
Here I provide translations for various important terms, to help professionals from related backgrounds better understand each other. In particular, machine learning professionals versus statisticians.
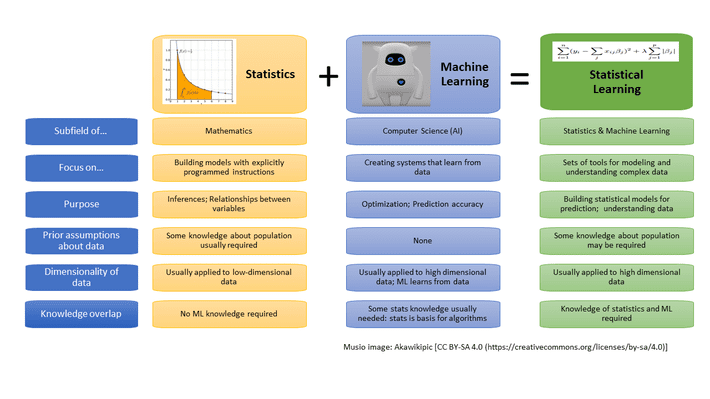
Source for picture: here
Feature (machine learning)
A feature is known as a variable or independent variable in statistics. It is also known as a predictor by predictive analytics professionals.
Response
The response is called dependent variable in statistics. Machine learning professionals sometimes call it the output.
R-square
This is the statistics used by statisticians to measure the performance of a model. There are many better alternatives. Machine learning professionals sometimes call it goodness-of-fit metric.
Regression
Sometimes called maximum likelihood regression or linear regression by statisticians. Physicists and signal processing / operations research professionals use the term ordinary least squares instead. And yes, it is possible to compute confidence intervals (CI) without underlying models. They are called data-driven, and rely on simulations and empirical percentile distributions.
Logistic transform
The term used in the context of neural networks is sigmoid. Statisticians are more familiar with the word logistic, as in logistic regression.
Neural networks
While not exactly the same thing, statisticians have they own multi-layers hierarchical networks: they are called Bayesian hierarchical networks.
Test of hypothesis
Business intelligence professionals call it A/B testing, or multivariate testing.
Boosted models
Boosted models are used by machine learning professionals to blend multiple models and get the best of each model. Statisticians call them ensemble techniques.
Confidence intervals
We are all familiar with this concept invented by statisticians. Alternative terms include prediction intervals, or error (not to be confused with predictive or residual error, as it has its own meaning for statisticians).
Grouping
Also known as aggregating, and consisting in grouping values of some feature or independent variable, especially in decision trees to reduce the number of nodes. Machine learning professionals call it feature binning.
Taxonomy
When applied to unstructured text data, the creation of a taxonomy (sometimes called ontology) is referred to as natural language processing. It is basically clustering of text data.
Clustering
Statisticians call it clustering. In machine learning, the concept is referred to as unsupervised classification. To the contrary, supervised clustering is a learning technique based on training sets and cross-validation.
Control set
Machine learning professionals use control and test sets. Statisticians use the term cross-validation or bootstrapping, as well as training sets.
Model fitting
The terms favored by machine learning professionals is model selection, testing, and feature selection. Model performance has its own statistical related term: p-value, though it less used recently.
False positives
Instead of false positives and false negatives, statisticians favor type I and type II errors.
Another similar dictionary can be found here.
About the author: Vincent Granville is a data science pioneer, mathematician, book author (Wiley), patent owner, former post-doc at Cambridge University, former VC-funded executive, with 20+ years of corporate experience including CNET, NBC, Visa, Wells Fargo, Microsoft, eBay. Vincent also founded and co-founded a few start-ups, including one with a successful exit (Data Science Central acquired by Tech Target). You can access Vincent’s articles and books, here.
{kind=link}