
Updated on August 12. See new section entitled “Future research on the topic.”
Here I propose an alternative to traditional cryptography. Traditional cryptography relies on hash functions (Bitcoin) or large prime numbers (RSA.) The foundations of this new technology are based on my book on numeration systems, available for free to DSC members. The key idea is to use numeration systems with non-integer bases, to represent numbers.
1. Representation of numbers in a non-integer base
The following also applies to integer bases such as base 2 (binary), base 10 (decimal) or base 16 (hexadecimal). However our interest is in bases that are real numbers between 1.5 and 1.9. In these bases, the digits — just like in the binary base-2 system — are always 0 or 1. Unlike the binary system though, the proportions of 0’s and 1’s are not equal to 50%, and there is some auto-correlation in the sequence of digits. I explain in the next section how to handle this problem. Another issue is that in these small bases, a digit carries less than one bit of information, thus making the message to be transmitted, longer than the binary code (base-2) that represents it. More precisely, the amount of information stored in one digit is equal lo log(b) / log(2) bit, where b is the base. This is why we want to avoid bases that are smaller than 1.5.
Algorithm to compute the digits
To compute the digits of a number x between 0 and 1, in base b, one proceeds as follows:
- Start with x(1) = x and a(1) = INT(bx).
- Iteratively compute x(n) = b * x(n-1) – INT(b * x(n-1)), and a(n) = INT(b * x(n)).
Here INT represents the integer function, also called floor function. The above algorithm is just a version of the greedy algorithm. In all cases, x(n) is a real number between 0 and 1, and a(n) is the n-th digit of x, in base b.
Once the digits in base b are known, it is easy to retrieve the number x, using the formula
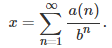
Typically, you need to use high performance computing if you want to compute more than 45 digits or so, due to limitations in machine precision. How to do it is described in chapter 8, in my book. It is not a challenging problem if you only need a few hundred, maybe 2,000 digits, which is the case in practice. Note that RSA, which relies on large prime numbers with hundreds of digits, also requires high precision computing.
Finally, note that two different numbers have two different representations in the same base, an advantage over hash functions (subject to collisions.)
2. Application to cryptography
You have a message x, to be transmitted, for example the binary (base-2) representation of your original, text message. You encode x in a base b, with b chosen between 1.5 and 1.9. The base b can even be a transcendental number.
Your encoded message simply consists of the digits of x in base b, and these digits can be shared publicly. What is kept secret is the base b, so that if an attacker knows the digits, he still can’t retrieve the message as he does not know the base. The base is the equivalent of a key in standard cryptographic systems.
If you know both the digits and the base, you can easily reconstruct the original message, though it will require a bit of high precision computing. As always, you split the original message (if it is too long) in blocks of (say) 512 bytes, and encode each block separately.
Challenges
As in all cryptographic systems, there are some challenges to overcome, to make it more robust against attacks.
One of the challenges here is not related to security, but about how many digits (in base b) you need to use to be able to reconstruct the full message. Based on entropy theory, it is likely that using twice as many digits than in the original base-2 version of the message, should be enough, if b is larger than 1.5. However, this has to be tested. Keep in mind that we encode small blocks one at a time, each block having up to 2,000 base-2 digits, though smaller blocks offer some advantages.
The other challenges are about the security of the system. Can an attacker try a large number of test bases to guess which base is used? Bases that are very close to each other will produce identical digits, at least for the first few digits. It might then be possible to use a dichotomic search to identify the secret base. Another issue is the distribution of 0’s and 1’s, as well as the auto-correlation structure of the digits, which allow you to identify the secret base, by performing some statistical analysis. In the next subsection, we address this issue.
Improving security
As discussed earlier, using a single base b produces a weak cryptographic system. Yet it still requires advanced statistical knowledge — not tools available on the dark net — to break it. And being a new system, it would probably take years before someone can do a successful attack. Indeed, agencies such as NSA might like it, because it appears at first glance to be safe enough to use in commercial applications, yet it gives the government a natural back door to decode messages.
The first idea that comes to mind to make this system stronger, is to use a mapping of x(n) to scramble the distribution of 0’s and 1’s: for instance, using x’(n) = SQRT(1 – x(n)), instead of x(n). You must also scramble the auto-correlation structure of the digits. The legit recipient of the message would have to know the base used for encoding, as well as the scrambling mechanism, to retrieve the original message. However it might be next to impossible to retrieve the original message after scrambling, even if you know all the scrambling parameters.
A much easier solution consists of using multiple bases, say two bases b and b’. Digits in even position come from base b, while digits in odd position come from base b’. The legit recipient must know both b and b’ to decode the message. More sophisticated versions of this trick can be implemented, to increase security. For instance, if a digit is equal to 0, the next digit is in the alternate base, otherwise it is in the same base as the current digit: so digits from both bases are interlaced in a more complex way.
Further research on the topic
A new approach consists of scrambling the distribution of x(n) as discussed in the previous sub-section, and making x(n) with (say) n = 3, the public encoded message. Note that x(n) is a real number — not an integer — so in practice it needs to be truncated, but kept long enough to be able to reconstruct the full original message.
If you know
- the base b (private),
- x(n) in that base after the scrambling (public),
- the number n (private),
- and the mapping used for scrambling (private),
then you can retrieve x(1) which is equal to x, using a dichotomic search. In this case, the base b, the number n, and the mapping function, constitutes the key used for decryption. The larger n, the more difficult it is to retrieve x for the legit recipient.
Final note
Readers interested in this article can write and submit a patent, about this technology. This content is offered as open intellectual property, and can be used in any application, commercial or not. Statisticians could be interested in doing simulations to see how easy or difficult it is to break this system, especially by analyzing the digit distribution to identify secret bases.
For related articles from the same author, click here or visit www.VincentGranville.com. Follow me on on LinkedIn.
DSC Resources
- Free Book: Applied Stochastic Processes
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Post a Blog | Forum Questions
{kind=link}