
Summary: In our recent article on “5 Types of Recommenders” we failed to mention Indicator-Based Recommenders. These have some unique features and ease of implementation that may be important in your selection of a recommender strategy.
A few weeks ago in the midst of our series on recommenders we published an article “5 Types of Recommenders” in which we offered our view on the primary types of recommendation engines. We got a very nice comment from Ted Dunning suggesting that we’d missed an important one, Indicator-Based Recommenders.
If you ever get a note from Ted Dunning you should pay attention. Ted is an elder statesman of the Big Data movement, currently Chief Application Architect for MapR, and a long time committer and leader for the Apache Institute. So we dug in for a little research and agreed with Ted that Indicator-Based was indeed worth talking about.
 You could forgive us a little bit for our oversight since Indicator-Based looks a whole lot like the ever popular Collaborative Filtering category. That is, while it’s good to have a lot of item-item features for filtering, what Indicator-Based and Collaborative Filtering focus on is the wisdom of the crowds, that is user-item relationships.
You could forgive us a little bit for our oversight since Indicator-Based looks a whole lot like the ever popular Collaborative Filtering category. That is, while it’s good to have a lot of item-item features for filtering, what Indicator-Based and Collaborative Filtering focus on is the wisdom of the crowds, that is user-item relationships.
What Indicator-Based brings to the table is the ability to deploy an effective analogue of Collaborative Filtering with a lot less complexity and a lot less work.
How the Data Science Differs
With Collaborative Filtering you use fairly straightforward matrix factorization to build tables that identify relationships between users with similar tastes (histories on your web site) and the items they consume.
Indicator-Based Recommenders rely on a similar approach with a different algorithm at the core, Log Likelihood Ratio (LLR). Given Ted’s long association with Apache Mahout it’s no coincidence that there is a single command line for this calculation ‘RowSimilarityJob’ in Mahout. And while what’s described here can be constructed from any of the major Hadoop distributions, it takes fewer steps using the tools that Ted has shepherded.
Perhaps the most unique characteristic of the Log Likelihood Ratio is that it can identify uncommon relationships (anomalous co-occurrences). It’s not the most commonly occurring similarities among users that make for good recommendations. That just results in everyone seeing the same list of recommendations. What LLR can distinguish are the relatively uncommon but statistically significant similarities and that’s the basis on which it scores recommendations.
Essentially the highest scores (the indicators) are assigned to the most anomalous co-occurrences. This allows these potential recommendations to be displayed in a priority order.
Ease of Development
The primary business case for Indicator-Based is that it delivers essentially all of the benefits with a lot less effort. Yes recommenders can be made more accurate by combining multiple algorithms in ever increasing complexity. But in every business case there needs to be an assessment of the tradeoff between the value of extra accuracy and the cost of development and maintenance. If you’re going to consider building your own, this is an analysis you definitely want to undertake at the beginning of your project before you select a path.
In the case of Indicator-Based the ease of development is based on the existence of Mahout based ‘RowSimilarityJob’ command which greatly simplifies creating the recommendation matrix. But creating the recommendations is only half the job.
The other half of the job is deploying the recommendations on your site and it also happens that Apache Solr, best known as a text search engine happens to be a particularly convenient mechanism for deploying the recommendations.
This is a browser-centric strategy that emphasizes the importance of what the user actually does on the site. Importantly, this also allows the whole recommender engine to be implemented as an add-on to your existing site search engine.
In Operation
In operation, updating the recommendation matrix typically happens overnight updated from the most recent day’s web logs, while the delivery of recommendations occurs in real time based on your visitor’s queries and actions.
Here the daily history matrix is processed through LLR to derive indicators that are appended to item JSON descriptions so they can be easily retrieved when that item is viewed or consumed.
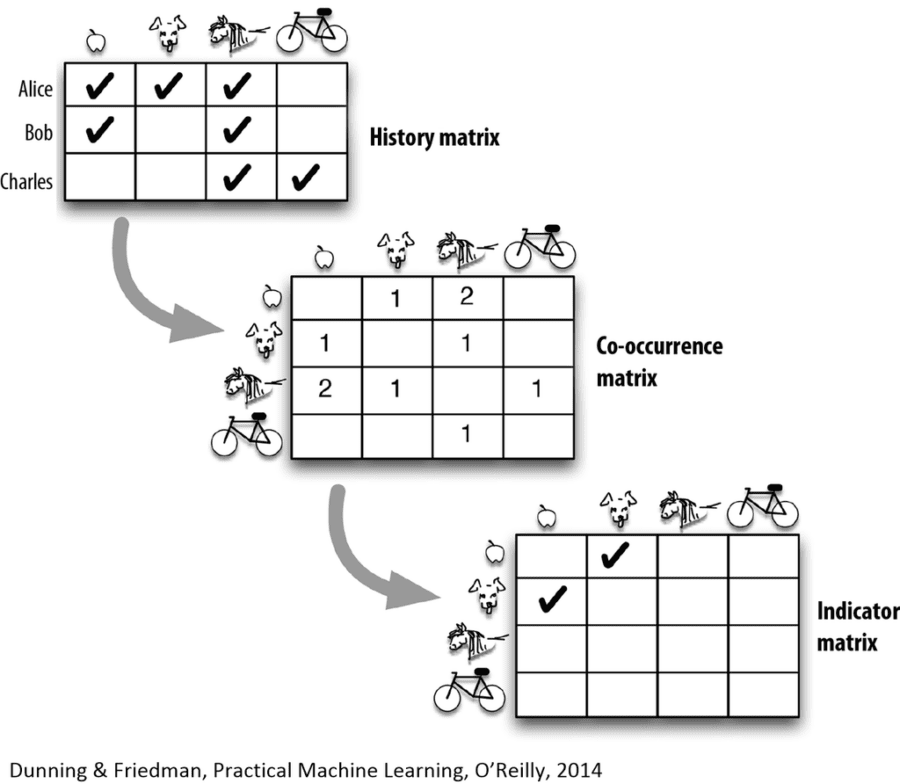
We mentioned earlier that this technique deemphasizes user ratings but it does not do away with the need for item attributes. Determining item attributes is sometimes easy, (as when those descriptors are provided as part of the product description or by a third-party source) and sometimes hard (e.g. news items that have extremely limited life span where the only option may be some type of NLP extraction). There still need to be enough item attributes to allow for meaningful filtering of like-with-like and sufficient for the user to make sense of the recommendation.
The high level architecture would look roughly like this:
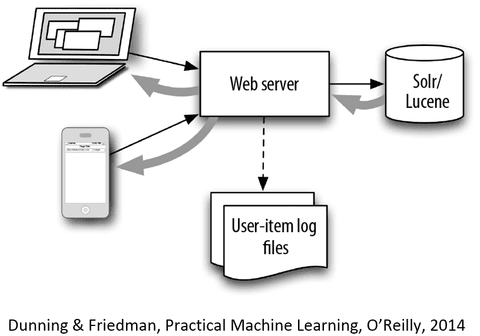
Implementation
The first issue with implementation is that no recommender can be better than the data used to train it. You will want to review the data you are capturing in your web logs and determine how it can be expanded and utilized. Many of these issues are not self-evident. A few examples:
- User consumption may not be simply what is selected or what is purchased. It can be enhanced by noting which pages or images have longer viewing time or more repeat views than others.
- User operating system. It’s unlikely that you should present recommendations for high tech solutions to a visitor who arrives via a particularly old version of Windows.
- Time of day: For example in movie recommenders visitors arriving early in the morning are probably not as open to an action-adventure movie and may be looking for something to distract young children.
- Out of stock: Rarely would you have a circumstance in which you would recommend an out of stock item.
These candidly heuristic observations are going to be unique to your business. Collaborating with a good Product Marketing Manager can probably yield a number of these rules that should be a front end filter to your recommendations.
Also, none of this is to take away from the fact that pre-implementation testing and a program of continuous testing and upgrading is critical.
There are still a variety of techniques to improve performance beyond this that are not strictly related to the type of recommender. As we observed in an earlier article, essentially all successful recommenders end up as hybrids of techniques and human-derived rules.
If you’d like a deeper dive on Indicator-Based Recommenders see this O’Reilly publication by Ted Dunning and Ellen Friedman.
Other Articles in this Series
Article 1: “Understanding and Selecting Recommenders” the broader business considerations and issues for recommenders as a group.
Article 2: “5 Types of Recommenders” details the most dominant styles of Recommenders.
Article 3: “Recommenders: Packaged Solutions or Home Grown” how to acquire different types of recommenders and how those sources differ.
Article 4: “Deep Learning and Recommenders” looks to the future to see how the rapidly emerging capabilities of Deep Learning can be used to enhance performance.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}