
This article was written by Jason Brownlee.
Artificial neural networks have two main hyperparameters that control the architecture or topology of the network: the number of layers and the number of nodes in each hidden layer. You must specify values for these parameters when configuring your network. The most reliable way to configure these hyperparameters for your specific predictive modeling problem is via systematic experimentation with a robust test harness. This can be a tough pill to swallow for beginners to the field of machine learning, looking for an analytical way to calculate the optimal number of layers and nodes, or easy rules of thumb to follow.
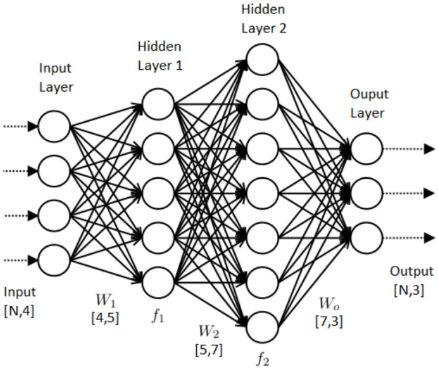
In this post, you will discover the roles of layers and nodes and how to approach the configuration of a multilayer perceptron neural network for your predictive modeling problem. After reading this post, you will know:
- The difference between single-layer and multiple-layer perceptron networks.
- The value of having one and more than one hidden layers in a network.
- Five approaches for configuring the number of layers and nodes in a network.
Let’s get started.
Overview
This post is divided into four sections; they are:
- The Multilayer Perceptron
- How to Count Layers?
- Why Have Multiple Layers?
- How Many Layers and Nodes to Use?
The Multilayer Perceptron
A node, also called a neuron or Perceptron, is a computational unit that has one or more weighted input connections, a transfer function that combines the inputs in some way, and an output connection. Nodes are then organized into layers to comprise a network.
A single-layer artificial neural network, also called a single-layer, has a single layer of nodes, as its name suggests. Each node in the single layer connects directly to an input variable and contributes to an output variable. A single-layer network can be extended to a multiple-layer network, referred to as a Multilayer Perceptron. A Multilayer Perceptron, or MLP for sort, is an artificial neural network with more than a single layer.
It has an input layer that connects to the input variables, one or more hidden layers, and an output layer that produces the output variables. We can summarize the types of layers in an MLP as follows:
- Input Layer: Input variables, sometimes called the visible layer.
- Hidden Layers: Layers of nodes between the input and output layers. There may be one or more of these layers.
- Output Layer: A layer of nodes that produce the output variables.
Finally, there are terms used to describe the shape and capability of a neural network; for example:
- Size: The number of nodes in the model.
- Width: The number of nodes in a specific layer.
- Depth: The number of layers in a neural network.
- Capacity: The type or structure of functions that can be learned by a network configuration. Sometimes called “representational capacity“.
- Architecture: The specific arrangement of the layers and nodes in the network.
To read the whole article, click here. For more articles on neural networks, follow this link.
DSC Resources
- Book and Resources for DSC Members
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist| Search DSC | Find a Job
- Post a Blog| Forum Questions
{kind=link}