

Semantic data consultant @EmekaOkoye made a couple of great points on Twitter back in November and early December 2021:
- “I am amused how some of us are pretending that #SmartAgent [tech] is not going to be a thing.”
- “With a #KnowledgeGraph of provenance data, lying to a blockchain will be harder.”
Agents: An expanding, but still underused, umbrella category
Semantic data model benefits can often be both cumulative and synergistic. That’s particularly the case when logic (in the form of “code”) becomes more capable when stored and managed as knowledge instead–as machine-readable, shareable, contextualized subsets of data that harness predicate logic (e.g., set theory)) in the form of knowledge graphs.
The convergence of blockchains (distributed ledgers) and decentralized knowledge graphs allow the dynamic enrichment of logic that ends up in a graph. That logic can make up the declarative part of code in agents, and it can logically disambiguate or abstract the kinds of statements agents use in smart contracts.
Agents (code that takes action anonymously on your behalf), for example, are hardly a new thing. Ecommerce bots such as WeChat and Shopify Messenger that automate parts of the online search process for eCommerce consumers have been commonplace for years now, not to mention smart bots for many other use cases.
But agents gained new capabilities when smart contracts appeared. The concept of smart contracts blends the power of software agents and agreements or contracts. Software agent techniques enabled contracts to become self-executing.
Smart contracts should be double the power of simpler agents (such as the eCommerce bots), but to date have often been more than double the trouble, which is why most smart contracts are still unilateral (i.e., customer has to accept the fixed terms of the provider) and still in their infancy.
To harness those new capabilities at scale in decentralized, resource-sharing environments such as blockchains and peer-to-peer data networks needed for supply chain and overall compliance visibility, smart contracts need to be much more trustworthy. Otherwise, whole supply chains could be compromised.
Years ago, with the help of an illustrator, I put together an infographic that reviews the different levels of smart contracts by example:
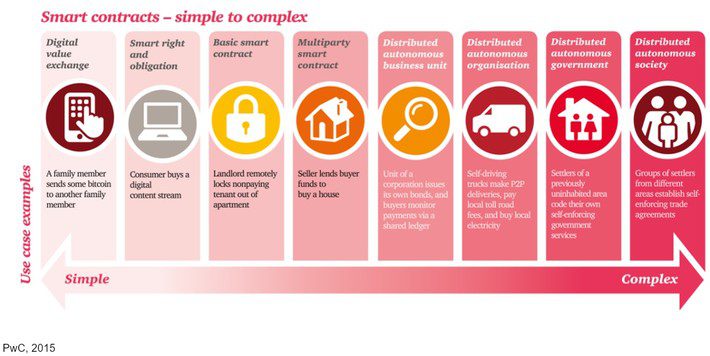
I realized once we put this infographic together that the vast majority of the smart contracts feasible then had to be unilateral, limited use and dead simple–otherwise, the risk of using them would be too great. Blockchains themselves might be tamperproof, but as Emeka points out, the code and data they store can often be questionable, because blockchains do suffer from the “garbage in, garbage out” problem in computing. Blockchains do not have the capability to verify data not generated on-chain.
Smart contract exploits in the Web3 era
Smart contracts have been known since they were proposed in the 1990s for the vulnerabilities they can open the doors to. Attackers who exploit these vulnerabilities can steal millions of dollars in digital coin. Even more havoc can result from security deficiencies in the tooling used to create smart contracts.
In a December 2021 example reported in Ars Technica, “An accounting error built into the company’s software [which is used to draft smart contracts] let an attacker inflate the price of the MONO token and to then use it to cash out all the other deposited tokens…” resulting in the theft of all the deposits held by the exchange in question.
In other cases, “agreement” code shared via a blockchain can masquerade as one kind of smart contract, but turn out in practice to be another. Smart contracts designed as honeypots attract users who are deceived into believing, for instance, that they can get even more funds back if they transfer a specified amount of funds via the smart contract. Instead, what happens is that the person being deceived can’t withdraw any funds at all, and the attacker keeps the whole pot, according to Cointelegraph in December 2021.
Smarter contracts by design
Some providers now claim the smart contracts they offer have been audited, but what does that really mean? The issues smart contract developers and users confront go well beyond the ability of one company and its designated third-party auditor to address.
How could you reduce these kinds of vulnerabilities and make the vulnerabilities that are still lurking harder to exploit? A few of different ways that come to mind include these:
Adhere to best practices and principles already developed by the Ethereum community. Consensys.io’s Best Practices site on Github, for example, provides helpful guidance that echoes the lessons learned over years of smart contract use.
Harness a broader open source security coalition by using the Linux Foundation’s Open Source Security Foundation and the principles and practices embodied in the Advanced Encryption Standard as a model.
Add the ability to disambiguate, logically abstract or otherwise tighten up the legal language of smart contracts by using semantic standards such as SKOS, OWL, and RDF (Resource Description Language) from bodies such as the W3C.
Build a data and logic governance knowledge graph designed to connect and work with blockchains to validate and verify Web3 provenance and best practices. Consultancies such as Enterprise Knowledge and Semantic Arts and providers including data.world, Fluree, Franz, OpenLink Software, Semantic Web Company and TopQuadrant are all helping enterprise clients catalog and model their data assets.
Why aren’t many smart contracts harnessing open source-style governance including knowledge graphs yet? Lack of awareness or willingness to explore new tech. It’s the pervasive “If all you have is a hammer, everything looks like a nail” problem.
Convergence, trivergence, quadvergence….?
Enterprise tech prognosticator Don Tapscott declared at the end of 2021 (just as he did in December 2020) that we’ll be experiencing a “trivergence” of blockchain, AI, and IoT over the coming decade. I’d only add that the coming convergence will be more all-encompassing than just what’s suggested by those three vague, overused terms.
Competitive advantage will hinge on all the technologies that contribute to data-centric architecture–turning current application-first architecture on its head so we can knit the data we need to share together, and harness the logic and contextualizing power of relationship data in the process. The long-term goal is to work together online in real time at scale with all the resources articulated at our fingertips, but without the complexity of application-centric architectures that create more and more data siloing and trapped code.
What’s the solution to bigger challenges than just smart contracts? Get all the tools you may need out on the worktable and learn enough about them to know if they’ll be helpful or not within the frame of data-centric or knowledge graph-based architecture. And then be diligent enough to find other tools that may help that you didn’t know about before. Doing so may seem overwhelming at first, but keep in mind that your most serious competition will be quite diligent.
What we could call “A-to-Z design” doesn’t just focus on one class of emerging data tech–it explores the synergies of numerous emerging technologies in use together. System-level design is another word for this approach–though these days, the focus is more on intersystem design.
{kind=link}