
DataOps is the use of agile development practices to create, deliver, and optimize data products, quickly and cost-effectively. DataOps is practiced by modern data teams, including data engineers, architects, analysts, scientists, and operations.
The data products which power today’s companies range from advanced analytics, data pipelines, and machine learning models to embedded AI solutions. Using a DataOps methodology allows companies to move fast in extracting value out of data.
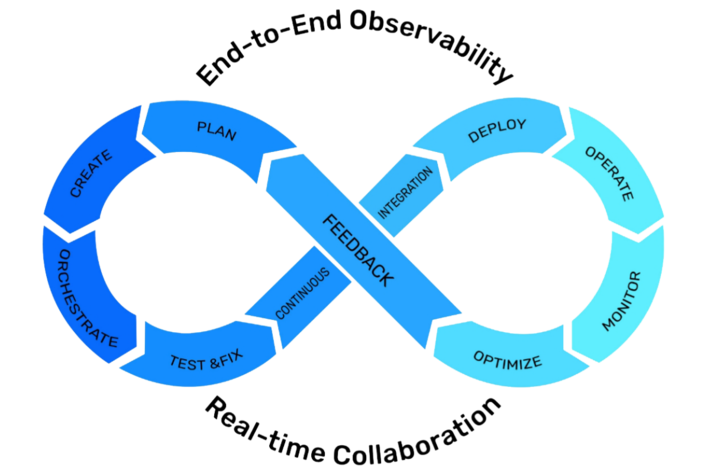
The ten steps of a DataOps lifecycle
The DataOps lifecycle shown below takes data teams on a journey from raw data to insights. Where possible, DataOps stages are automated to accelerate time to value. The steps below show the full lifecycle of a data-driven application:
- Plan. Define how a business problem can be solved using data analytics. Identify the needed sources of data and the processing and analytics steps that will be required to solve the problem. Then select the right technologies, along with the delivery platform, and specify budget and performance requirements.
- Create. Create the data pipelines and application code that will ingest, transform, and analyze the data. Based on the desired outcome, data applications are written using SQL, Scala, Python, R, or Java, among others.
- Orchestrate. Connect stages needed to work together to produce the desired result. Schedule code execution, with reference to when the results are needed; when cost-effective processing is most available; and when related jobs (inputs and outputs, or steps in a pipeline) are running.
- Test & Fix. Simulate the process of running the code against the data sources in a sandbox environment. Identify and remove any bottlenecks in data pipelines. Verify results for correctness, quality, performance, and efficiency.
- Continuous Integration. Verify that the revised code meets established criteria to be promoted into production. Integrate the latest, tested, and verified code and data sources incrementally, to speed improvements and reduce risk.
- Deploy. Select the best scheduling window for job execution based on SLAs and budget. Verify that the changes are an improvement; if not, roll them back, and revise.
- Operate. Code runs against data, solving the business problem, and stakeholder feedback is solicited. Detect and fix deviations in performance to ensure that SLAs are met.
- Monitor. Observe the full stack, including data pipelines and code execution, end-to-end. Data operators and engineers use tools to observe the progress of code running against data in a busy environment, solving problems as they arise.
- Optimize. Constantly improve the performance, quality, cost, and business outcomes of data applications and pipelines. Team members work together to optimize the application’s resource usage and improve its performance and effectiveness.
- Feedback. The team gathers feedback from all stakeholders – the data team itself, app users, and line of business owners. The team compares results to business success criteria and delivers input to the Plan phase.
There are two overarching characteristics of DataOps that apply to every stage in the DataOps lifecycle: end-to-end observability and real-time collaboration.
End-to-end observability
End-to-end observability is key to delivering high-quality data products, on time and under budget. You need to be able to measure key KPIs about your data-driven applications, the data sets they process, and the resources they consume. Key metrics include application/pipeline latency, SLA score, error rate, result correctness, cost of run, resource usage, data quality, and data usage.
You need this visibility horizontally – across every stage and service of the data pipeline – and vertically, to see whether it is the application code, service, container, data set, infrastructure, or another layer that is experiencing problems. End-to-end observability provides a single, trusted “source of truth” for data teams and data product users to collaborate around.
Real-time collaboration
Real-time collaboration is crucial to agile techniques; dividing work into short sprints, for instance, provides a work rhythm across teams. The DataOps lifecycle helps teams identify where in the loop they’re working, and to reach out to other stages as needed to solve problems – both in the moment and for the long term. Both in the moment and for the long term. That’s why open source data ops (OS) are becoming more popular these days. They provide flexibility for new and existing tools and they control the entire workflow and processes.
Real-time collaboration requires open discussion of results as they occur. The observability platform provides a single source of truth that grounds every discussion in shared facts. Only through real-time collaboration can a relatively small team have an outsized impact on the daily and long-term delivery of high-quality data products.
Why use a DataOps approach?
Through the use of a DataOps approach to their work, and careful attention to each step in the DataOps lifecycle, data teams can improve their productivity and the quality of the results they deliver to the organization. As the ability to deliver predictable and reliable business value from data assets increases, the business as a whole will be able to make more and better use of data in decision-making, product development, and service delivery. Advanced technologies, such as AI and machine learning, can be implemented faster and with better results, leading to competitive differentiation and, in many cases, industry leadership.
DataOps Unleashed Virtual Conference
What is the cost to attend the virtual sessions?
DataOps Unleashed is free and open for all to attend.
What is DataOps Unleashed?
DataOps Unleashed is the official DataOps community.
We’re coming together on March 17 as the emergence of DataOps, CloudOps, AIOps, MLOps, and other professionals, coming together to share the latest trends and best practices for running, managing, and monitoring data pipelines and data-intensive analytics workloads.
Sessions will include talks by DataOps professionals at leading organizations, detailing how they’re establishing data predictability, increasing reliability, and reducing costs.
Who’s coming to DataOps Unleashed?
DataOps professionals and experts including data administrators, data architects, data engineers, data analysts, AI/ML professionals, and data technology leadership.
Join us for sessions on:
- Data pipelines
- Data orchestration
- Metadata
- Data quality
- Data governance
- Data science platforms
- AIOps and MLOps
- CloudOps
- Migrations
- Observability
- Optimization
- Operations
{kind=link}