
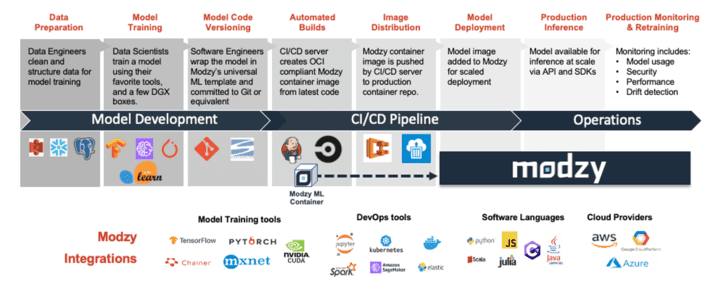
Welcome to the first installment in our series on ModelOps. This blog focuses on the importance of Data Gathering and Preparation in support of your AI projects and avoiding the common pitfalls.
Data is the heart of every AI investment, but data is not a monolithic concept. It comes in many different forms and sizes. For example, your data may be well structured and categorized, like the data you might find in a spreadsheet or database. Alternatively, your data could be an unstructured collection of text like newspaper articles or customer reviews. While many other types of data exist, these two categories – structured and unstructured – power the most common AI applications being developed today. It’s important to understand what it takes to gather and prepare these types of data to budget accordingly.
No one should be doing AI for the sake of doing AI—it must be tied to a clear business objective. Whether the AI application is aimed at improving internal process, developing a new consumer product, or gaining a competitive advantage, all AI applications stem from mining data. For this reason, well-conditioned data is vital to the AI development process. As a budget owner, the first question you need to ask is “How much is data acquisition and preparation going to cost?”
A complete answer to this question will cover eight areas.
- Does the team know where to find relevant data?
- Is data already available to your organization? …POS data for instance?
- Is there a cost to acquire the data?
- Is the data labeled?
- Will the labeling be done in-house or by a third party?
- Where will the data be stored?
- How will the data be conditioned and formatted for the AI application?
- How will the data be delivered to the team building the AI application?
The first thing to explore is the data provenance. There are a lot of good ideas for AI applications, with the caveat that the data can be acquired. Before green lighting any project, it is vital to have the team building the AI solution articulate the location of the data they are going to use so that you don’t waste money on other unnecessary expenses.
The second thing you need to clarify is whether or not the planned data source is available for use by your organization. Some questions that can help determine the answer to this include:
- Does your organization own the data?
- Does your group have the internal authority to hold the data (e.g., HR data is often restricted)?
- Is the data open source and free?
- Is it open source, but available only to members of a consortium?
- Is the data purchasable?
- And most importantly is the data the team plans to use licensed for commercial use?
Asking these kinds of questions puts you in a position to determine whether or not the data is a good fit for the kinds of AI applications you are considering.
Assuming that you are comfortable with the source and licensing constraints of the data, the next step is to understand costs. Some widely available datasets are freely available and licensed correctly for commercial use (e.g., Spacenet ), but other data is available to a restricted members only or commercial audience (e.g., Maxar imagery, Linguistic Data Consortium data). If your team is planning on using data sources from commercial or consortium sources, the cost of the data and membership fees can be a significant percentage of what you end up spending on building the AI application. Additionally, you need to ask about the completeness of the data. Will the data be ready to use when purchased, or will it need to be augmented, annotated, or labeled? If it needs to be labeled, will the team be doing that or will it require outside help? Asking these questions early can prevent sticker shock after a project is already underway.
Finally, to get a holistic view of the costs associated with data acquisition, you need to ask about the data storage and delivery mechanisms. Some data sets are simple and can easily be stored in databases on your network infrastructure, but other types of data like satellite imagery can require the kind of storage that you aren’t likely to have on hand (e.g. Petabyte level file systems) and may require cloud storage. Regardless of where and how the data is stored, someone will need to provide or build connections that makes it easy for the data science team to use for model development. Data engineers do this in large organizations, but in smaller organizations this role may very well be filled by a member of the IT department or the data science team. When you approve a project, you’re also approving the labor budget and the cost of data storage.
Investing in AI can dramatically shift how your organization operates. However realizing the advantages and measuring their impact requires a proper accounting of the total project cost to estimate ROI. Data acquisition costs are often an overlooked contributor to those costs. By asking the questions upfront, you’ll get a more complete view of data acquisition costs to make more informed decisions when authorizing AI investments.
Be sure to check out my next blog on Model Training: Our Favorite Tools in the Shed. Visit modzy.com to learn more, or feel free to connect with me on LinkedIn to discuss further.
{kind=link}