
Summary: Data Scientists from Booking.com share many lessons learned in the process of constantly improving their sophisticated ML models. Not the least of which is that improving your models doesn’t always lead to improving business outcomes.
 The adoption of AI/ML in business is at an inflection point. Recent adopters are still building teams and trying to plan portfolios of projects than make sense and can create value. On the other side of the curve are mature adopters, many of whom are large well known ecommerce companies and now have years of experience in implementation, team management, and most important the extraction of value.
The adoption of AI/ML in business is at an inflection point. Recent adopters are still building teams and trying to plan portfolios of projects than make sense and can create value. On the other side of the curve are mature adopters, many of whom are large well known ecommerce companies and now have years of experience in implementation, team management, and most important the extraction of value.
There are obviously not as many mature adopters and even fewer who have been willing to share the broader lessons they’ve learned. Eventually, perhaps a decade from now this knowledge and experience will flow around more evenly, but for now it’s rare.
All the more important to recognize the contribution made in August by Lucas Bernardi, Themis Mavridis, and Pablo Estevez of Booking.com who shared their paper “150 Successful Machine Learning Models: 6 Lessons Learned” at KDD ’19 this last August. The goal of the paper is to speak to the issue of how ML can create value in an industrial environment where measurable commercial gain is the goal.
There are many things that make Booking.com’s environment unique as the world’s largest on line travel agent. Their technical focus is on recommenders and information retrieval where almost all users are cold-start, given that we don’t travel that often or to the same places. This not music, books, movies, or even fashion where some patterns can be built up.
Booking.com has multiple interdisciplinary teams of data scientists, business managers, UX designers, and systems engineers who constantly work together to tease out meaningful patterns from the frequently incomplete input provided by potential travelers.
There are models that focus on specific triggers in an event stream but also models that are semantic in nature and can provide clues for many different internal uses. For example, what is the likely flexibility of the user for travel dates, destinations, or accommodation type? Is the user actually shopping for a family vacation (users frequently omit the number of children) or a business trip.
All of these less known factors need to be teased out of navigation, scrolling, and search models along with the little information provided by the user. One lesson shared is that optimal user presentation including fonts, use of images, text, offers, and all the other elements of UX are not represented by a single optimal standard but vary for a fairly large number of subgroups of users, and then across multiple languages and cultures.
And the stakes are high. Connect a user with a bad experience and they won’t come back. The supply of accommodations may technically be constrained but its variety and detail can overwhelm a user. And of course pricing changes by the hour based on availability and elasticity.
Improved Model Performance Does Not Necessarily Mean Improved Business Impact
The one lesson out of all this great shared learning that struck me however was the disconnect between model performance and business impact. Let’s start at the end by looking briefly at their conclusions.
Of the roughly 150 business critical models they looked at 23 classifiers and rankers that in the normal course of business had come through their ML management process as candidates for improvement. The technical measures for improvement were either ROC AUC for classifiers or Mean Reciprocal Rank for rankers.
By business category they ranged over preference models, interface optimization, copy curation and augmentation, time and destination flexibility, and booking likelihood models.
Before and after performance is judged by Randomized Control Trials which can be multi-armed and are designed to only consider the response of users who are targeted by the change.
Their internal process is hypothesis based and experimentally driven. The majority of the 46 pair comparisons showed improvement but not all. However, when compared to KPIs that matter to business performance like conversion rate, customer service tickets, or cancellations the results were much different.
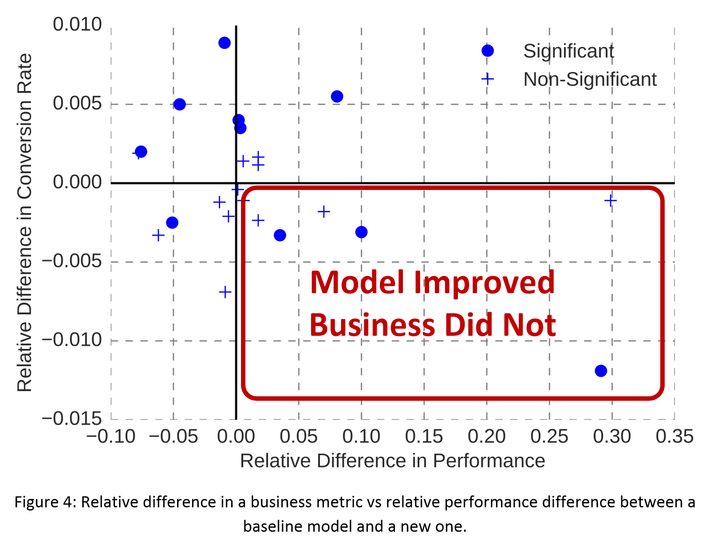
Visually we can see that there’s little correlation between model improvement and business improvement (vertical axis – conversion rate), confirmed by a Pearson correlation of -0.1 at the 90% confidence interval.
So What Happened?
The authors offer up the following cautionary lessons:
It’s as Good as It’s Going to Get: If you’ve been working at improving your system for quite a while it’s quite possible you’re approaching ‘value performance saturation’. You can’t improve a system incrementally forever and future gains may simply be too small to matter.
Test Segments are Saturated: Booking’s test protocol is to run A-B or multi-arm tests against one another further enhanced by only testing those users that are impacted by the change. As models improve performance the disagreement rate for target users goes down limiting the number of users that can be tested. The ability to detect any gains from the improvement therefore also shrinks.
Too Much Accuracy Can Seem Creepy to Customers: Otherwise known as the uncanny valley effect, if your models get too good this effect can be ‘unsettling’ to customers and actually work against their user experience and your business gain. 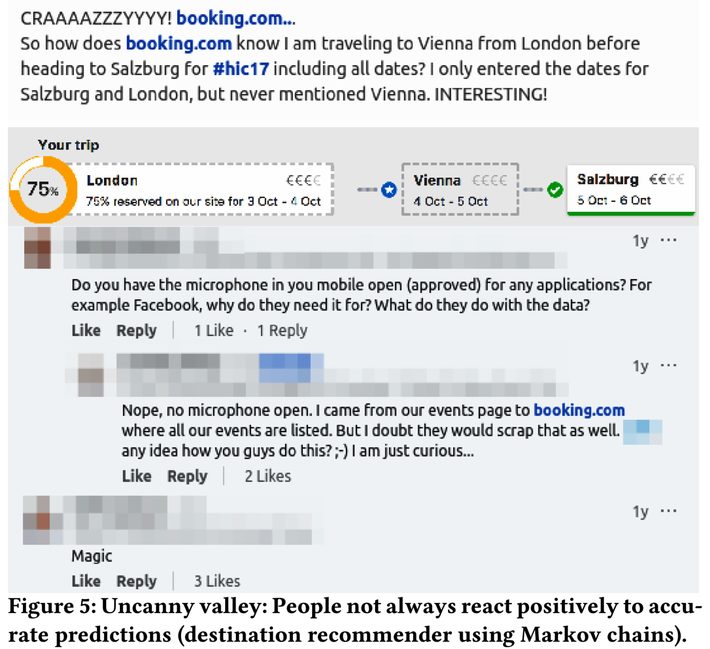
You Have to Pick Something to Model: Since these are basically supervised ML models we have to have a measurable outcome closely related to the behavior being modeled. That might for example be Click Through Rate (CTR) which is supposed to have a strong correlation with the business KPI of Conversion Rate. But as models get better, driving CTR may just be driving clicks and not conversions.
Here’s as excerpt from the authors showing an example of this over optimization:
“An example of this is a model that learned to recommend very similar hotels to the one a user is looking at, encouraging the user to click (presumably to compare all the very similar hotels), eventually drowning them into the paradox of choice and hurting conversion. In general, over-optimizing proxies leads to distracting the user away from their goal.”
There are many good lessons in this paper although the authors warn that these may not completely generalize beyond their own environment. Still, their explanation of their “Problem Construction Process” as well as their measurement protocols are well worth considering for adoption, along with the several other more technical findings they present. And of course the warning to make sure model improvement is actually driving the desired business outcomes.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2 million times.
He can be reached at:
{kind=link}