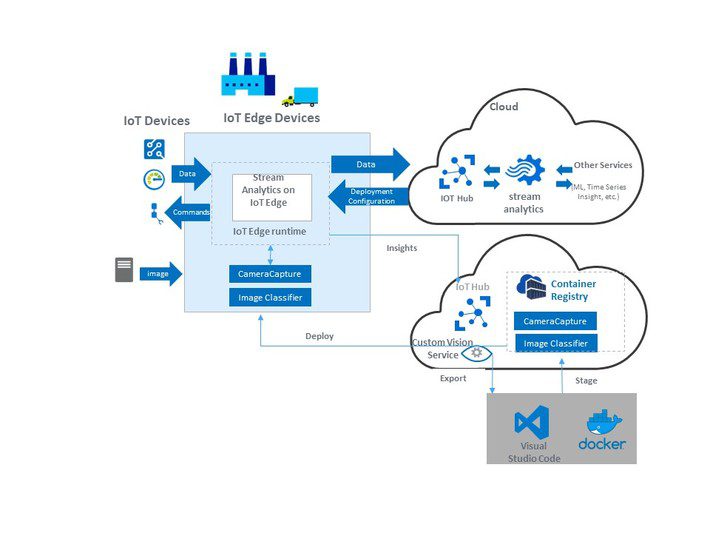
About the image
I created the image based on Azure but the concepts apply to other cloud platforms also
To keep it uncluttered, the image does not include all the strategies listed above
About me: Pls see Ajit Jaokar – Linkedin
{kind=link}