
Summary: There have been several stories over the last several months around the theme that AI is about to hit a wall. That the rapid improvements we’ve experienced and the benefits we’ve accrued can’t continue at the current pace. It’s worth taking a look at these arguments to see if we should be adjusting our plans and expectations.
 There have been several stories over the last several months around the theme that AI is about to hit a wall. That the rapid improvements we’ve experienced and the benefits we’ve accrued can’t continue at the current pace. It’s worth taking a look at these arguments to see if we should be adjusting our plans and expectations.
There have been several stories over the last several months around the theme that AI is about to hit a wall. That the rapid improvements we’ve experienced and the benefits we’ve accrued can’t continue at the current pace. It’s worth taking a look at these arguments to see if we should be adjusting our plans and expectations.
These concerns center around two issues:
- The over concentration of investment in AI in just a few cities and how will that impact growth.
- The amount of compute required for our most advanced applications appears to be rising seven times faster than before implying some limit on the cost/benefit to pursuing the most compute-hungry advances.
Over Concentrated Investment
It’s certainly true that investment in AI is extremely concentrated in just a few cities. This chart from the National Venture Capital Association shows that over 80% of investment went to just six metros. By the way, there’s a sharp break in the distribution below this level with the next best metro receiving only 2.4% of total investment (Chicago).
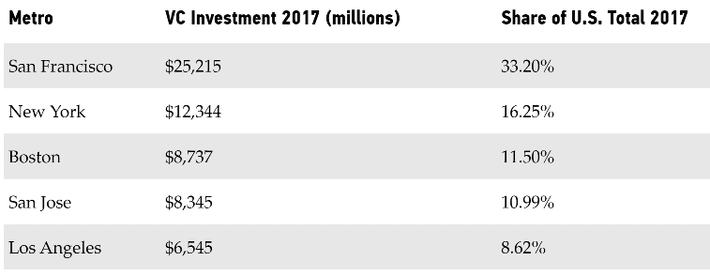
So what’s the concern? The folks who have written about this see this as an over concentration of talent that increases labor costs in these areas making some types on new AI investment uneconomic.
It seems true that the concentration of AI talent in say San Francisco leads to the most new ideas in AI being generated there. But is this really a black hole with gravity so extreme that good ideas can’t escape to be executed elsewhere?
Worriers about this concentration see these good ideas escaping to overseas low cost locations. I’m not so sure.
There is a pattern that the largest concentration of VC funded AI startups and established AI companies will draw in the most volume of new talent at the bottom. New graduates and young people will naturally gravitate to metros where there are the most opportunities.
Personally I think this concern overlooks that as these metros become more dense with opportunity they also become massively more expensive to live in and that the quality of life drops off quickly (San Francisco, I’m looking at you).
As young professionals gain experience and also reach the life stage where they want to marry, buy homes, and start families they will naturally migrate to less expensive geographies. This may mean they will gravitate to the outskirts of these metros with lower cost of living where AI businesses will naturally follow to capture talent. It may also mean a willingness to relocate over longer distances to good quality of life locations like Austin, Seattle, Washington, Atlanta, or Miami where investment will follow talent.
Growth in Training Compute for the Most Advanced Applications is Now Growing 7X Faster than Before
This area of concern was first raised by the AI research lab OpenAI in 2018 and recently updated with new data. Their findings are that the amount of computational power needed to train the largest AI models has doubled every 3.4 months since 2012.
They see history divided into two distinct eras with the new era beginning in 2012 now growing 7X faster than the previous era.
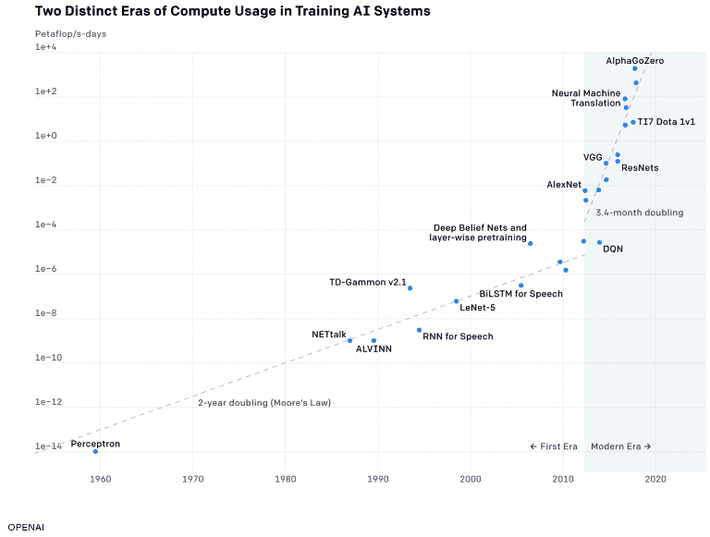
This phenomenon has led some leading industry experts including Jerome Pesenti, the VP of Artificial Intelligence at Facebook to observe in a recent Wired article that there may be cost/benefit limits to what can be accomplished at the extreme limits of improving AI models.
Pesenti says that while scaling up is a worthwhile solution to the most difficult challenges like deep fake image detection and AI moderation of fake news and online abuse that the rate of progress is not sustainable.
“If you look at top experiments, each year the cost is going up 10-fold. Right now, an experiment might be in seven figures, but it’s not going to go to nine or ten figures, it’s not possible, nobody can afford that. It means that at some point we’re going to hit the wall. In many ways we already have.”
Other advancements that are at risk would be many of the ‘next big things’ in AI including cutting edge applications that require increased look forwards or look backs to properly classify. These would include many navigation apps in next gen computer vision, and contextually intelligent NLP assistants that can relate our schedules and actions to outside events.
While I wouldn’t want to have to do without these improvements, it’s interesting what’s been included in the OpenAI chart. For example, the most compute-hungry model is actually a reinforcement learning game playing app AlphaGoZero. Personally I’d like to see research continue in Deep Learning RL models but the commercial applications are not as compelling as say BERT, the new NLP language encoder from Google.
Another issue to keep in mind is that this is an issue that impacts incremental gains in existing capabilities. Pesenti is right to wonder aloud if it isn’t time to apply cost/benefit criteria to these. This so-called wall does not prevent us in any way from continuing the rapid application of existing AI/ML capabilities in business and harvesting the benefits currently underway.
In a sense this is the flying-car syndrome. We’ve come so far so fast that if we don’t get deep fake detection or fake news automatic moderation right away we’ll wonder where’s our flying car.
It’s also worth noting that lots of research is being conducted in how to make the training process more efficient. For example, just last week researchers at Rice University announced the results of their new MACH technique (Merged Average Classifiers via Hashing). They report “training times about 7-10 times faster, and …memory footprints are 2-4 times smaller’ than previous large-scale deep learning techniques.
As for these walls, fortunately smart folks are working on both ends of this problem. We may need to bring some cost/benefit discipline to our research but if the market need is there, my bet is that we’ll find a way.
Other articles by Bill Vorhies
About the author: Bill is Contributing Editor for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. His articles have been read more than 2 million times.
He can be reached at:
{kind=link}