
I recently wrote a blog “Interweaving Design Thinking and Data Science to Unleash Economic V…” that discussed the power of interweaving Design Thinking and Data Science to make our analytic efforts more effective. Our approach was validated by a recentMcKinsey article titled “Fusing data and design to supercharge innovation” that stated:
“While many organizations are investing in data and design capabilities, only those that tightly weave these disciplines together will unlock their full benefits.”
I even developed some Data Science playing cards that one could use to help guide this Design Thinking-Data Science interweaving process (see Figure 1).

Figure 1: The Design Thinking-Data Science Winning Hand
And while I wholeheartedly believe that Design Thinking and Data Science are two synergist disciplines for accelerating the creation of more effective, more predictive, more relevant analytic models, they really only address the first part of the Data Science development process – analytic model development.
The purpose of this blog is to discuss the critically important role of DevOps in driving the second part of the Data Science development process – analytic model operationalization and monetization.
Let’s jump into it…
Data Science and Analytic Model Development
I discussed in the blog “Why Is Data Science Different than Software Development?” how the data science and software development approaches are fundamentally different because Software Development Defines Criteria for Success; Data Science Discovers It.
As Data Science moves into the mainstream of more organizations, Product Development needs to understand the process for developing analytic models is different than the process for developing software. While they share many of the same foundational capabilities (i.e., strong team alignment, clearly defined roles, mastering version control, regular communications rhythm), the data science development process has some unique requirements such as:
- The presence of data to work with
- The Collaborative Hypothesis Development Process
- Data Exploration and Discovery Curiosity
- Mastering the Art of Failure
- Understanding When “Good Enough” is “Good Enough”
- Embrace a Continuously Learning/Retuning Process
The Data Science analytic model development journey is fraught with unknowns. The “known unknowns” and “unknown unknowns” only surface as the data science team moves along the analytic model development journey. Like in the original movie “Jason and the Argonauts”, a good data science team must be prepared for whatever evil monsters appear and adjust accordingly (see Figure 2).

Figure 2: Why Data Science is Different Than Software Development
But the operationalization (and ultimately the monetization) of the analytic models ultimately requires close collaboration between the Data Science and Software Development / DevOps teams.
Data Science and Analytic Model Operationalization
The Operationalization of the analytic models requires the integration of the Data Science and Software Development processes, and this integration process occurs around the organizations packaged and re-usable analytic modules (see Figure 3).
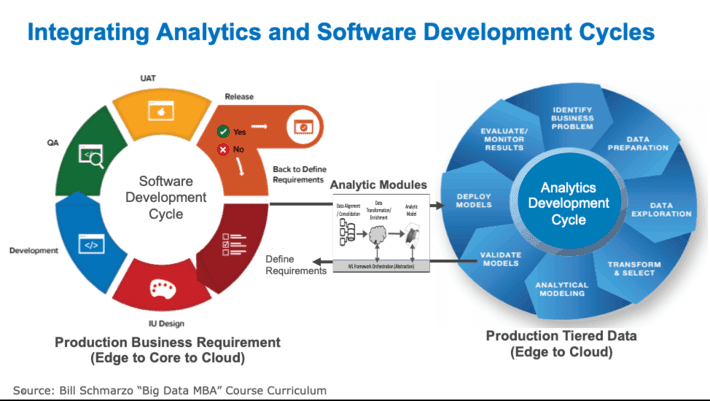
Figure 3: Integrating Analytics Development and Software Development
In the blog “Driving #AI Revolution with Pre-built Analytic Modules“, I asked “What is the Intelligence Revolution equivalent to the 1/4” bolt?” One of the key aspects of the Industrial Revolution was the creation of standardized parts – like the ¼” bolt – that could be used to assemble versus hand-craft solutions. So, what is the ¼” bolt equivalent for the AI Revolution? I think the answer is packaged, reusable and extensible Analytic Modules (see Figure 4)!
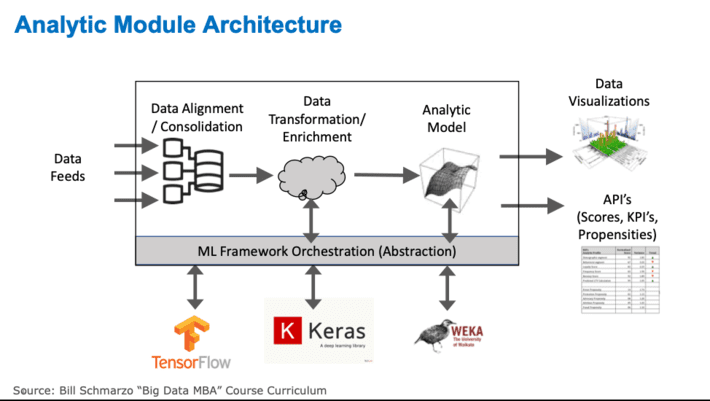 Figure 4: Packaged Analytic Modules
Figure 4: Packaged Analytic Modules
Analytic Modules form the basis for accelerating time-to-value and de-risking analytics projects because the Analytic Modules enable the sharing, re-using and refinement of the organization’s key analytic capabilities. They also address one of the greatest destroyers of the economic value of data and analytics – orphaned analytics.
Challenge of Orphaned Analytics
From our University of San Francisco Research paper on “Applying Economic Concepts to Determine the Financial (Economic) Va…”, several companies complained about the curse of “orphaned analytics”; which are one-off analytics developed to address a specific business need but never “operationalized” for re-use across the organization.
Unfortunately, many organizations lack an overarching model to ensure that the resulting analytics and associated organizational intellectual capital can be captured and re-used across multiple use cases. Without this over-arching analytics framework, organizations end up playing a game of analytics “whack-a-mole” where the analytics team focuses their precious and valuable resources on those immediate (urgent) problems, short-changing the larger, more strategic (important) analytic opportunities[1].
If you can’t package, share, re-use and refine your analytic models, then your organization misses the chance to exploit the almost famous “Schmarzo Economic Digital Asset Valuation Theorem” – the ability to leverage data and analytics to simultaneously drive down marginal costs while accelerating the economic value creation of digital asset as explained in Figure 5.
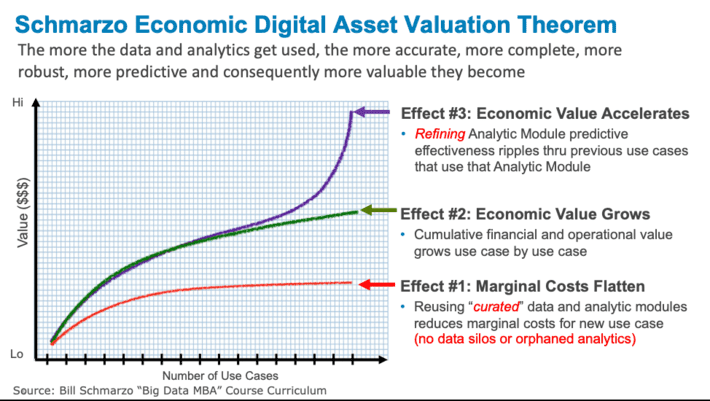 Figure 5: Schmarzo Economic Digital Asset Valuation Theorem
Figure 5: Schmarzo Economic Digital Asset Valuation Theorem
See the blog “Why Tomorrow’s Leaders MUST Embrace the Economics of Digital Transf…” for more details on the three economic effects that result from the sharing, re-use and refinement of the organization’s data and analytics digital assets.
Integrating Data Science and DevOps to Avoid Orphaned Analytics
The Operationalization of the analytic models requires the integration of the Data Science and software development or DevOps processes. DevOps is a set of software development practices that combines software development (Dev) and information technology operations (Ops) to shorten the systems development life cycle while delivering features, fixes, and updates frequently in close alignment with business objectives[2] (see Figure 6).
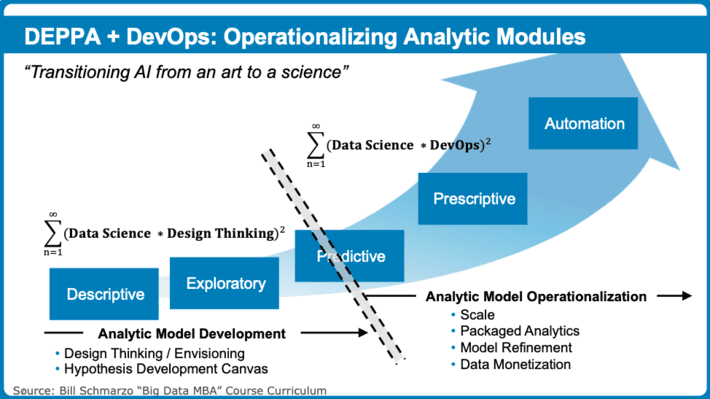
Figure 6: The Operationalizing Analytic Modules
The first half of Figure 6 covers the non-linear data science, analytic development process where the data science team will try different combinations of data, analytic algorithms, data enrichment and feature engineering techniques to create analytic models that are “good enough” given the required analytic accuracy and goodness of fit metrics. See the blog “Interweaving Design Thinking and Data Science to Unleash Economic V…” for more details how Design Thinking supports the Data Science development process.
However, the second half of Figure 6 is focused on the more traditional software development (DevOps) cycle, a linear process that supports the scaling, operationalization and ultimately monetization of the analytics. The analytic modules must be treated and managed as intellectual property (IP) or software assets complete with version control, check in/check out, and regression testing of analytic module modifications. Organizations must develop the ability to track and maintain model lineage and metadata in order to answer questions such as “What data was used to train this model?” and “Which libraries were used in producing these scores?”
It is at this point, where Effect #3: Economic Value of Digital Assets Accelerates of the “Economic Digital Asset Valuation Theorem” (see Figure 7).
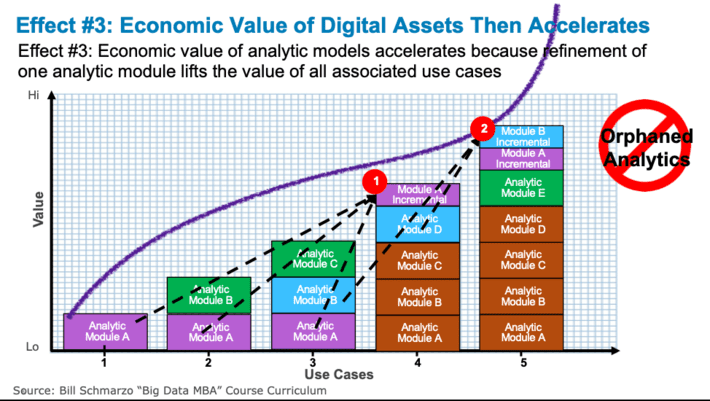
Figure 7: Effect #3: Economic Value of Digital Assets Accelerates
Figure 7 highlights how the cumulative Economic Value of the analytic assets accelerates through the continuous refinement of the analytic asset. Economic value of analytic models accelerates because refinement (via analytic module continuous learning and improvements) of one analytic module lifts the value of all associated use cases. See the blog “Economic Value of Learning and Why Google Open Sourced TensorFlow” to learn how leading digital companies like Google are exploiting the economics of digital assets to accelerate the creation of value.
I will be exploring the Data Science-DevOps relationship in more detail in future blogs as well explore the “Digital Asset Value Chain”from DataOps to Data Science to DevOps. Watch this space for more details!!
[1]See the blog “How to Avoid Orphaned Analytics” for more details on challenge of Orphaned Analytics.
[2]Source: Wikipedia: DevOps https://en.wikipedia.org/wiki/DevOps
{kind=link}