
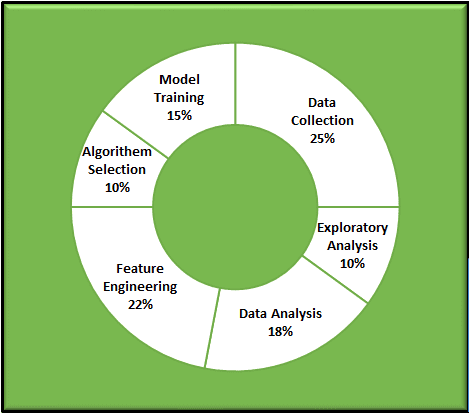
Data Science Lifecycle revolves around using various analytical methods to produce insights and applying Machine Learning techniques to do the predictions from the collected dataset. The main objective is to achieve a business challenge.
The entire process involves several steps like data cleaning, preparation, modeling, model evaluation, etc.
Depends on the nature of the data and problem statements, the % of the individual tasks might differ in the life cycle as shown in the above figure.
In this Lifecycle, the Feature Engineering is very important and very sensitive for model build and evaluation.
Let’s discuss in detail Feature Engineering
What is called Feature(s) in Data Science/Machine Learning?
- The FEATURE is nothing but the character or a set of characteristics of a given Dataset.
- Simply saying that the given columns/fields/attributes in the given dataset,
- Mostly Numeric data type-based columns/fields/attributes are straight features for the analysis.
- If not numeric, then those columns/fields/characteristics are converted into some measurable form, I mean, as Numerical category, then they would be taken into the account for analysis.
What is Feature Engineering?
• It is one of the major processes in the Data Science/Machine Learning life cycle. Here we are transforming the given data into a reasonable form, that is easier to interpret.
• Making data more transparent to helping the Machine Learning Model
• Creating new features to enhance the model.
Why we need Feature Engineering (FE)?
• NUMBER OF FEATURES could be significant could impact the model considerably, so that feature engineering is an important task in the Data Science life cycle.
• Certainly, FE is IMPROVING THE PERFORMANCE of machine learning models.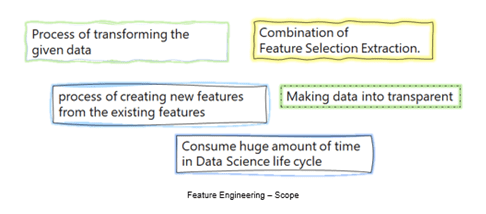
Challenges in Feature Engineering
· Certainly, feature engineering would consume a huge amount of time during the Data Science life cycle and leads to create stable models
· It requires data domain expertise and their involvement to create useful features for model building.
· The number of features could be significantly impacting the model, so that feature engineering is an important task in the Data Science life cycle.
· We should consider the relationship between features.
More on Feature Engineering
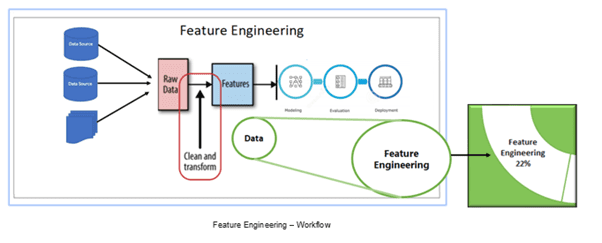
· A Feature Engineering includes as shown in the below figure,
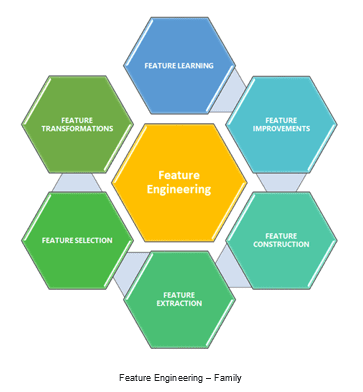
Feature Improvements: In this, we have the below techniques, and this would help us to enhance the features of the given dataset. Through this, we could bring better quality and quantity data set in meaningful ways by applying various mathematical methods.
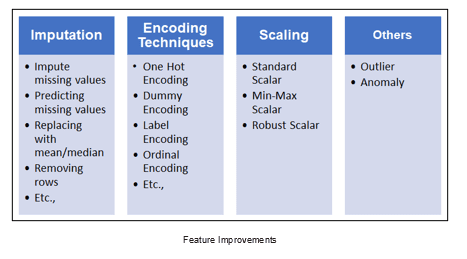
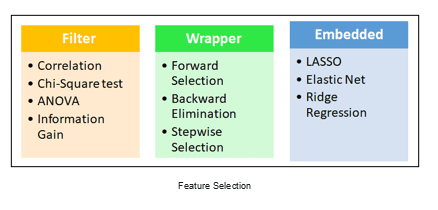
Feature Selection: This is one of the core concepts, which is hugely impacting the performance of your model. In this process, where you manually or automatically select those features that contribute most to your prediction or dependent variable, which you are interested in. Having irrelevant features in your dataset could decrease the accuracy of your models.
Feature extraction: Generation of features from the given dataset, that is in a format and difficult to analyze directly (e.g., images, time-series, etc.) In the example of a time-series, some simple features could be generated as the length of time-series, period, mean value, std, etc.
Feature Construction: This technique attempts to increase the expressive power of the original features. It is also called constructive induction or new attribute discovery. By adding derived features to the given dataset and helps to develop then accurate models.
I believe this article would help you all to understand what Feature Engineering is at a high level and a brief idea, Thanks for your time for reading this.
Cheers!!!
{kind=link}