
Summary: Not enough labeled training data is a huge barrier to getting at the equally large benefits that could be had from deep learning applications. Here are five strategies for getting around the data problem including the latest in One Shot Learning.
 For at least the last two years we’ve been in an interesting period in which data, specifically training data is more important than algorithms. In the area of deep learning for problems involving image classification, the cost and effort to obtain enough labeled training data has held back progress for companies without the deep pockets to build their own.
For at least the last two years we’ve been in an interesting period in which data, specifically training data is more important than algorithms. In the area of deep learning for problems involving image classification, the cost and effort to obtain enough labeled training data has held back progress for companies without the deep pockets to build their own.
A 2016 study by Goodfellow, Bengio and Courville concluded you could get ‘acceptable’ performance with about 5,000 labeled examples per category BUT it would take 10 Million labeled examples per category to “match or exceed human performance”.
Any time there is a pain point like this, the market (meaning us data scientists) responds by trying to solve the problem and remove the road block. Here’s a brief review of the techniques we’ve introduced to help alleviate this, concluding with ‘One Shot Learning’, what that really means and whether it actually works.
Active Learning
Active learning is a data strategy more than a specific technique. The goal is to determine the best tradeoff between accuracy and the amount of labeled data you’ll need. Properly executed you can see the increases in accuracy begin to flatten as the amount of training data increases and it becomes an optimization problem to pick the right point to stop adding new data and control cost.
You can always employee your own manpower to manually label additional training images. Or you might try a company like Figure 8 that has built an entire service industry around their platform for automated label generation with human-in-the-loop correction. Figure 8 is a leading proponent of Active Learning and there’s a great explanatory video here.
New data can be labeled in one of two ways:
- Using human labor.
- Using a separate CNN to attempt to predict the label for an image automatically.
This second idea of using a separate CNN to label unseen data is appealing because it partially eliminates the direct human labor, but adds complexity and development cost.
The folks at the Stanford Dawn project for democratizing deep learning are working on several aspects of this including their open source application Snorkel, for automated data labeling.
Whether you use humans or machines, there will need to be a process for humans to check the work so that the new data doesn’t introduce errors into your models. All things considered, if you’re building a de novo CNN at scale, you should incorporate Active Learning in your data acquisition strategy.
Transfer Learning
 The central concept is to use a more complex and already successful pre-trained CNN model to ‘transfer’ its learning to your more simplified problem. The earlier or shallower convolutional layers of the already successful CNN have learned the features. In short, in TL we retain the successful front end layers and disconnect the backend classifier replacing it with the classifier for your new problem.
The central concept is to use a more complex and already successful pre-trained CNN model to ‘transfer’ its learning to your more simplified problem. The earlier or shallower convolutional layers of the already successful CNN have learned the features. In short, in TL we retain the successful front end layers and disconnect the backend classifier replacing it with the classifier for your new problem.
Then we retrain the new hybrid TL with your problem data which can be remarkably successful with far less data. Sometimes as few as 100 items per class but 1,000 is a more reasonable estimate.
Transfer Learning services have been rolled out by Microsoft (Microsoft Custom Vision Services, https://www.customvision.ai/, and Google (in beta as of last January Cloud AutoML) as well as some of the automated ML platforms.
One Shot Learning – Facial Recognition
There are currently at least two versions of One Shot Learning, the earliest of which addresses a facial recognition problem – suppose you have only one picture of an individual, an employee for example, how do you design a CNN to determine if that person’s image is already in your file when they present their face for scanning to gain access to whatever you’re trying to protect. In practice it works for any problem where you need to determine if the new image matches any image already in your database. Have we seen this person or thing before?
Ordinary CNN development would require retraining the CNN for each new employee to create a correct classifier for that specific person, because the CNN does not retain weights that can be applied to new unseen data it means basically training from scratch. It’s easy to see this would be a practical non-starter.
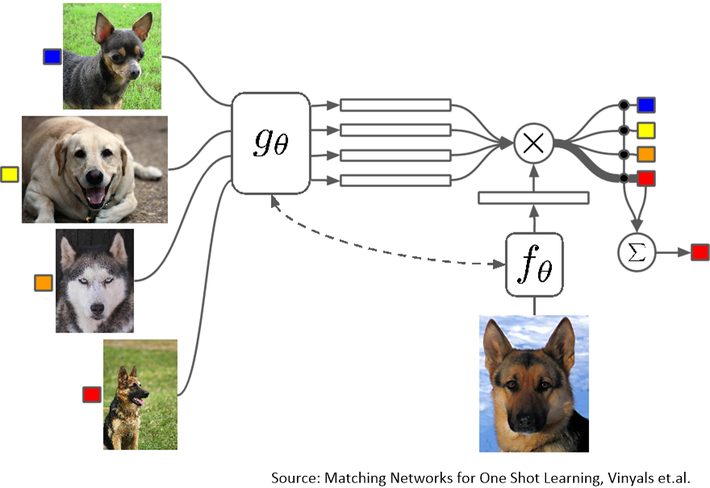 The solution is to use two parallel CNNs sometimes called Siamese CNNs and a new discriminator function called ‘similarity’ to compare the stored image vectors to the new image.
The solution is to use two parallel CNNs sometimes called Siamese CNNs and a new discriminator function called ‘similarity’ to compare the stored image vectors to the new image.
The original CNN is a fully trained network but lacks the classifier layer.
The second CNN analyzes the new image and creates the same dense vector layer as the original CNN.
The ‘similarity’ function compares the new image to all available stored image vectors and derives a similarity score (aka discriminator or distance score). High scores indicate no match and low scores indicate a match.
Although this is called a ‘One Shot’ learner, like all solutions in this category it works best with a few more than one, perhaps more like five or ten in the original CNN scoring base. Also, this approach solves for a specific type of problem comparing images but does not create a classifier required for more general problem types.
One Shot Learning – With Memory
In 2016 researchers at Google’s Deep Mind published a paper with the results of their work on “One Shot Learning with Memory Augmented Neural Networks” (MANN). The core of the problem is that deep neural nets don’t retain their node weights from epoch to epoch and if they could then the researchers reasoned they would be able to learn intuitively, more like humans.
Their system worked, using feed forward neural nets or LSTMs as the controller married to external memory storage at each node level.
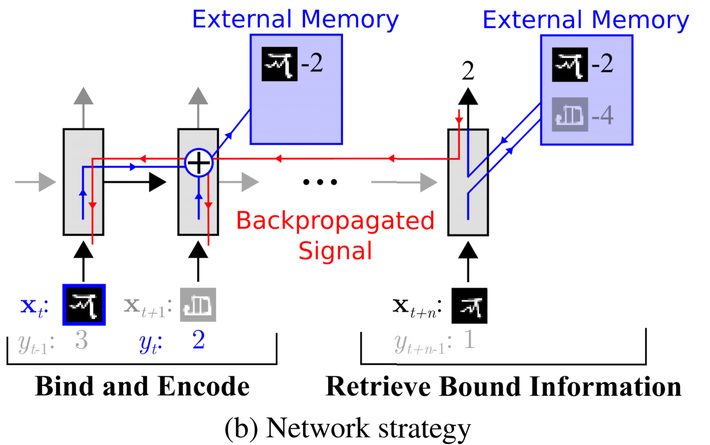 This diagram from their paper shows how the external storage is integrated into the network.
This diagram from their paper shows how the external storage is integrated into the network.
The MANN was then trained over more than 10,000 episodes with about 1600 separate classes with only a few examples each. After some experimental tuning the MANN was achieving over 80% accuracy after having seen a class object only four times, and over 95% accuracy having seen the class object ten times.
Where this has proven valuable is for example in correctly classifying hand written numbers or characters. In a separate example a MANN trained on numbers (the MNIST database) was repurposed to correctly identify Greek characters that it had not previously seen.
This may sound experimental but in the last two years it’s now possible to implement this fairly simply with the ‘one shot handwritten character classifier’ in Python.
GANNs – Generative Adversarial Neural Nets
Correctly classifying unseen objects based on only a few examples is great but there’s another way to come at creating training data and that’s with GANNs.
You’ll recall that this is about two neural nets battling it out, one (the discriminator) trying to correctly classify images and the second (the generator) trying to create false images that will fool the first. When fully trained the generator can create images that will make the discriminator identify them as a true image. Voila, instant training data.
You probably know GANNs from their more recent application, creating life like fakes of celebrities doing inappropriate things, or creating realistic images of non-existent people, animals, building, and everything else.
Personally I think GANNs are not quite ready for commercial rollout but they’re getting close. You should think of this as a bleeding edge application that may work out for you and it may not. There’s a lot we don’t yet really know about those generated images.
But Do They Generalize
If you need training data to differentiate dogs from cats, staplers from wastebaskets, or Hondas from Toyotas then by all means to ahead. However, I was asked by a Pediatric Cardiologist if GANNs could be used to create training data of infant hearts for the purpose of training a CNN to identify the various lobes of the tiny heart.
She would then use the inferenced CNN image to guide an instrument into the infant heart to repair defects. She didn’t yet have enough training data based on real CT scans of infant hearts and her application wasn’t sufficiently accurate.
It’s tempting to say that GANN generated images would be legitimate training data. The problem is that if she missed her intended target with her instrument it would puncture the heart leading to death.
Since all of our techniques are inherently probabilistic with both false positives and false negatives, there was no way I was comfortable advising that artificially created training data was OK.
So in all of these techniques from Transfer Learning to One Shot to GANNs, be sure to consider whether the small number of images you are using for training are sufficiently representative of the total environment and what the consequences of error might be.
Other articles by Bill Vorhies.
About the author: Bill is Editorial Director for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. He can be reached at:
{kind=link}