

What is Dataproc?
Dataproc is a low-cost, Google Cloud Platform integrated, easy to use managed Spark and Hadoop service that can be leveraged for batch processing, streaming, and machine learning use cases.
What is Google BigQuery?
BigQuery is an enterprise grade data warehouse that enables high-performance SQL queries using the processing power of Googles infrastructure.
Load Data Into Google BigQuery and AutoML
Use Case
In this blog, we will review ETL data pipeline in StreamSets Transformer, a Spark ETL engine, to ingest real-world data from Fire Department of New York (FDNY) stored in Google Cloud Storage (GCS), transform it, and store the curated data in Google BigQuery.
Once the transformed data is made available in Google BigQuery, it will be used in AutoML to train a machine learning model to predict the average incident response time for the FDNY.
Sample Data
The dataset is made available through the NYC Open Data website. The 2009-2018 historical dataset contains average response times of the FDNY. The data is partitioned by incident type (False Alarm, Medical Emergency, and so on), borough, and the number of incidents during a particular month.
Heres what the sample FDNY data looks like:
Data Pipeline Overview
Data Source And Dataset
- Data in CSV format is loaded from GCS using Google Cloud Storage (GCS) origin. To load data from GCS, all you need to provide is the path to the bucket, data format, and file name pattern.
Data Transformations
- Raw data is transformed using Filter, Field Remover, and Spark SQL Expression processors in a format that is suitable for machine learning. (See details below.)
Data Storage
- Transformed data is stored in a Google BigQuery table. Note: if the table doesnt already exist, it will be created automatically by StreamSets Transformer.
Cluster Type
- In this example, the data pipeline is designed to run on an existing or ephemeral Google Dataproc cluster. Note: Other supported cluster types in StreamSets Transformer include Databricks, Amazon EMR, Azure for HDInsight, Hadoop YARN, and SQL Server 2019 Big Data Cluster.
Data Pipeline Preview
Before running the Spark ETL pipeline in StreamSets Transformer, you can preview the pipeline against the configured Dataproc cluster to examine the data structure, data types, and verify the transformations at every stage. This is also a great way to debug data pipelines. For more information on pipeline preview, refer to the documentation.
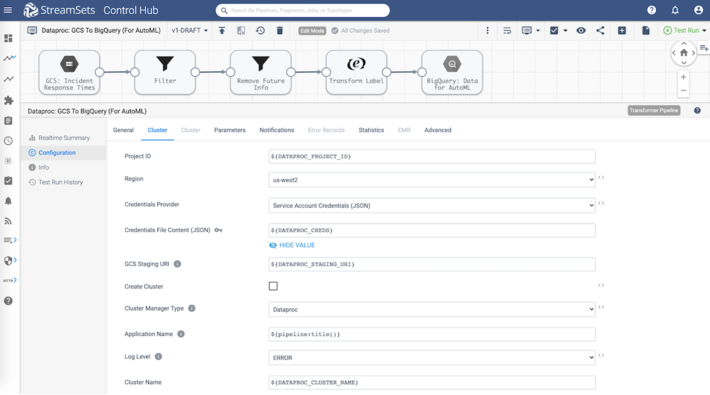
Filter
Using a Filter processor we will filter out incidents where INCIDENTCLASSIFICATION == All Fire/Emergency Incidents or INCIDENTBOROUGH == Citywide.
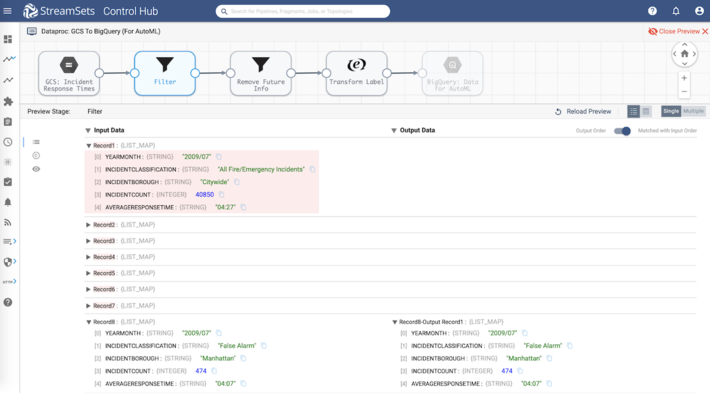
Remove Future Information
Because this is a historical dataset and were using it to train a machine learning model, we need to remove information that would not be known at the beginning of the month. In this case, that is INCIDENTCOUNT. To remove this field from every record, well use a Field Remover processor.
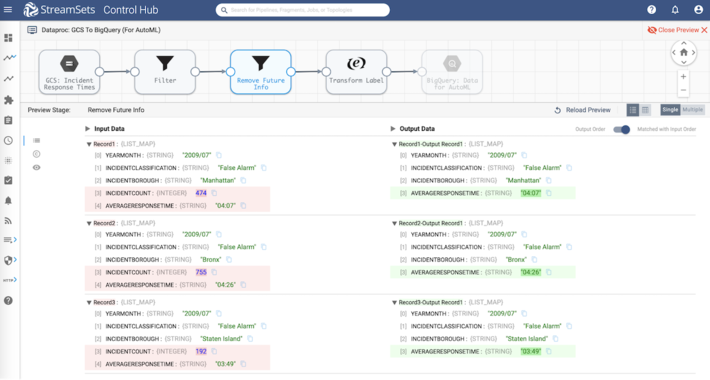
Data Transformations
Labels or target variables in machine learning models are of numeric data type. In this case, the field value of AVERAGERESPONSETIME is transformed in the following steps:
- Remove : using Spark SQL expression replace(AVERAGERESPONSETIME,:,)
- Convert from time to seconds and from string datatype to integer using Spark SQL expression round((AVERAGERESPONSETIME / 100) * 60 + (AVERAGERESPONSETIME % 100))
Data Pipeline Execution
Running the StreamSets Transformer data pipeline displays various metrics in real-time. For example, batch processing time taken by each stage as shown below. This is a great way to start looking into fine tuning the processing and transformations.
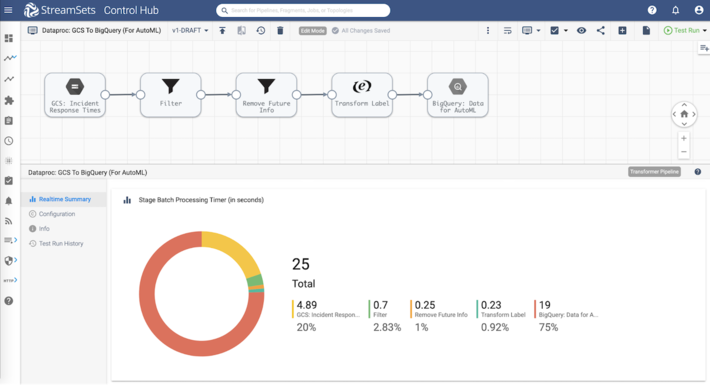
Google BigQuery
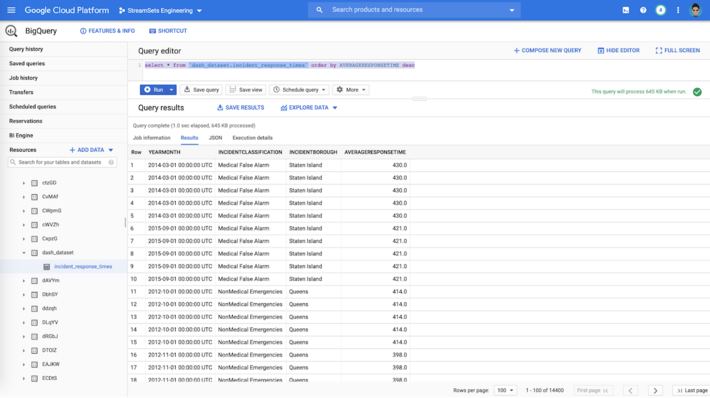
Once the pipeline runs successfully, the Google BigQuery table is auto-created, if it doesnt already exists, and the transformed data is inserted into the table. This dataset is then readily available for querying as shown below.
AutoML
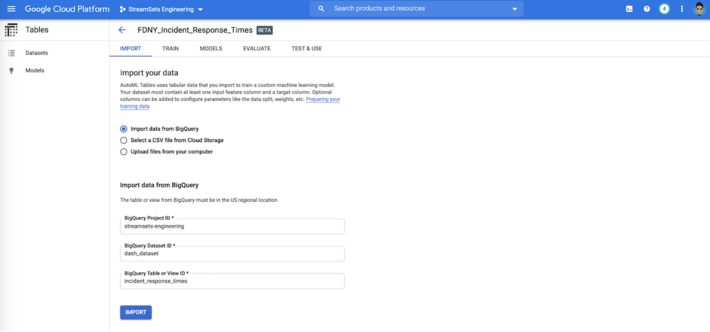
The transformed data stored can then be imported directly from the BigQuery table for training a machine learning model in AutoML.
Using AutoML you can build on Googles machine learning capabilities and create custom machine learning models.
Import Data
Select Target Column
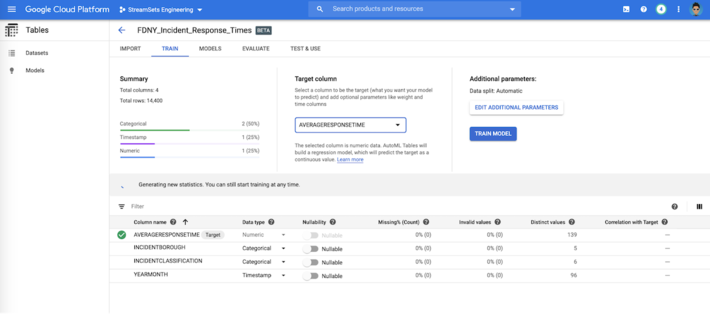
Train Machine Learning Model
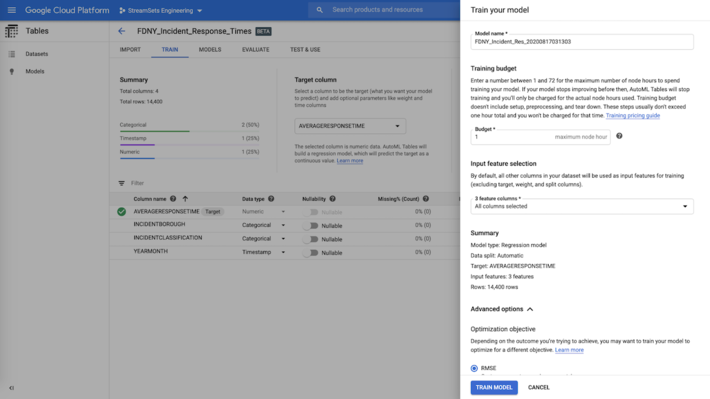
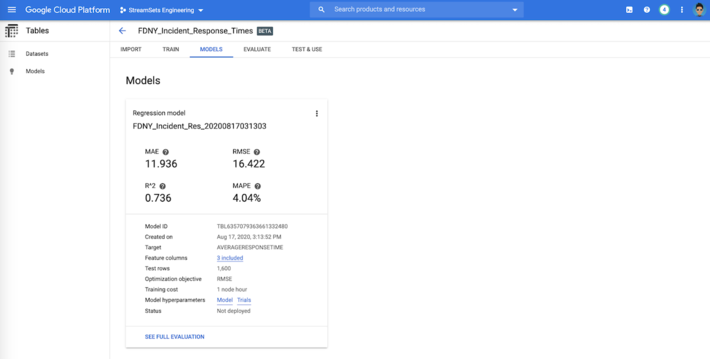
Thats it! We went from loading raw, real-world data into Google BigQuery to creating a machine learning model in AutoML without any coding or scripting!
Build Your Spark ETL and ML Data Pipelines
It goes without saying that training models, evaluating them, model versioning, and serving different versions of the model are non-trivial undertakings and that is not the focus of this post. That said, however, StreamSets Transformer makes it really easy to load data into Google BigQuery and AutoML.
Checkout these helpful resources and get started quickly with running your Spark ETL data pipelines.
Learn more about StreamSets For Google Cloud Platform.
{kind=link}