
Summary: In this Lesson 3 we continue to provide a complete foundation and broad understanding of the technical issues surrounding an IoT or streaming system so that the reader can make intelligent decisions and ask informed questions when planning their IoT system.
|
In Lesson 1 |
In Lesson 2 |
In This Article |
|
Is it IoT or Streaming |
Stream Processing – Open Source |
Three Data Handling Paradigms – Spark versus Storm |
|
Basics of IoT Architecture – Open Source |
What Can Stream Processors Do |
Streaming and Real Time Analytics |
|
Data Capture – Open Source with Options |
Open Source Options for Stream Processors |
Beyond Open Source for Streaming |
|
Storage – Open Source with Options |
Spark Streaming and Storm |
Competitors to Consider |
|
Query – Open Source Open Source with Options |
Lambda Architecture – Speed plus Safety |
Trends to Watch |
|
|
Do You Really Need a Stream Processor |
|
|
|
Four Applications of Sensor Data |
|
Continuing from Lesson 2, our intent is to provide a broad foundation for folks who are starting to think about streaming and IoT. In this lesson we’ll explain how Spark and Storm handle data streams differently, discuss what real time analytics actually means, offer some alternatives for streaming beyond open source, and suggest some trends you should watch in this fast evolving space.
Three Data Handling Paradigms: SPARK Versus Storm
When users compare SPARK versus Storm the conversation usually focuses on the difference in the way they handle the incoming data stream.
- Storm processes incoming data one event at a time – called Atomic processing.
- SPARK processes incoming data in very small batches – called Micro Batch. A SPARK micro batch is typically between ½ second and 10 seconds depending on how often the sensors are transmitting. You can define this value.
- A third method called Windowing allows for much longer windows of time and can be useful in some text or sentiment analysis applications, or systems in which signals only evolve over a relatively long period of time.
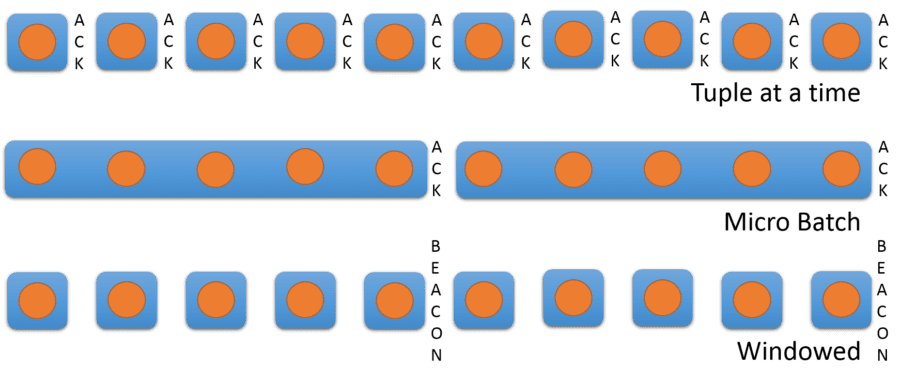
Atomic: (aka one-tuple-at-a-time) Processes each inbound data event as a separate element. This is the most intuitively obvious but also the most computationally expensive design. For example, it’s used to guarantee fastest processing of individual events with least delay in transmitting the event to the subscriber. Seen often for customer transactional inputs so that if some element of the event block fails the entire block is not deleted but moved to a bad record file that can later be processed further. Apache Storm uses this paradigm.
Micro batching: The critique of this approach is that it processes in batches (not atomic level streaming) but typically those batches are extremely small encompassing actions that occur within only a few seconds. You can adjust the time window. This makes the process somewhat more efficient. SPARK Streaming uses this paradigm.
Windowing: A hybrid of the two approaches, Windowing maintains the atomic processing of each data item but creates pseudo-batches (windows) to make processing more efficient. This also allows for many more sophisticated interpretations such as sliding windows (e.g. everything that occurred in the last X period of time).
All three of these approaches can guarantee that each data element is processed at least once. Only the Atomic paradigm can guarantee that each data element is processed only once.
Consider this Example
Your sensors are like FitBits and sample data every 10 seconds. They transmit that in bursts whenever the sensor is cued to dump its data into a Wi-Fi stream. One user may monitor the results of the stream many times during the day, valuing low latency and causing his sensor to upload via Wi-Fi frequently. Another user may not be near a Wi-Fi connection or may simply not bother to download the data for several days. Still a third user may have trouble with a network connection or the hardware itself that causes the sensor to transmit incomplete or missing packets that are then repeated later or are simply missing from the stream.
In this scenario, data from sensors originating at the same time may arrive at the stream processor with widely different delays and some of those packets that were disrupted may have been transmitted more than once or not at all.
You will need to carefully evaluate whether guaranteeing ‘only once’ processing, or the marginally faster response time of atomic processing warrant using this factor in your selection of the Stream Processor.
Streaming and Real Time Analytics
It’s common in IoT to find references to “real time analytics” or “in stream analytics” and these terms can be misleading. Real time analytics does not mean discovering wholly new patterns in the data in real time while it is streaming by. What it means is that previously developed predictive models that were deployed into the Stream Processor can score the streaming data and determine whether that signal is present, in real time.
It’s important to remember that the data science behind your sophisticated Stream Processor was developed in the classic two step data science process. First data scientists worked in batch with historical data with a known outcome (supervised learning) to develop an algorithm that uses the inputs to predict the likelihood of the targeted event. The model, an algebraic formula, represented by a few lines of code (C, Python, Java, R, and others) is then exported into a program within the Stream Processor and goes to work evaluating the passing data to see if the signal is present. If it is, some form of action alert is sent to the human or machine, or sent as a visual signal to a dashboard.
Recently the first indications that some new discoveries can be made in real time have been emerging but they are exceedingly rare. See more in this article.
Beyond Open Source for Streaming
Why would you want to look beyond open source for your IoT system? Largely because while open source tools and packages are practically free, this is the same as ‘free puppy’.
Yes these packages can be downloaded for free from Apache but the most reasonable sources are the three primary distributors, Hortonworks, Cloudera, and MapR all of whom make sure the code is kept up to date and add certain features that make it easier to maintain. Even from these distributors, your total investment should be in the low five figures. This does not of course include implementation, consulting, or configuration support which is extra, either from the distributors, from other consultants, or from your own staff if they are qualified.
With open source what you also get is complexity. Author Jim Scott writing about SPARK summed it up quite nicely. “SPARK is like a fighter jet that you have to build yourself. The great thing about that is that after you are done building it, you have a fighter jet. Problem is, have you ever flown a fighter jet? There are more levers than could be imagined.”
In IT parlance, the configurations and initial programs you create in SPARK or other open source streaming platforms will be brittle. That is every time your business rules change you will have to modify the SPARK code written in Scala, though Python is also available.
Similarly, standing up a SPARK or Hadoop storage cluster comes with programming and DBA overhead that you may not want to incur, or at least to minimize. Using one of the major cloud providers and/or adding a SaaS service like Qubole will greatly reduce your labor with only a little incremental cost.
The same is true for the proprietary Stream Processors many of which are offered by major companies and are well tested and supported. Many of these come with drag-and-drop visual interfaces eliminating the need for manual coding so that any reasonably dedicated programmer or analyst can configure and maintain the internal logic as your business changes. (Keep your eye on NiFi, the new open source platform that also claims drag-and-drop).
Competitors to Consider
Forrester publishes a periodic rating and ranking of the competitor “Big Data Streaming Analytic Platforms” and as of the spring of 2016 listed 15 worthy of consideration.
Here are the seven Forrester regards as leaders in rank order:
- IBM
- Software AG
- SAP
- TIBCO Software
- Oracle
- DataTorrent,
- SQLstream
There are eight additional ‘strong performers’ in rank order:
- Impetus Technologies
- SAS
- Striim
- Informatica
- WSO2
- Cisco Systems
- data Artisans
- EsperTech
Note that the ranking does not include the cloud-only offerings which should certainly be included in any competitive comparison:
- Amazon Web Services’ Elastic MapReduce
- Google Cloud Dataflow
- Microsoft Azure Stream Analytics
Here’s the ranking chart:
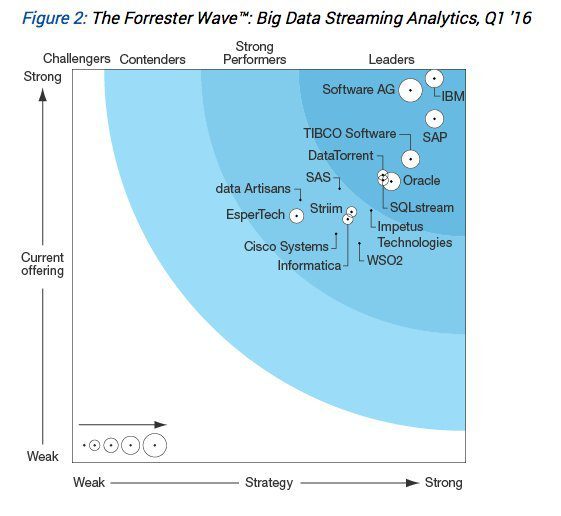
It’s likely that you can get a copy of the full report from one of these competitors. Be sure to pay attention to the detail. For example here are some interesting observations from the numerical scoring table.
Stream Handling: In this presumably core capability SoftwareAG got a perfect score while Impetus and WSO2 scored decidedly below average.
Stream Operators (Programs): Another presumably core capability. IBM Streams was given a perfect score. Most other competitors had scores near 4.0 (out of 5.0) except for data Artisans given a noticeably weak score.
Implementation Support: data Artisans and EsperTech were decidedly weaker than others.
In all there are 12 scoring categories that you’ll want to examine closely.
What these 15 leaders and 3 cloud offerings have in common is that they greatly simplify the programming and configuration and hide the gory details. That’s a value well worth considering.
Trends to Watch
IoT and streaming is a fast growth area with a high rate of change. Witness the ascendance of SPARK in just the last year to become the go-to open source solution. All of this development reflects the market demand for more and more tools and platforms to address the exploding market for data-in-motion applications.
All of this means you will need to keep your research up to date during your design and selection period. However, don’t let the rate of change deter you from getting started.
- One direction of growth will be the further refinement of SPARK to become a single platform capable of all four architectural elements: data capture, stream processing, storage, and query.
- We would expect many of the proprietary solutions to stake this claim also.
- When this is proven reliable you can abandon the separate components required by the Lambda architecture.
- We expect SPARK to move in the direction of simplifying set up and maintenance which is the same ground the proprietary solutions are claiming. Watch particularly for integration of NiFi into SPARK, or at least the drag-and-drop interface elements creating a much friendlier UI.
About the author: Bill Vorhies is Editorial Director for Data Science Central and has practiced as a data scientist and commercial predictive modeler since 2001. He can be reached at:
{kind=link}