
Deploying Natural Language Processing for Product Reviews
Introduction
We have data all around us and there are of two forms of data namely; tabular and text. If you have good statistical tools tabular data has a lot to convey. But it is really hard to get something out of the text, especially the natural language spoken text. So what is natural language? We, humans, have very complex language and natural language is the true form of human language which is spoken/written with sincerity also surpassing grammatical rules. To consider the best example where you can find this language is in “Reviews”. You write review mainly for two reasons, either you are very happy with the product or very disappointed with it and, with your reviews and a Machine Learning Algorithm, entities like Amazon can figure out whether the product they are selling is good or bad. Depending upon the results on the analysis of the reviews they can make further decisions on that product for their betterment.
Consider an example wherein we have thousands of comments in a review of a product sold by Amazon. It is very time consuming and hard for an individual to sit back and read all the thousands of comments and make a decision about whether people are liking the product or not. We can simply make machines do this work by implementing a Machine Learning Algorithm from which Machines can learn the Natural Human Language and make decisions. An approach to this is Machine “bags” words basically of two types viz; positive and negative words. After bagging these words machines apply majority rules to identify: are there more of positive or negative words thus helping us identifying the acceptance of the product sold.
The technique described above is called as “Bagging of Words (BoW)” Natural Language Processing (NLP) Machine Learning Algorithm which is what we are going to learn today and also could have been this complex name of this blog but phew, I managed with a better one. So, there are other techniques too called as Word Embedding NLP and might be more but as far as I know, they are these two. Today we are only focusing on “BoW” type of NLP in this article.
BoW NLP Implementation Road Map
Implementing this algorithm is little complex and can be confusing as it is longer than the usual algorithm process. So, below is the block diagram or a road map to give you an idea about the steps to implement this algorithm and finally make predictions with it. You can always fall back on this diagram if confused to understand why a particular thing is being done!
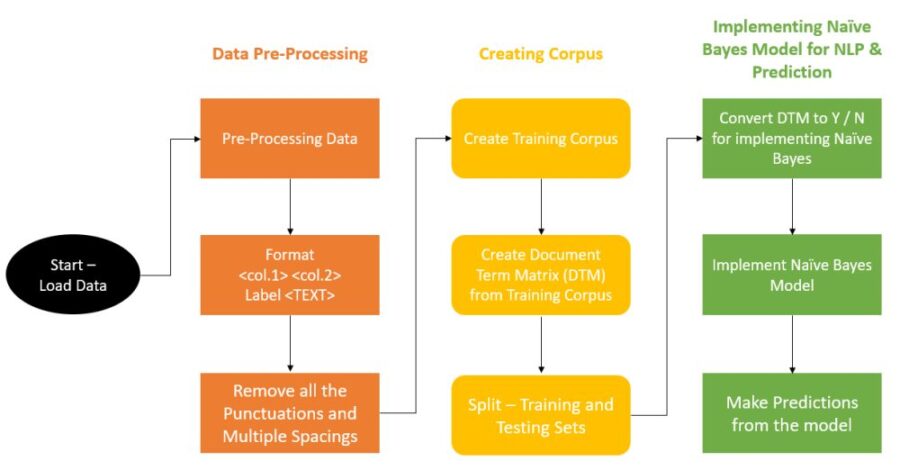
Flow chart of implementing BoW NLP algorithm
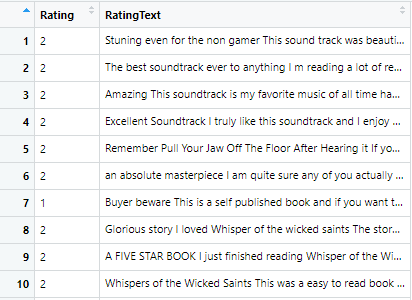
For machines to learn our natural language they need to be provided a certain format. Thus, we need to do data pre-processing so that we present data in a certain way expected by the machines to make them learn. In pre-processing we have to make sure data is in strictly two columns one for Rating and other for RatingText. Rating is either 1 or 2 (negative and positive respectively) and Rating Text will be equivalent rating text or review. Rating Text should not have unusual spacing and no punctuation. Below is the two snippets showing the data before and after pre-processing so that you understand better.

Data before pre-processing
Data after pre-processing
The next step is creating Corpus (Bag of Words) which can be easily done by a function in R (addressed later during listings). From this corpus, we then create Document Term Matrix (DTM) wherein a matrix represents the number of times a word is repeated throughout the entire corpus. Once we have the document term matrix we then split our data into training and testing sets.
The last step is implementing our model. Here we are deploying the Naive Bayes model, once implementing the model on the training data set we later make predictions on the test data set using the model created. In the end, we will compute the accuracy of our prediction to estimate how well our model performed in making predictions.
Model Data
The data is Amazon review data set, it is open data set available for use which was made available by Xiang Zhang. It was constructed as review score 1 for negative and 2 for positive ratings, it has in total 1,800,000 training and 200,000 testing samples. Don’t worry we are just using 1000 of the instances to avoid computational complexities. The data is available for download at the link below:
https://drive.google.com/file/d/1SncEr1yOBW4OmxWIYaKsNw_MS1Rh8S8j/v…
Just you need to make sure, when you have the file downloaded convert it into .csvformat so that you can use for analysis in R.
Model
Pre-processing Data
First things first as mentioned before we will begin with our data pre-processing. We will load our data first, followed by converting it into a data frame from a character string and then we will separate the data into two columns viz. “Rating” and “RatingText”. We can separate using a R function of the library “tidyr”. Below are the listings.

Listing for loading 1001 lines of Amazon Review Data set

View of the first 10 rows of the loaded data

Listing for Separating data into 2 columns “Rating” & “RatingText”

View of first 10 rows of data separated
Now we need to make sure we retain only alphanumeric entries of the data and removing anything other than that. Below is the listing to do that for both the separated columns.

Retaining only alphanumeric entries in the data
Lastly, we need to remove unwanted spacing in the text. Below is the listing for removing the unusual spacing and maintaining a single spacing throughout
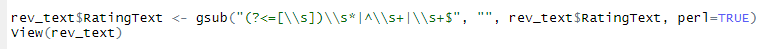
Removing unusual spacing
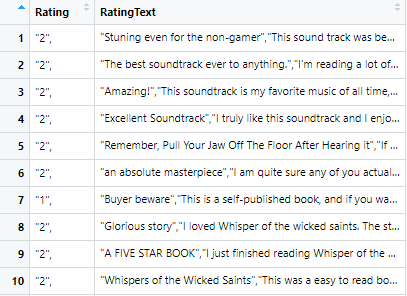
View of removed spacing data
We now simply put our data into an object named “text” and check the data dimension to be sure that complete data is written to the object.
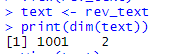
Console view of defining an object “text” and storing our data
The dimension print above of the text makes sure we have entire data into the object text.
Creating Corpus
Our next step includes creating corpus this can be easily done with a function VCorpus – Volatile Corpus from the library tm. To access this function one can download the package tm with install.packages(“tm”) followed by loading the library in R environment using library(tm). Once loaded we can use tm() function. This function will convert our review text into corpus.

Listing for creating corpus using tm() function
From the volatile corpus, we create a Document Term Matrix (DTM). A DTM is a sparse matrix that is created using the tm library’s DocumentTermMatrix function. The rows of the matrix indicate documents and the columns indicate features, that is, words. The matrix is sparse because all unique unigram sets of the dataset become columns in DTM and, as each review comment does not have all elements of the unigram set, most cells will have a 0, indicating the absence of the unigram.
While it is possible to extract n-grams (unigrams, bigrams, trigrams, and so on) as part of the BoW approach, the tokenize parameter can be set and passed as part of the control list in the Document Term Matrix function to accomplish n-grams in DTM. It must be noted that using n-grams as part of the DTM creates a very high number of columns in the DTM. This is one of the demerits of the BoW approach, and, in some cases, it could stall the execution of the project due to limited memory. As our specific case is also limited by hardware infrastructure, we restrict ourselves by including only the unigrams in DTM in this project. Apart from just generating unigrams, we also perform some additional processing on the reviews text document by passing parameters to the control list in the tm library’s DocumentTermMatrix function. The processing we do on the review text documents during the creation of the DTM are:
- All the text will be in lower case
- Removing number, if any
- Removing Stop words such as a, an, in, and the. As stop words do not add any value in analyzing sentiments
- Removing Punctuation, again they do not add any meaning in the analyzing sentiments
- Perform stemming, that is converting a word into its natural form example removing s from plurals
Below is the listing for creating DTM from our Volatile corpus and doing the above mentioned pre-processing
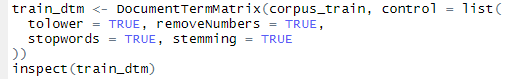
Listing for creating DTM and pre-processing
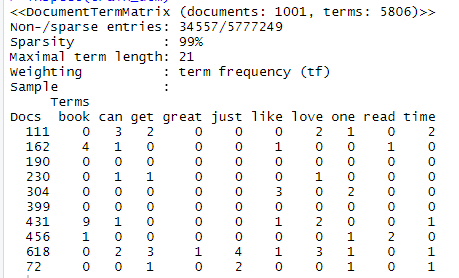
Inspect View of our train_dtm
Above we can see how our DTM is created where rows indicate document and columns indicate features as explained before. We see the output has 1001 documents with 5806 columns representing unique unigram from the reviews. We also see our DTM is 99% sparse and consists of non-zero entries of only 34,557 cells. The non-zero cells represent the frequency of occurrence of the word on the column in the document represent on the row of the DTM. The DTM tends to get very big, even for normal-sized datasets. Removing sparse terms, that is, terms occurring only in very few documents, is the technique that can be tried to reduce the size of the matrix without losing significant relations inherent to the matrix. Let’s remove sparse columns from the matrix. We will attempt to remove those terms that have at least a 99% of sparse elements with the following listings:

Removing 99% of sparse elements
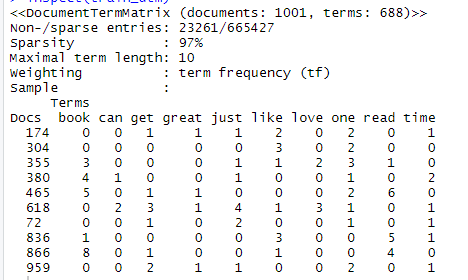
Inspection after removing Sparse
We now see the sparsity being reduced to 97% and the number of unigrams reduced to 688. We can now implement our algorithm but first let us split our data into training and testing sets.

Splitting data into Training and Testing sets for implementing algorithm
Once we have the data split we can now build our model on the Training set and later we can test our model for prediction on the testing set.
Implementing Naive Bayes Model
One point to be noted is that Naive Bayes model works on the nominal data. And our data currently has entrees which are for the number of times a word is being repeated and number of times a word gets repeated does not affect our sentiment thus we can convert our data into nominal data with following rule: number exists = Y and if 0 then N. Below is the listing to do this:

Listing for converting data to Nominal Data
Snippet view of converted nominal data
Now as we have nominal data we can implement a Naive Bayes model. The Naive Bayes algorithm can be implemented with function naiveBayes() in R library e1071. If you do not have this library you can use the following codes to install the package followed by loading it into the R environment as follows:

Listing to Install and use e1071 package
Below is the listing to implement Naive Bayes model

Listing to implement Naive Bayes model
Finally, with the model in hand, we will now make predictions for the test data set and check for the accuracy of the predictions done by the model. Below are the listing and checking accuracy

Listing for computing predictions and checking accuracy

Accuracy obtained from the model
With the quick implementation of BoW alongside with Naive Bayes model we got an accuracy of 79.5%. The accuracy can be increased further by focusing on the addition of different elements like new feature creation and so on.
BoW NLP – Takeaways
Bag of Words (BoW) Natural Language Processing (NLP) using a Naive Bayes model is very simple to implement algorithm when it comes to examining Natural language by Machines. Without very much efforts the model gives us a prediction accuracy of 79.5% which is a really good accuracy when it comes to simple model implementation. The only drawback of BoW is that it does not undertake the semantics of the words; example “buy a used bike” and “purchase old motorcycle”, BoW will treat them as two very different sentences. To overcome this we need to take another method known as Word Embedding into consideration.
Read more here
{kind=link}