
Money on the Table..MOTT. When I was the Vice President of Advertiser Analytics at Yahoo, this became a key focus guiding the analytics that we were delivering to advertisers to help them optimize their spend across the Yahoo ad network. Advertisers had significant untapped advertising and marketing spend into which we were not tapping because we could not deliver audience, content and campaign insights to help them spend that money with us. And the MOTT was huge.
Now here I am again, and I’m again noticing this massive “Money on the Table” (MOTT) economic opportunity across all companies – orphaned analytics. Orphaned Analytics are one-off analytics developed to address a specific use case but never “operationalized” or packaged for re-use across other organizational use cases. As I described in my blog “How to Avoid “Orphaned Analytics”:
“Organizations lack an overarching framework to ensure that the resulting analytics and associated organizational intellectual capital can be captured and re-used across multiple use cases. Without this over-arching analytics framework, organizations end up playing a game of analytics “whack-a-mole” where the analytics team focuses their precious and valuable resources on those immediate (urgent) problems, short-changing the larger, more strategic (important) analytic opportunities.”
Surprisingly, our University of San Francisco research on Economic Value of Data found that this problem mostly exists in analytics-mature organizations because it is just easier to build the analytics from scratch then to go through the process of searching, finding, understanding, evaluating and tailoring existing analytics for the unique requirements of each particular use case. These companies are so deep with data science and analytics talent, that it’s just easier to create analytics from scratch then trying to re-use something someone else created (and probably didn’t document, package or generalize for the purposes of re-use).
But the inability to re-use one’s analytics over and over again is a massive missed economic opportunity. And in this overly-long blog (so, what else is new), I’m going to argue that for organizations to succeed in the 21stcentury, they must invest the time and patience to master the economics of composable, reusable analytic modules.
Building Composable, Reusable Analytic Modules
In my blog “Driving AI Revolution with Pre-build Analytic Modules”, I proposed an overarching analytic module framework to help organizations to capture, share, and re-use the organization’s analytic IP in the form of analytic modules (see Figure 1).
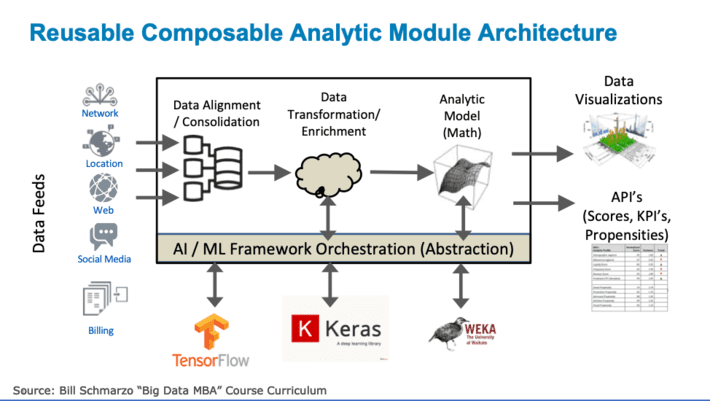
As I described in the blog, these composable, reusable Analytic Modules would have the following characteristics:
- pre-defined data input definitions and data dictionary (so it knows what type of data it is ingesting, regardless of the origin of the source system).
- pre-defined data integration and transformation algorithms to cleanse, align and normalize the data.
- pre-defined data enrichment algorithms to create higher-order metrics (e.g., reach, frequency, recency, indices, scores) necessitated by the analytic model.
- algorithmic models (built using advanced analytics such as predictive analytics, machine learning or deep learning) that takes the transformed and enriched data, runs the algorithmic model and generates the desired outputs.
- layer of abstraction above the Predictive Analytics, Machine Learning and Deep Learning frameworks that allows application developers to pick/use their preferred or company mandated standards.
- orchestration capability to “call” the most appropriate machine learning or deep learning framework based upon the type of problem being addressed.
- pre-defined outputs (API’s) that feeds the analytic results to the downstream operational systems (e.g., operational dashboards, manufacturing, procurement, marketing, sales, support, services, finance).
Analytic Modules produce pre-defined analytic outcomes, while providing a layer of abstract that enables the orchestration and optimization of the underlying machine learning and deep learning frameworks.
The Economics of Composable, Reusable Analytic Modules
Composable, reusable Analytic Modules can be created for the most common analytic needs (such as Anomaly Detection, Remaining Useful Life, Operator Effectiveness, Likelihood to Recommend, Predictive Customer Lifetime Value) that can be linked together using technologies such as Docker containers and Kubernetes, like Lego blocks…okay, maybe like Lego blocks with some Play-Doh, to address higher-value business and operational use cases (such as reducing operational downtime, improving on-time delivery, reducing obsolete and excessive inventory, improving customer retention, and reducing unplanned hospital readmissions).
These composable, reusable analytic modules give rise to the three economic effects that define the “Schmarzo Economic Digital Asset Valuation Theorem” (see Figure 2).
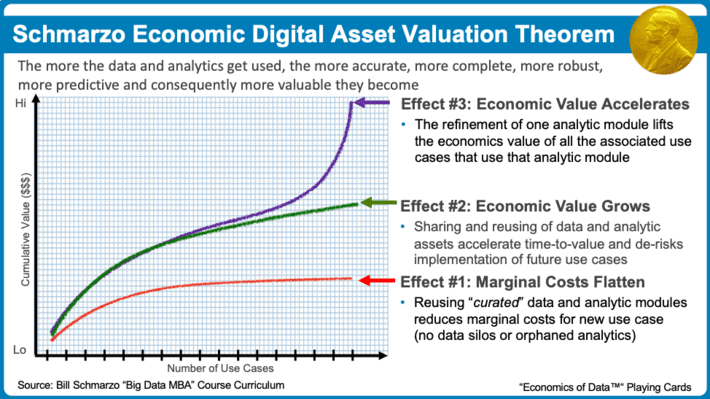
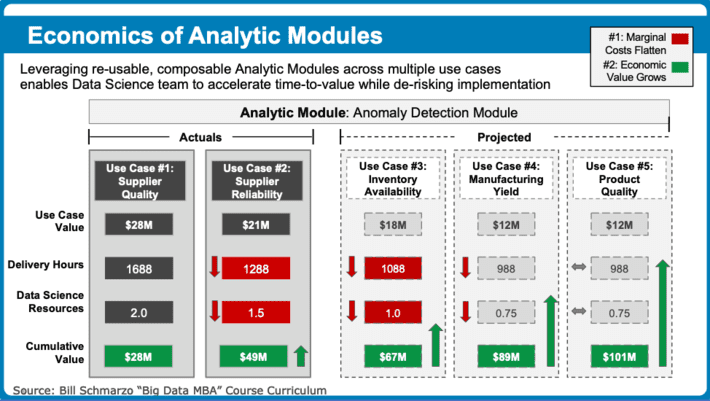
Okay, so I’ve been talking about these three effects enabled by the economics of digital assets like data and analytics in several blogs and countless customer, student and industry presentations. And now I am proud to state that we at Hitachi Vantara are starting to experience the ramifications of Effect #1 (marginal costs flatten through the reuse of the data and analytics) and Effect #2 (economic value grows by accelerating time-to-value and reducing implementation risk) through the reuse of composable, reusable Analytic Modules in our customer engagements (special thanks to Matt Colon for Figure 3).
However, we know that Effect #3 is the economic game-changer. Effect #3 creates assets that appreciate, not depreciate, in value through the continued use of those analytic modules. These analytic assets appreciate in value as a result of the collective knowledge / wisdom / intelligence gleaned from the operations of those analytic modules across a wide variety of use cases; that what is learned from a use case, is validated, codified and propagated back to every other analytic module (see Figure 4).
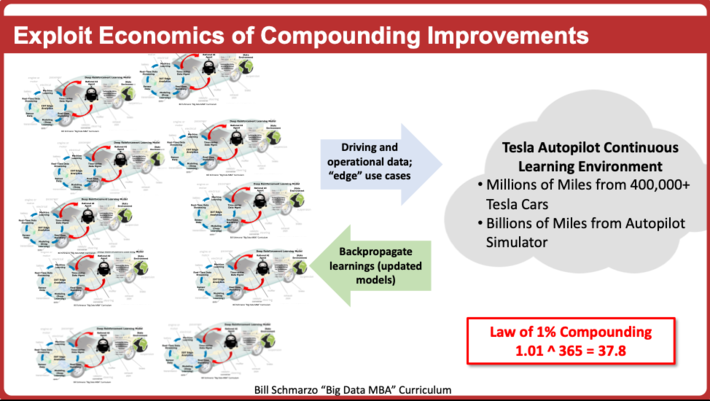
And continued advancements in AI learning techniques such as Transfer Learning and Federated Learning are paving the way to the realization of Effect #3. Let’s dive into those two topics.
Importance of AI-based Learning
In the blog “Executive Mandate#1: Become Value Driven, Not Data Driven”, I first discussed the role of Transfer Learning in helping organizations to derive and drive new sources of customer, product and operational value. Transfer Learning is a technique whereby a neural network is first trained on one type of problem and then the neural network model is reapplied to another, similar problem with only minimal training (see Figure 5).
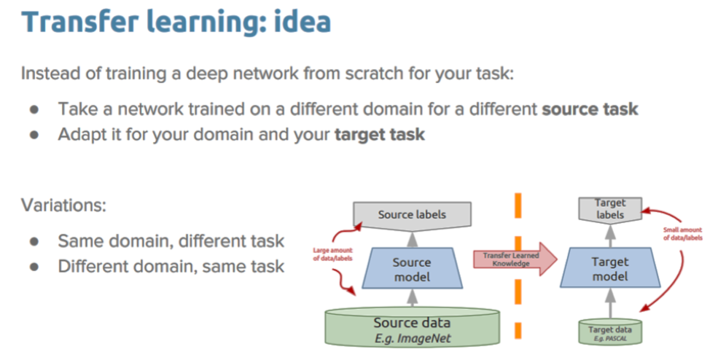
Transfer learning re-applies the Neural Network knowledge (weights and biases) gained while solving one problem and applying that knowledge to a different but related problem with minimal re-training. For example, knowledge gained while learning to recognize cars could apply when trying to recognize trucks or tanks or trains.
While Transfer Learning works great when the data and processing power is centralized into a cloud environment, it has severe limitations when dealing in mobile and IoT environments with a multitude of remote nodes where time and distance challenges impact the data movement and processing speeds necessary for near real-time learning and adaption. Welcome to Federated Learning!
Google Research has developed the Federated Learning concept to support their extensive mobile device network, but one can quickly imagine the ramifications for autonomous entities comprised of hundreds or thousands of individual devices in a traditional Internet of Things (IoT environment). The Federated Learning model works like this:
Your remote device downloads the current analytic model, improves it by learning from data on the remote device, and then summarizes the changes as a small focused update. Only this update to the analytic model is sent to the cloud where it is aggregated and shared with other user updates to improve the analytic model. All the training data remains on your remote device[1].
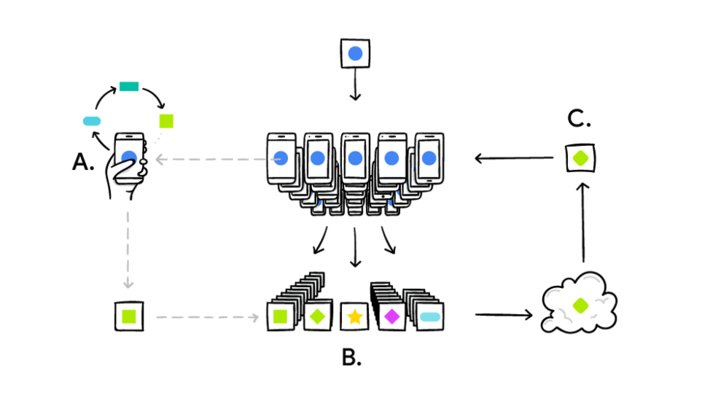
While Google’s work to-date on Federated Learning has been mostly focused on supporting their massive network of smart phones (which has the advantage of significant amounts of storage and compute power), one can quickly imagine that this sort of Federated Training capability will be adopted by IoT vendors who are looking to improve the learning and adapting that is happening at the edges of IoT networks (which will soon have significant amounts of storage and compute power). Heck, if I can imagine it, then anyone can imagine it!
Summary: Composable, Reusable Analytic Modules
Transfer Learning and Federated Learning will be key to the realization of Effect #3 of the Schmarzo Digital Asset Economic Valuation Theorem: that the refinement of analytic modules lifts the economic value of all associated use cases using that same analytic model.
Transfer Learning and Federated Learning will accelerate the ability for Analytic Modules to learn across multiple deployments and propagate those learnings back to the network of devices that are sharing that same Analytic Module. Effect #3 underpins the concept that we can create AI-based assets that appreciate, not depreciate, in value the more they assets are used. And when industrial companies can master that phenomena, it is truly a game changer.
But effect #3 requires that organizations think differently about their analytics; not as one-off projects, but as assets that appreciate in value the more that they are used.
Otherwise, you are leaving lots of money on the table (MOTT) for your competitors to sweep up. And that’s a fact, Jack!
{kind=link}