
Summary: 99% of our application of NLP has to do with chatbots or translation. This is a very interesting story about expanding the bounds of NLP and feature creation to predict bestselling novels. The authors created over 20,000 NLP features, about 2,700 of which proved to be predictive with a 90% accuracy rate in predicting NYT bestsellers.
 It’s a pretty rare individual who hasn’t had a personal experience with NLP (Natural Language Processing). About 99% of those experiences are in the form of chatbots or translators, either text or speech in, and text or speech out.
It’s a pretty rare individual who hasn’t had a personal experience with NLP (Natural Language Processing). About 99% of those experiences are in the form of chatbots or translators, either text or speech in, and text or speech out.
This has proved to be one of the hottest and most economically valuable applications of deep learning but it’s not the whole story.
I recently picked up a copy of a 2016 book entitled “The Bestseller Code – Anatomy of the Blockbuster Novel” which promised a story about using NLP and machine learning to predict which US fiction novels would make the New York Times Best Sellers list and which would not.
There are about 55,000 new works of fiction published each year (and that doesn’t count self-published). Less than ½% or about 200 to 220 make the NYT Bestseller list in a year. Only 3 or 4 of those will sell more than a million copies.
The authors, Jodie Archer (background in publishing), and Matt Jockers (cofounder of the Stanford Literary Lab) write about their model which has an astounding 90% success rate in predicting which books will make the NYT list using a corpus of 5,000 novels from the last 30 years which included 500 NYT Bestsellers.
The book, which I heartily recommend, is not a data science book, nor is it a how-to-write-a-bestseller. And while it has elements of both it’s mostly reporting about the most interesting finds among the 20,000 extracted features they developed, about 2,800 of which proved to be predictive. More on that later.
What struck me was the potential this field of ‘stylometrics’ has for extracting hidden features for almost any problem which has a large amount of text as one of its data sources. Could be CSR logs of customer interaction, could be doctor’s notes, blogs, or warranty repair descriptions where we’re really only scratching the surface with word clouds and sentiment analysis.
This is a great data science story because it illustrates just how deep you can go in extracting features (20,000) from text that can then be used alone or in conjunction with structured or semi-structured data features to enhance the accuracy of predictive models.
Not all their techniques applied to novels will translate to more pedestrian business problems but it ought to at least spark your imagination.
Stylometrics and Digital Humanities
A little preface. Apparently the academic world is fast embracing NLP in these techniques called ‘stylometrics’, part of the digital humanities movement. The best known applications so far are in author attribution. Who contributed to the Federalists Papers, was the Book of Mormon written by a single individual, did William Shakespeare really write all of those plays? The results so far have been quite good if not exactly headline grabbing.
I gather that the authors’ creation of this Bestsellerometer may be by far the most far reaching application.
I will not do justice to their findings in these brief notes. This will only give you an inkling of the many fun and counter intuitive findings that make a bestseller. Read the book.
Theme / Plot / Style / Character
If you remember your college lit courses you were almost certainly instructed to evaluate works of fiction along these four categories: theme, plot, style, and character. But how these four major variable groupings come together to predict bestsellers is in no way obvious.
Don’t readers for example care more about the genre? Aren’t romance, mystery, sci-fi, or historical fiction and the trends and memes generated around them more powerful predictors? What about author reputation? Does anyone stand a chance whose name isn’t Grisham, King, James, Larson, or their equally famous perpetual bestsellers? And isn’t it all about the marketing budgets the big publishers put behind proven names?
According to Archer and Jockers, none of these are true. That the ability of a first time author to breakout into instant bestseller status is based on factors they discover in the text itself, not in genre, reputation, or marketing budget. “The Girl Who Kicked the Hornet’s Nest”, “Fifty Shades of Grey”, “Gone Girl”, and “The Da Vinci Code” are only a few examples of unexpected breakouts.
Theme
Theme or topic as the authors define it has two aspects that can be examined with NLP. Using the topic modeling technique Latent Dirichlet Allocation (LDA) topics were distilled down to about 500 categories.
It’s important to note that there are likely to be many topics per story. For example, although John Grisham is noted for his courtroom-centered novels, not every page is about a courtroom. Topics could range from sex, drugs, and rock and roll, to the more likely marriage, intimate conversations, family life, and so forth.
Archer and Jockers discovered several interesting things here. First, if you’re going to write a bestseller you obviously have to appeal to a very wide audience. This means topics with very wide appeal like family life, human connection, or our relationship to technology.
Second, best sellers allocate about 30% to just one or two topics and 40% to more than three topics. Books that don’t make the list spread themselves out over six or more topics.
Topics that sell best are emotional and ethical topics. Inflammatory topics are kept to a minimum. Best predictors or success are: “human closeness and human connection: people communicating in moments of shared intimacy, shared chemistry, shared bonds”.
Of course every story needs a conflict to be resolved so topics need to support that. For example: “children and guns, faith and sex, love and vampires”.
You thought “50 shades of Grey” was about kinky sex. Think again. NLP shows it hews to the rules for bestsellers by incorporating 21% human closeness, 13% intimate conversation (those two topics make more than 30%), 13% sex, seduction, and the female body (so the third topic takes us to 40%).
Plot
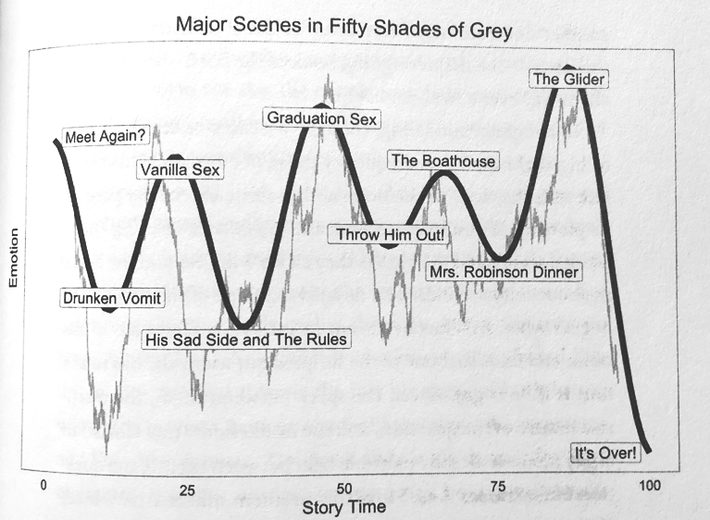 Using time series analysis in conjunction with NLP it’s possible to tell when the mood of the story turns from positive to negative and back again. In other words, where are the plot’s highs and lows.
Using time series analysis in conjunction with NLP it’s possible to tell when the mood of the story turns from positive to negative and back again. In other words, where are the plot’s highs and lows.
Archer and Jockers find seven major plotline trajectories and to be a bestseller you need to follow one of these. Also, you better get to the first reversal early in the book to hook your readers. Here’s the plotline for “50 Shades of Grey” as determined by NLP (the light grey line) overlaid with the authors’ interpretation.
Style
Great writing style for most of us is like great art, we know it when we see it. Turns out however that writing style as interpreted by NLP is a powerful predictor. The authors found that only 148 features based on only the most common filler words and punctuations, no nouns, adjectives, syntax or sentence data included could predict bestsellers 68% of the time.
This points to another interesting difference with common approaches to NLP. While in typical NLP we go to great lengths to remove or ignore punctuation, filler words and the like, in stylometrics everything counts and gets counted.
Not only do we need to count every comma, colon, and exclamation mark, but every use of filler words like ‘the’, ‘of’, ‘a’, ‘and’, ‘but’, syntax, sentence length, parts of speech, and counts for common verbs, nouns, adjectives, and adverbs. Noun to adjective ratio among others is important.
Using this technique alone is at the heart of author attribution. Apparently like fingerprints, our writing styles based on word use and punctuation is quite unique.
As for bestsellers, the authors observe that the word “do” is “twice as likely to appear in a bestseller than in a book that never hit the list. The word ‘very’ is only about half a common in bestsellers as in books that don’t make it.”
Character
You would think that defining character with NLP would be the most elusive challenge but the authors found predictive variables in looking at the way characters behave, based on their action verbs.
Taking direct action is much more powerful than thinking, or considering, or pondering.
“Regardless of whether the character is male or female, bestselling protagonists have and express their needs. The want things and express it. They know control and express agency. Verbs are clean and self-assured.” Verbs like grab, do, think, ask, look, hold, tells, likes, sees, hears, smiles, reaches define bestselling characters. Characters who demand, who seem, who wait, who interrupt, do not.
About the Data Science
Archer and Jockers started this project with their first model and more limited corpus on which to train in 2008 achieving 70% to 80% accuracy. That’s pretty amazing in itself considering that Hadoop and other NoSQL databases were fresh out of the box at the time.
The current book is based on work that occurred mostly in 2015 which many of you will recognize as a period when our ML techniques were still improving fast.
Jockers, the data scientist, describes using KNN (K Nearest Neighbor), NSC (Nearest Shrunken Centroids), and SVMs (Support Vector Machines) for their ML classification model. Best results by a wide margin were had with KNN.
I was rather hoping the results might have been revisited with some more modern or powerful techniques. GBM, XGboost, or genetic programs come to mind. However, their 90% accuracy rate is certainly good.
And if you were wondering, yes there was one and only one book out of 5,000 in their corpus that received a perfect 100 score predicting it would be a bestseller, “The Circle” by Dave Eggers. It’s on my to do list. Haven’t read it yet.
Meanwhile, hope this story about different approaches to creating features from text more broadly applied than our typical NLP, has spurred your imagination for your next text heavy project. If you want to pursue stylometrics, Matt Jockers has a book out “Text Analysis with R for Students of Literature”.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2 million times.
He can be reached at:
{kind=link}