
Summary: Move over RNN/LSTM, there’s a new algorithm called Calibrated Quantum Mesh that promises to bring new levels of accuracy to natural language search and without labeled training data.
 There’s a brand new algorithm for natural language search (NLS) and natural language understanding (NLU) that not only outperforms traditional RNN/LSTM or even CNN algos, but is self-training and doesn’t require labeled training data. Sounds almost too good to be true but the original results are quite impressive.
There’s a brand new algorithm for natural language search (NLS) and natural language understanding (NLU) that not only outperforms traditional RNN/LSTM or even CNN algos, but is self-training and doesn’t require labeled training data. Sounds almost too good to be true but the original results are quite impressive.
Calibrated Quantum Mesh (CQM) is the handiwork of Praful Krishna and his team at Coseer in the bay area. While the company is still small they have been working with several Fortune 500 companies and have started making the rounds of the technical conferences.
Here’s where they hope to shine:
Accuracy: According to Krishna, the average NLS feature in the ever more important chatbot is typically only about 70% accurate. The Coseer initial applications have achieved accuracy above 95% in returning the correct meaningful information. No keywords required.
No Labeled Training Data Required: We’re all aware that labeled training data is the cost and time sink that limits the accuracy of our chatbots. A few years back M.D. Anderson abandon its expensive and longtime experiment with IBM Watson for oncology because of accuracy. What was holding back accuracy was the need for very skilled cancer researchers to annotate the documents in the corpus instead of tending to their research.
Speed of Implementation: Without training data, Coseer says most implementations can be up within 4 to 12 weeks with the user exposing the system to the in house documents on top of the pretrained system.
Also different from the current major providers using traditional deep learning algos, Coseer choses to implement either on prem or with private clouds for data security. All of the ‘evidence’ used to come to any conclusion is stored in a log that can be used to demonstrate transparency and compliance with data security regulations like GDPR.
How Does This Work
Coseer talks about three principles that define CQM:
 Words (variables) have different meanings. Consider “report” which can be either noun or verb. Or “poor” which can mean “having little money” or “or substandard quality” or its homonym “pour” itself either noun or verb. Deep learning solutions including RNN/LSTM or even CNN for text can look only so far forward or back to determine ‘context’. Coseer allows for all possible meanings of a word and applies a statistical likelihood to each based on the entire document or corpus. The use of the term ‘quantum’ in this case relates only to the possibility of multiple meanings, not to the more exotic superposition of quantum computing.
Words (variables) have different meanings. Consider “report” which can be either noun or verb. Or “poor” which can mean “having little money” or “or substandard quality” or its homonym “pour” itself either noun or verb. Deep learning solutions including RNN/LSTM or even CNN for text can look only so far forward or back to determine ‘context’. Coseer allows for all possible meanings of a word and applies a statistical likelihood to each based on the entire document or corpus. The use of the term ‘quantum’ in this case relates only to the possibility of multiple meanings, not to the more exotic superposition of quantum computing.
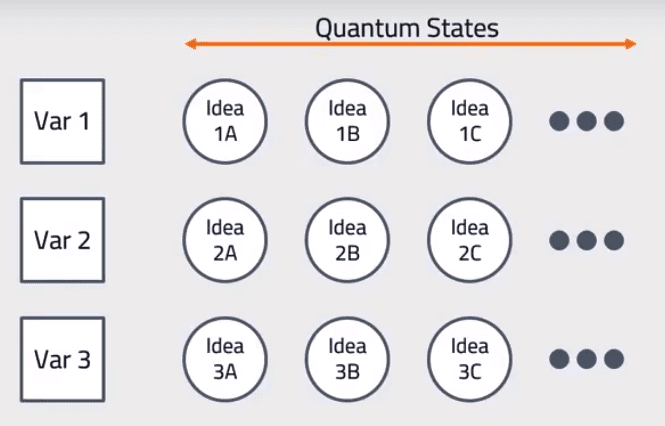 Words (variables) have different meanings. Consider “report” which can be either noun or verb. Or “poor” which can mean “having little money” or “or substandard quality” or its homonym “pour” itself either noun or verb. Deep learning solutions including RNN/LSTM or even CNN for text can look only so far forward or back to determine ‘context’. Coseer allows for all possible meanings of a word and applies a statistical likelihood to each based on the entire document or corpus. The use of the term ‘quantum’ in this case relates only to the possibility of multiple meanings, not to the more exotic superposition of quantum computing.
Words (variables) have different meanings. Consider “report” which can be either noun or verb. Or “poor” which can mean “having little money” or “or substandard quality” or its homonym “pour” itself either noun or verb. Deep learning solutions including RNN/LSTM or even CNN for text can look only so far forward or back to determine ‘context’. Coseer allows for all possible meanings of a word and applies a statistical likelihood to each based on the entire document or corpus. The use of the term ‘quantum’ in this case relates only to the possibility of multiple meanings, not to the more exotic superposition of quantum computing.- Everything is Correlated in a Mesh of Meanings: Extracting from all the available words (variables) all of their possible relationships is the second principle. CQM creates a mesh of possible meanings among which the real meaning will be found. Using this approach allows the identification of much broader interconnections between previous or following phrases than traditional DL can provide. Although the number of words may be limited, their interrelationships may number in the hundreds of thousands.
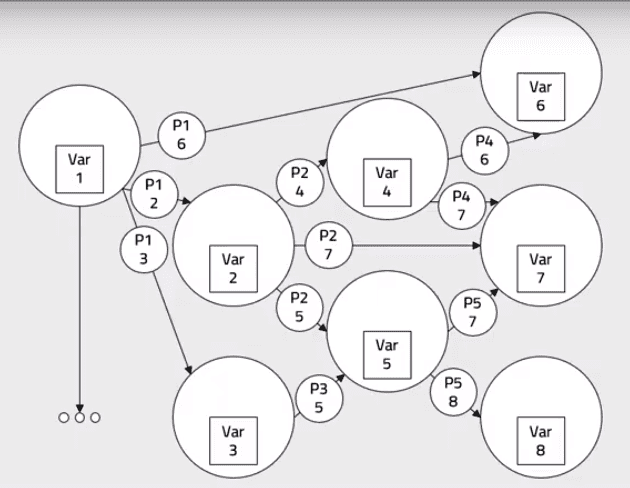 Everything is Correlated in a Mesh of Meanings: Extracting from all the available words (variables) all of their possible relationships is the second principle. CQM creates a mesh of possible meanings among which the real meaning will be found. Using this approach allows the identification of much broader interconnections between previous or following phrases than traditional DL can provide. Although the number of words may be limited, their interrelationships may number in the hundreds of thousands.
Everything is Correlated in a Mesh of Meanings: Extracting from all the available words (variables) all of their possible relationships is the second principle. CQM creates a mesh of possible meanings among which the real meaning will be found. Using this approach allows the identification of much broader interconnections between previous or following phrases than traditional DL can provide. Although the number of words may be limited, their interrelationships may number in the hundreds of thousands.- Use All Available Information Sequentially to Converge the Mesh to a Single Meaning. This process of calibration rapidly identifies missing words or concepts and enables very fast and accurate training. CQM models use training data, contextual data, reference data, and other facts known about the problem to define these calibrating data layers.
 Use All Available Information Sequentially to Converge the Mesh to a Single Meaning. This process of calibration rapidly identifies missing words or concepts and enables very fast and accurate training. CQM models use training data, contextual data, reference data, and other facts known about the problem to define these calibrating data layers.
Use All Available Information Sequentially to Converge the Mesh to a Single Meaning. This process of calibration rapidly identifies missing words or concepts and enables very fast and accurate training. CQM models use training data, contextual data, reference data, and other facts known about the problem to define these calibrating data layers.Unfortunately Coseer has released very little in the public domain to explain the technical aspects of the algorithm. Based on the repeated references to ‘relationship’ and ‘nodes’ we can probably infer this is a graph DB application, and I would bet using a DNN architecture to work through all the permutations in a reasonable amount of time.
Any breakthrough in eliminating labeled training data is to be applauded and certainly the increased accuracy will result in many more happy customers using your chatbot.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2 million times.
He can be reached at:
[email protected] or [email protected]
{kind=link}