
Source: see last section in this article
During the October 4, 2021 great Facebook outage, which lasted for over 6 hours, making all FB properties (including Instagram, Snapshot, and even internal tools employees at FB use to communicate between themselves or even to enter the building) were down. Twitter’s co-founder seemed so happy, and another big winner was DownDetector.com, which for several hours acted as a substitute to FB, with dozens of thousands users expressing their opinions about this outage, sometimes based on conspiracy theories. It is not the first (or last) time that this is happening, and this is not the worst event either for FB. It is blamed on a DNS change that went wrong, not on internal sabotage by a FB employee, nor on external hijacking. And I really believe that this is the case. Probably, nobody was fired at FB because of this massive outage causing a lot of financial losses. Instead, most likely, some FB employees were very well rewarded for fixing the issue and restoring the service, which required being physically present next to the servers that virtually but not physically went “missing” (unreachable, disconnected) from the Internet.
One issue FB faced was that their domain registry company is registrarsafe.com also known as registrarsec.com. A quick check on Godaddy will confirm this, and it will also confirm that it is owned by FB. Sorry for the numerous people who thought they could buy the domain name Facebook.com for $99 – good try, but it would have been impossible. These two domain name registrars were also down the whole time yesterday. Now I have had similar issues myself with the DNS records for my website, completely gone. But because the registrar companies were external to my company, I could call them and get the issue resolved within minutes, especially if you have a good relationship with them. In the case of FB, it probably was like calling your own registrar company, and hearing that they suddenly went off-the-grid in some kind of “snake eating its tail” effect. This is a much more challenging problem, still solvable (as you can switch to another registrar, though it can take some time). This may explain why it took so long to fix, especially since FB wants to keep its registrar internally.
I believe it is possible to have your domain name recorded by two different registrars (say one internal, one external to your company) and maybe this would have helped fix the issue faster. I also think that knowing the actual IP address of your domain names would be of great help to resolve the issue faster. But if nobody at FB knew the IP addresses in question, maybe because it was stored on a server that got off-the-grid, then it becomes a more difficult problem. Actually there are many such IP’s leading to the actual server even if the domain name is gone: try entering 157.240.3.35 or 31.13.71.36 on your browser, it will lead directly to FB even if the domain name Facebook.com is not attached anymore to these IP’s because it was erased. Of course these IP’s may change over time, but the two ones I mentioned here have been working at least for several hours. This brings me to the main part of this article: how to protect your company the best you can against these types of accidents.
Similar nightmarish problems you could face
Here I am listing some that I have experienced, and how to minimize the risks.
- I am used to have my laptops die after several years of good service, indeed I am happy to have survived all of them, and it usually takes me less than 30 minutes to be operational again on a new laptop. The reason being that I store everything on the cloud, even my email is hosted externally, not locally. My laptop is just a gateway to access what I need, but not used for storage. But I have dozens of login/password needed to start again from scratch. The last time my laptop crashed, I could not find my list of encrypted login/passwords, as the list itself contained the login/password required to access the place where it was located on the cloud. Typically, I store this meta login/password on a piece of paper attached to my (dead) laptop, but this time I could not find that piece of paper. It took me a day to retrieve it. In some sense, this is not much different from what FB experienced – they did not have that piece of paper, with the relevant information, that could have saved them.
- We use Cloudflare as a cache mechanism when our website is down. While it does not store all the pages and it crawls our website probably only once a day thus missing the most recent content, it has been very useful when our servers were down. Of course, it won’t work if your DNS record is erased, which is what FB experienced.
- A classic issue many of us experienced: typing in too fast some dangerous UNIX command, which erases everything on your local drive. When it happened to me, I was lucky that the IT department at my university had a backup copy recently updated in the last 24 hours. As the saying goes, if a cup of coffee does not wake you up in the morning, try erasing all your databases at once with one simple command!
- Other potential problems: what if your CTO ends up in an hospital for a long time? What if your CEO dies in a car crash? (this happened to our former competitor SmartDataCollective.) One way to mitigate this risk is having people in your company who can take over these responsibilities, and trained for that, before the worst happens. Or what if the platform that hosts all your content (say WordPress) goes bankrupt? You need to back up everything regularly. It almost happened to us, and it was a big wake-up call. You need to be prepared: if that happens, everything (in the back-up copy) will be moved to another platform; be aware not to miss any important content (videos, images, attached files, member profile pages, forum questions, comments), make sure all former URL’s will still be live thanks to a sound redirect mechanism, and be aware that all your users will have to create new login/password for their new account, even if no data is lost. Your mailing list should be handled by a separate vendor, or stored somewhere and exported to the new platform.
- Sometimes a credit card expired, and nobody gets notified. One day you access your website, and suddenly it is gone. It happened to me, and this is why my personal blog is now vgranville.com, instead of the old vincentgranville.com. There is no way back in such a case, though litigation can help if the domain name in question has some value. Or you can buy it back when the stolen one expires. To avoid these problems, track all your credit cards and their expiration dates.
- Mergers and acquisitions can cause problems. When NBCi acquired some property from CNET.com, I moved to the new company. One day, as I was running the same old CNET Perl script against some live databases as part of my job, working remotely from home 3000 miles away, I quickly got a phone call from a sysadmin at NBCi, thinking I was a hacker. I explained the situation and it did no cause any problem. But the new company learned a lesson: change login/passwords in any critical system after acquisition, just as a landlord would change the lock when she gets a new tenant. I was then told to never use any legacy code ever again; the one that I used had the login/password embedded into it to access live databases, and it hadn’t been changed in a long time; and the new company was still relying on the same old databases with the same access privileges.
Reconstructing the topology of the Internet
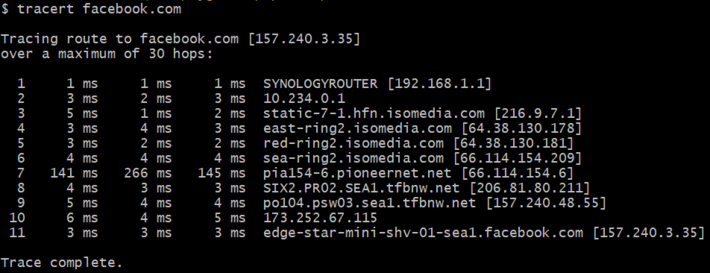
During the FB outage, I spent some time playing with a few tools, to figure out what happened. I went to WayBackMachine and found out how FB looked like in prehistoric times (back then, AboutFace) when it was first archived, Dec 12, 1998, even before it became FB in 2004. I played with Unix commands on my Windows laptop (using the Cygwin environment). One of them, tracert (a shortcut for traceroute, also available online, here) clearly showed that the domain name Facebook.com (as well as its registrar) was no longer stored in DNS tables.
Here I propose an exercise for data scientist beginners. Use the tracert UNIX command to find the path between your location (your ISP) and any target website, hopping from one Internet node to another until reaching final destination, for the top one million websites. Lists of top websites can easily be found on the web. The picture at the top of this article shows the path between my ISP and Facebook. Getting this data takes time (a few seconds), so you need a distributed architecture. And it will show the path to any website, but only from your location. If you want to see the path from many locations to many websites, you need a distributed architecture relying on servers spread all over the world. The way Internet connections are done, is by solving a huge graph theory problem, like Google navigation providing the best route between any two locations worldwide. In short, it consists in finding the quickest path in real time. Note that the optimum route, in both cases, change over time. You can also easily detect bottlenecks.
To receive a weekly digest of our new articles, subscribe to our newsletter, here.
About the author: Vincent Granville is a data science pioneer, mathematician, book author (Wiley), patent owner, former post-doc at Cambridge University, former VC-funded executive, with 20+ years of corporate experience including CNET, NBC, Visa, Wells Fargo, Microsoft, eBay. Vincent is also self-publisher at DataShaping.com, and founded and co-founded a few start-ups, including one with a successful exit (Data Science Central acquired by Tech Target). You can access Vincent’s articles and books, here. A selection of the most recent ones can be found on vgranville.com.
{kind=link}